TensorFlow 二元分类:线性分类器示例
两种最常见的监督学习任务是线性回归和线性分类器。线性回归预测一个值,而线性分类器预测一个类别。本教程将重点介绍线性分类器。
什么是线性分类器?
机器学习中的线性分类器是一种根据对象的特征进行统计分类以查找对象类别的方法。它基于对象的特征的线性组合的值来做出分类决策。线性分类器用于文档分类和具有许多变量的问题等实际问题。
分类问题约占机器学习任务的 80%。分类旨在在给定一组输入的情况下预测每个类的概率。标签(即因变量)是一个离散值,称为类。
- 如果标签只有两个类,则学习算法是二元分类器。
- 多类分类器处理超过两个类的标签。
例如,典型的二元分类问题是预测客户进行第二次购买的可能性。预测图片中显示的动物类型是多类分类问题,因为存在两种以上的动物种类。
本教程的理论部分主要关注二元分类。您将在未来的教程中了解更多关于多类输出函数的信息。
二元分类器如何工作?
您在上一教程中了解到,函数由两类变量组成:因变量和一组特征(自变量)。在线性回归中,因变量是没有任何范围的实数。主要目标是通过最小化均方误差来预测其值。
对于 TensorFlow 二元分类器,标签可以具有两个可能的整数值。在大多数情况下,它是 [0,1] 或 [1,2]。例如,目标是预测客户是否会购买产品。标签定义如下
- Y = 1(客户购买了产品)
- Y = 0(客户未购买产品)
模型使用特征 X 将每个客户分类到最有可能所属的类别,即潜在买家或非潜在买家。
成功概率使用逻辑回归计算。该算法将根据特征 X 计算概率,并在概率高于 50% 时预测成功。更正式地说,概率计算如下面的 TensorFlow 二元分类示例所示
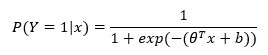
其中 0 是权重集、特征和偏差 b。
该函数可分解为两部分
- 线性模型
- Logistic 函数
线性模型
您已经熟悉了权重计算的方式。权重是通过点积计算的:![]() Y 是所有特征 xi 的线性函数。如果模型没有特征,则预测等于偏差 b。
Y 是所有特征 xi 的线性函数。如果模型没有特征,则预测等于偏差 b。
权重表示特征 xi 和标签 y 之间相关性的方向。正相关会增加正类的概率,而负相关会将概率拉近到 0(即负类)。
线性模型仅返回实数,这与范围 [0,1] 的概率度量不一致。需要 Logistic 函数将线性模型的输出转换为概率,
Logistic函数
Logistic 函数或 sigmoid 函数呈 S 形,该函数的输出始终在 0 和 1 之间。
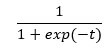
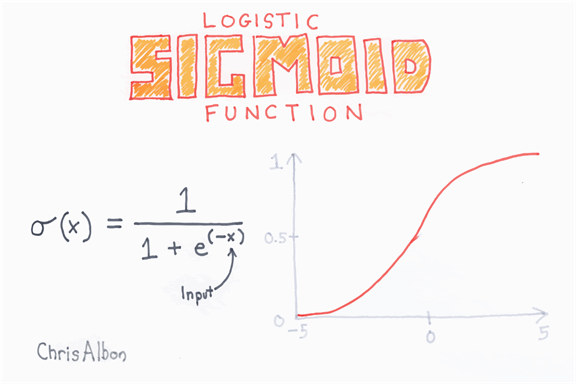
将线性回归的输出替换为 sigmoid 函数很容易。这将得到一个介于 0 和 1 之间的新数字,表示概率。
分类器可以将概率转换为类别
- 0 到 0.49 之间的值变为类别 0
- 0.5 到 1 之间的值变为类别 1
如何衡量线性分类器的性能?
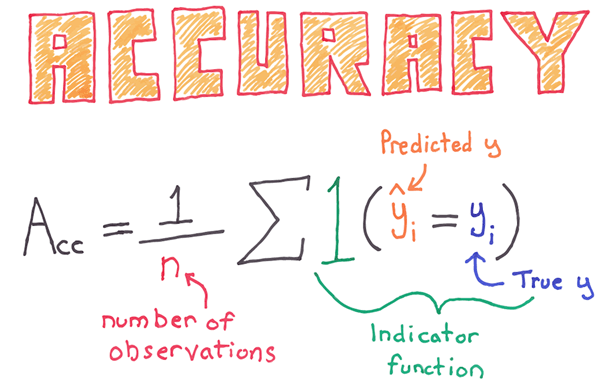
准确性
分类器的整体性能使用准确率指标进行衡量。准确率等于所有正确值除以观察值的总数。例如,80% 的准确率意味着模型在 80% 的情况下是正确的。
您可能会注意到此指标存在一个缺点,尤其是在类不平衡的情况下。不平衡数据集是指每组观测值的数量不相等。假设;您尝试使用 Logistic 函数对罕见事件进行分类。设想分类器试图估计患者因疾病死亡的可能性。在数据中,5% 的患者会死亡。您可以训练一个分类器来预测死亡人数,并使用准确率指标来评估性能。如果分类器预测整个数据集的死亡人数为 0,那么它将在 95% 的情况下是正确的。
混淆矩阵
评估分类器性能的更好方法是查看混淆矩阵。
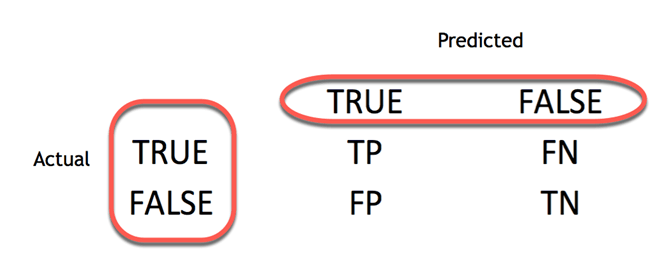
如上一个线性分类器示例所示,混淆矩阵通过比较实际类别和预测类别来可视化分类器的准确率。二元混淆矩阵由方格组成
- TP:真阳性:正确预测为实际阳性的预测值
- FP:错误地将负值预测为实际阳性。即,负值预测为阳性
- FN:假阴性:将阳性值预测为阴性
- TN:真阴性:正确预测为实际阴性的预测值
从混淆矩阵中,可以轻松比较实际类别和预测类别。
精确率和召回率
混淆矩阵提供了对真阳性和假阳性的良好洞察。在某些情况下,拥有更简洁的指标会更好。
精确率
精确率指标显示了正类的准确率。它衡量正类预测正确的可能性。
![]()
当分类器完美地分类所有正值时,最高得分为 1。精确率本身作用不大,因为它忽略了负类。该指标通常与召回率指标配对。召回率也称为灵敏度或真阳性率。
灵敏度
灵敏度计算正确检测到的正类的比率。此指标显示了模型识别正类的能力。
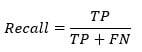
TensorFlow 线性分类器
在本教程中,我们将使用人口普查数据集。目的是使用人口普查数据集中的变量来预测收入水平。请注意,收入是一个二元变量
- 如果收入 > 50k,则值为 1
- 如果收入 < 50k,则为 0。
此变量是您的标签
该数据集包含八个分类变量
- 工作场所
- education
- marital
- occupation
- relationship
- race
- sex
- native_country
此外,还有六个连续变量
- age
- fnlwgt
- education_num
- capital_gain
- capital_loss
- hours_week
通过这个 TensorFlow 分类示例,您将了解如何使用 TensorFlow estimator 训练线性 TensorFlow 分类器以及如何提高准确率指标。
我们将按以下步骤进行:
- 步骤 1) 导入数据
- 步骤 2) 数据转换
- 步骤 3) 训练分类器
- 步骤 4) 改进模型
- 步骤 5) 超参数:Lasso & Ridge
步骤 1) 导入数据
您首先导入教程中使用的库。
import tensorflow as tf import pandas as pd
接下来,您从 UCI 档案中导入数据并定义列名。您将使用 COLUMNS 为 pandas 数据帧中的列命名。
请注意,您将使用 Pandas 数据帧训练分类器。
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
PATH_test = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test"
存储在线的数据已分为训练集和测试集。
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_test = pd.read_csv(PATH_test,skiprows = 1, skipinitialspace=True, names = COLUMNS, index_col=False)
训练集包含 32,561 个观测值,测试集包含 16,281 个观测值。
print(df_train.shape, df_test.shape) print(df_train.dtypes) (32561, 15) (16281, 15) age int64 workclass object fnlwgt int64 education object education_num int64 marital object occupation object relationship object race object sex object capital_gain int64 capital_loss int64 hours_week int64 native_country object label object dtype: object
Tensorflow 需要布尔值来训练分类器。您需要将字符串值转换为整数。标签存储为对象,但您需要将其转换为数值。下面的代码创建了一个包含要转换的值的字典,并循环遍历列项。请注意,您对训练集和测试集都执行此操作。
label = {'<=50K': 0,'>50K': 1}
df_train.label = [label[item] for item in df_train.label]
label_t = {'<=50K.': 0,'>50K.': 1}
df_test.label = [label_t[item] for item in df_test.label]
在训练数据中,有 24,720 个收入低于 50k,7841 个收入高于 50k。测试集中的比率几乎相同。请参阅此 Facets 教程了解更多信息。
print(df_train["label"].value_counts()) ### The model will be correct in atleast 70% of the case print(df_test["label"].value_counts()) ## Unbalanced label print(df_train.dtypes) 0 24720 1 7841 Name: label, dtype: int64 0 12435 1 3846 Name: label, dtype: int64 age int64 workclass object fnlwgt int64 education object education_num int64 marital object occupation object relationship object race object sex object capital_gain int64 capital_loss int64 hours_week int64 native_country object label int64 dtype: object
步骤 2) 数据转换
在您使用 Tensorflow 训练线性分类器之前,需要完成几个步骤。您需要准备要包含在模型中的特征。在基准回归中,您将使用原始数据,而不应用任何转换。
Estimator 需要一个特征列表来训练模型。因此,需要将列数据转换为张量。
一个好的做法是根据特征的类型定义两个特征列表,然后将它们传递给 estimator 的 feature_columns。
我们将首先转换连续特征,然后定义一个分箱来处理分类数据。
数据集的特征有两种格式
- 整数
- 对象
每个特征根据其类型列在接下来的两个变量中。
## Add features to the bucket: ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define the categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
feature_column 配备了一个 numeric_column 对象,用于帮助转换连续变量为张量。在下面的代码中,我们将 CONTI_FEATURES 中的所有变量转换为具有数值的张量。这是构建模型所必需的。所有自变量都需要转换为正确的张量类型。
下面我们写一段代码让您了解 feature_column.numeric_column 背后发生了什么。我们将打印转换后的年龄值。这仅用于解释目的,因此无需理解 python 代码。您可以参考官方文档来理解代码。
def print_transformation(feature = "age", continuous = True, size = 2):
#X = fc.numeric_column(feature)
## Create feature name
feature_names = [
feature]
## Create dict with the data
d = dict(zip(feature_names, [df_train[feature]]))
## Convert age
if continuous == True:
c = tf.feature_column.numeric_column(feature)
feature_columns = [c]
else:
c = tf.feature_column.categorical_column_with_hash_bucket(feature, hash_bucket_size=size)
c_indicator = tf.feature_column.indicator_column(c)
feature_columns = [c_indicator]
## Use input_layer to print the value
input_layer = tf.feature_column.input_layer(
features=d,
feature_columns=feature_columns
)
## Create lookup table
zero = tf.constant(0, dtype=tf.float32)
where = tf.not_equal(input_layer, zero)
## Return lookup tble
indices = tf.where(where)
values = tf.gather_nd(input_layer, indices)
## Initiate graph
sess = tf.Session()
## Print value
print(sess.run(input_layer))
print_transformation(feature = "age", continuous = True)
[[39.]
[50.]
[38.]
...
[58.]
[22.]
[52.]]
这些值与 df_train 中的值完全相同
continuous_features = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES]
根据 TensorFlow 文档,有几种方法可以转换分类数据。如果特征的词汇表已知且值不多,则可以使用 categorical_column_with_vocabulary_list 创建分类列。它将为所有唯一的词汇表分配一个 ID。
例如,如果变量 status 有三个不同的值
- 丈夫
- 妻子
- 单
那么将分配三个 ID。例如,丈夫将获得 ID 1,妻子获得 ID 2,依此类推。
为了说明起见,您可以使用此代码将对象变量转换为 TensorFlow 中的分类列。
特征 sex 只能有两个值:male 或 female。当我们转换特征 sex 时,Tensorflow 将创建 2 个新列,一个用于 male,一个用于 female。如果 sex 等于 male,那么新列 male 将等于 1,female 等于 0。此示例显示在下表中
| 行 | sex | 转换后 | 男性 | 女性 |
|---|---|---|---|---|
| 1 | 男性 | => | 1 | 0 |
| 2 | 男性 | => | 1 | 0 |
| 3 | 女性 | => | 0 | 1 |
在 TensorFlow 中
print_transformation(feature = "sex", continuous = False, size = 2)
[[1. 0.]
[1. 0.]
[1. 0.]
...
[0. 1.]
[1. 0.]
[0. 1.]]
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
下面,我们添加了 Python 代码来打印编码。同样,您无需理解代码,目的是查看转换。
但是,一种更快的转换数据的方法是使用 categorical_column_with_hash_bucket 方法。将字符串变量转换为稀疏矩阵将很有用。稀疏矩阵是大部分元素为零的矩阵。该方法负责所有事情。您只需要指定桶的数量和键列。桶的数量是 TensorFlow 可以创建的最大组数。键列就是要转换的列名。
在下面的代码中,您将创建一个循环来处理所有分类特征。
categorical_features = [tf.feature_column.categorical_column_with_hash_bucket(k, hash_bucket_size=1000) for k in CATE_FEATURES]
步骤 3) 训练分类器
TensorFlow 目前提供了线性回归和线性分类的 estimator。
- 线性回归:LinearRegressor
- 线性分类:LinearClassifier
线性分类器的语法与“线性回归”教程中的相同,只是有一个参数 n_class 不同。您需要定义特征列、模型目录,并与线性回归器相比,您需要定义类的数量。对于 logit 回归,类的数量等于 2。
模型将计算 continuous_features 和 categorical_features 中列的权重。
model = tf.estimator.LinearClassifier(
n_classes = 2,
model_dir="ongoing/train",
feature_columns=categorical_features+ continuous_features)
输出
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec':
<tensorflow.python.training.server_lib.ClusterSpec object at 0x181f24c898>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
现在已经定义了分类器,您可以创建 input function。该方法与线性回归器教程中的相同。这里,我们使用批次大小为 128,并对数据进行 shuffle。
FEATURES = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country']
LABEL= 'label'
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
我们创建一个函数,其中包含线性 estimator 所需的参数,即 epochs 的数量、批次的数量以及是否 shuffle 数据集。由于我们使用Pandas方法将数据传递给模型,因此需要将 X 变量定义为 pandas 数据帧。请注意,您将遍历 FEATURES 中存储的所有数据。
让我们使用 model.train 对象训练模型。您使用之前定义的函数向模型提供适当的值。请注意,我们将批次大小设置为 128,epochs 设置为 None。模型将训练一千步。
model.train(input_fn=get_input_fn(df_train,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow: Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 65.8282 INFO:tensorflow:loss = 52583.64, step = 101 (1.528 sec) INFO:tensorflow:global_step/sec: 118.386 INFO:tensorflow:loss = 25203.816, step = 201 (0.837 sec) INFO:tensorflow:global_step/sec: 110.542 INFO:tensorflow:loss = 54924.312, step = 301 (0.905 sec) INFO:tensorflow:global_step/sec: 199.03 INFO:tensorflow:loss = 68509.31, step = 401 (0.502 sec) INFO:tensorflow:global_step/sec: 167.488 INFO:tensorflow:loss = 9151.754, step = 501 (0.599 sec) INFO:tensorflow:global_step/sec: 220.155 INFO:tensorflow:loss = 34576.06, step = 601 (0.453 sec) INFO:tensorflow:global_step/sec: 199.016 INFO:tensorflow:loss = 36047.117, step = 701 (0.503 sec) INFO:tensorflow:global_step/sec: 197.531 INFO:tensorflow:loss = 22608.148, step = 801 (0.505 sec) INFO:tensorflow:global_step/sec: 208.479 INFO:tensorflow:loss = 22201.918, step = 901 (0.479 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train/model.ckpt. INFO:tensorflow:Loss for final step: 5444.363. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x181f223630>
请注意,在最后 100 步(即从 901 到 1000)中,损失逐渐下降。
一千次迭代后的最终损失为 5444。您可以对测试集评估模型并查看性能。要评估模型的性能,您需要使用 evaluate 对象。将测试集输入模型,并将 epochs 设置为 1,即数据仅通过模型一次。
model.evaluate(input_fn=get_input_fn(df_test,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:28:22
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:28:23
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.7615626, accuracy_baseline = 0.76377374, auc = 0.63300294, auc_precision_recall = 0.50891197, average_loss = 47.12155, global_step = 1000, label/mean = 0.23622628, loss = 5993.6406, precision = 0.49401596, prediction/mean = 0.18454961, recall = 0.38637546
{'accuracy': 0.7615626,
'accuracy_baseline': 0.76377374,
'auc': 0.63300294,
'auc_precision_recall': 0.50891197,
'average_loss': 47.12155,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 5993.6406,
'precision': 0.49401596,
'prediction/mean': 0.18454961,
'recall': 0.38637546}
TensorFlow 返回了您在理论部分学到的所有指标。不出所料,由于标签不平衡,准确率很高。实际上,模型的性能比随机猜测略好。想象一下,如果模型预测所有家庭的收入都低于 50K,那么模型的准确率将是 70%。仔细分析,您会发现精确率和召回率都相当低。
步骤 4) 改进模型
现在您有了一个基准模型,您可以尝试改进它,即提高准确率。在上一教程中,您学习了如何通过交互项提高预测能力。在本教程中,您将通过向回归添加多项式项来重新审视这个想法。
当数据中存在非线性时,多项式回归非常有用。有两种方法可以捕获数据中的非线性。
- 添加多项式项
- 将连续变量分箱为分类变量
多项式项
从下图可以看出,多项式回归是什么。它是一个包含不同幂次 X 变量的方程。二次多项式回归有两个变量,X 和 X 平方。三次有三个变量,X、X² 和 X³
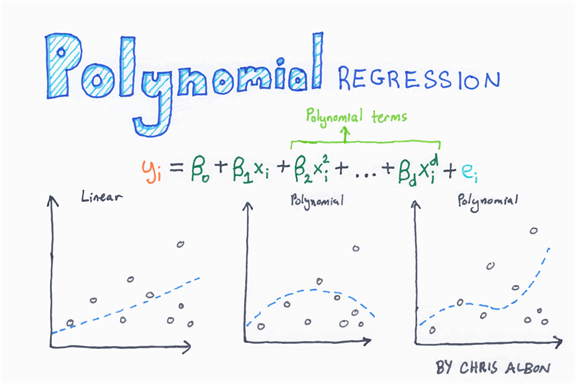
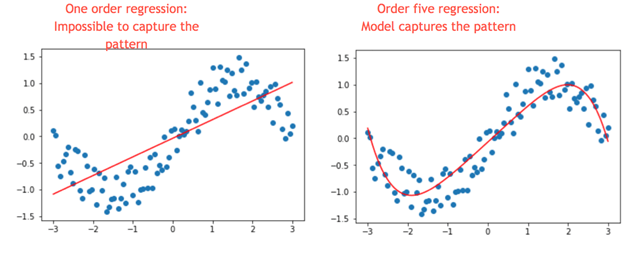
下面,我们构建了一个包含两个变量 X 和 Y 的图。很明显,它们之间不是线性关系。如果我们添加一个线性回归,我们可以看到模型无法捕捉模式(左图)。
现在,看下图的左图,我们在回归中添加了五项(即 y=x+x²+x³+x⁴+x⁵。模型现在更好地捕捉了模式。这就是多项式回归的力量。
让我们回到我们的例子。年龄与收入并非线性相关。早年收入可能接近零,因为儿童或年轻人不工作。然后,在工作年龄时增加,在退休时减少。它通常呈反 U 形。捕捉这种模式的一种方法是在回归中添加二次方。
让我们看看它是否能提高准确率。
您需要将这个新特征添加到数据集中,并添加到连续特征列表中。
我们将新变量添加到训练集和测试数据集中,因此编写一个函数更方便。
def square_var(df_t, df_te, var_name = 'age'):
df_t['new'] = df_t[var_name].pow(2)
df_te['new'] = df_te[var_name].pow(2)
return df_t, df_te
该函数有 3 个参数
- df_t:定义训练集
- df_te:定义测试集
- var_name = ‘age’:定义要转换的变量
您可以使用 pow(2) 对象来计算年龄的平方。请注意,新变量命名为 'new'。
现在函数 square_var 已经写好,您可以创建新的数据集。
df_train_new, df_test_new = square_var(df_train, df_test, var_name = 'age')
可以看到,新数据集多了一个特征。
print(df_train_new.shape, df_test_new.shape) (32561, 16) (16281, 16)
平方变量在数据集中称为 new。您需要将其添加到连续特征列表中。
CONTI_FEATURES_NEW = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week', 'new'] continuous_features_new = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES_NEW]
请注意,您更改了 Graph 的目录。您不能在同一目录中训练不同的模型。这意味着,您需要更改 model_dir 参数的路径。如果您不这样做,TensorFlow 将抛出错误。
model_1 = tf.estimator.LinearClassifier(
model_dir="ongoing/train1",
feature_columns=categorical_features+ continuous_features_new)
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train1', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec':
<tensorflow.python.training.server_lib.ClusterSpec object at 0x1820f04b70>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
FEATURES_NEW = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'new']
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES_NEW}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
现在,用新数据集设计了分类器,您可以训练和评估模型。
model_1.train(input_fn=get_input_fn(df_train,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train1/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 81.487 INFO:tensorflow:loss = 70077.66, step = 101 (1.228 sec) INFO:tensorflow:global_step/sec: 111.169 INFO:tensorflow:loss = 49522.082, step = 201 (0.899 sec) INFO:tensorflow:global_step/sec: 128.91 INFO:tensorflow:loss = 107120.57, step = 301 (0.776 sec) INFO:tensorflow:global_step/sec: 132.546 INFO:tensorflow:loss = 12814.152, step = 401 (0.755 sec) INFO:tensorflow:global_step/sec: 162.194 INFO:tensorflow:loss = 19573.898, step = 501 (0.617 sec) INFO:tensorflow:global_step/sec: 204.852 INFO:tensorflow:loss = 26381.986, step = 601 (0.488 sec) INFO:tensorflow:global_step/sec: 188.923 INFO:tensorflow:loss = 23417.719, step = 701 (0.529 sec) INFO:tensorflow:global_step/sec: 192.041 INFO:tensorflow:loss = 23946.049, step = 801 (0.521 sec) INFO:tensorflow:global_step/sec: 197.025 INFO:tensorflow:loss = 3309.5786, step = 901 (0.507 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train1/model.ckpt. INFO:tensorflow:Loss for final step: 28861.898. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x1820f04c88>
model_1.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:28:37
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train1/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:28:39
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.7944229, accuracy_baseline = 0.76377374, auc = 0.6093755, auc_precision_recall = 0.54885805, average_loss = 111.0046, global_step = 1000, label/mean = 0.23622628, loss = 14119.265, precision = 0.6682401, prediction/mean = 0.09116262, recall = 0.2576703
{'accuracy': 0.7944229,
'accuracy_baseline': 0.76377374,
'auc': 0.6093755,
'auc_precision_recall': 0.54885805,
'average_loss': 111.0046,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 14119.265,
'precision': 0.6682401,
'prediction/mean': 0.09116262,
'recall': 0.2576703}
平方变量将准确率从 0.76 提高到 0.79。让我们看看是否可以通过结合分箱和交互项做得更好。
分箱和交互
如前所述,线性分类器无法正确捕捉年龄-收入模式。这是因为它的每个特征只学习一个权重。为了让分类器更容易,您可以做的一件事是将特征进行分箱。分箱是将数字特征转换为几个特定特征,这些特征基于其所属的范围,并且这些新特征中的每一个都表示一个人的年龄是否落入该范围。
有了这些新特征,线性模型就可以通过为每个分箱学习不同的权重来捕捉这种关系。
在 TensorFlow 中,这是使用 bucketized_column 完成的。您需要在 boundaries 中添加值范围。
age = tf.feature_column.numeric_column('age')
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
您已经知道年龄与收入是非线性关系的。提高模型的另一种方法是通过交互。在 TensorFlow 的术语中,这称为特征交叉。特征交叉是一种创建现有特征组合的新特征的方法,这对于无法对特征之间的交互进行建模的线性分类器很有用。
您可以将年龄与另一个特征(如教育)进行细分。也就是说,有些群体可能收入高,有些群体收入低(想想博士生)。
education_x_occupation = [tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000)]
age_buckets_x_education_x_occupation = [tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000)]
要创建交叉特征列,请使用 crossed_column,并在括号中包含要交叉的变量。hash_bucket_size 指示了最大的交叉可能性。要创建变量之间的交互(至少一个变量必须是分类变量),您可以使用 tf.feature_column.crossed_column。要使用此对象,您需要在方括号中包含要交互的变量和第二个参数,即桶大小。桶大小是变量中可能的最大组数。这里我们设置为 1000,因为我们不知道确切的组数。
需要先对 age_buckets 进行平方才能将其添加到特征列中。您还将新特征添加到特征列并准备 estimator。
base_columns = [
age_buckets,
]
model_imp = tf.estimator.LinearClassifier(
model_dir="ongoing/train3",
feature_columns=categorical_features+base_columns+education_x_occupation+age_buckets_x_education_x_occupation)
输出
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train3', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1823021be0>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
FEATURES_imp = ['age','workclass', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'native_country', 'new']
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES_imp}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
您已准备好估计新模型并查看它是否提高了准确率。
model_imp.train(input_fn=get_input_fn(df_train_new,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train3/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 94.969 INFO:tensorflow:loss = 50.334488, step = 101 (1.054 sec) INFO:tensorflow:global_step/sec: 242.342 INFO:tensorflow:loss = 56.153225, step = 201 (0.414 sec) INFO:tensorflow:global_step/sec: 213.686 INFO:tensorflow:loss = 45.792007, step = 301 (0.470 sec) INFO:tensorflow:global_step/sec: 174.084 INFO:tensorflow:loss = 37.485672, step = 401 (0.572 sec) INFO:tensorflow:global_step/sec: 191.78 INFO:tensorflow:loss = 56.48449, step = 501 (0.524 sec) INFO:tensorflow:global_step/sec: 163.436 INFO:tensorflow:loss = 32.528934, step = 601 (0.612 sec) INFO:tensorflow:global_step/sec: 164.347 INFO:tensorflow:loss = 37.438057, step = 701 (0.607 sec) INFO:tensorflow:global_step/sec: 154.274 INFO:tensorflow:loss = 61.1075, step = 801 (0.647 sec) INFO:tensorflow:global_step/sec: 189.14 INFO:tensorflow:loss = 44.69645, step = 901 (0.531 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train3/model.ckpt. INFO:tensorflow:Loss for final step: 44.18133. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x1823021cf8>
model_imp.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:28:52
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train3/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:28:54
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.8358209, accuracy_baseline = 0.76377374, auc = 0.88401634, auc_precision_recall = 0.69599575, average_loss = 0.35122654, global_step = 1000, label/mean = 0.23622628, loss = 44.67437, precision = 0.68986726, prediction/mean = 0.23320661, recall = 0.55408216
{'accuracy': 0.8358209,
'accuracy_baseline': 0.76377374,
'auc': 0.88401634,
'auc_precision_recall': 0.69599575,
'average_loss': 0.35122654,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 44.67437,
'precision': 0.68986726,
'prediction/mean': 0.23320661,
'recall': 0.55408216}
新的准确率水平为 83.58%。比之前的模型高了四个百分点。
最后,您可以添加正则化项来防止过拟合。
步骤 5) 超参数:Lasso & Ridge
您的模型可能存在过拟合或欠拟合。
- 过拟合:模型无法泛化到新数据的预测
- 欠拟合:模型无法捕捉数据模式。即,当数据非线性时使用线性回归
当模型拥有大量参数且数据量相对较少时,会导致预测不佳。设想一个组只有三个观测值;模型将为该组计算一个权重。该权重用于进行预测;如果该特定组的测试集观测值与训练集完全不同,那么模型将做出错误的预测。在训练集上进行评估时,准确率很高,但在测试集上不高,因为计算出的权重不是真实的权重,无法泛化模式。在这种情况下,它对未见过的数据没有合理的预测。
为防止过拟合,正则化为您提供了控制这种复杂性并使其更具泛化性的可能性。有两种正则化技术
- L1:Lasso
- L2:Ridge
在 TensorFlow 中,您可以将这两个超参数添加到优化器中。例如,L2 超参数值越高,权重趋于非常低并接近于零。拟合线将非常平坦,而接近零的 L2 表示权重接近常规线性回归。
您可以自己尝试不同的超参数值,看看是否能提高准确率。
请注意,如果您更改超参数,则需要删除 ongoing/train4 文件夹,否则模型将从之前训练过的模型开始。
让我们看看使用超参数的准确率如何
model_regu = tf.estimator.LinearClassifier(
model_dir="ongoing/train4", feature_columns=categorical_features+base_columns+education_x_occupation+age_buckets_x_education_x_occupation,
optimizer=tf.train.FtrlOptimizer(
learning_rate=0.1,
l1_regularization_strength=0.9,
l2_regularization_strength=5))
输出
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train4', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1820d9c128>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
model_regu.train(input_fn=get_input_fn(df_train_new,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
输出
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train4/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 77.4165 INFO:tensorflow:loss = 50.38778, step = 101 (1.294 sec) INFO:tensorflow:global_step/sec: 187.889 INFO:tensorflow:loss = 55.38014, step = 201 (0.535 sec) INFO:tensorflow:global_step/sec: 201.895 INFO:tensorflow:loss = 46.806694, step = 301 (0.491 sec) INFO:tensorflow:global_step/sec: 217.992 INFO:tensorflow:loss = 38.68271, step = 401 (0.460 sec) INFO:tensorflow:global_step/sec: 193.676 INFO:tensorflow:loss = 56.99398, step = 501 (0.516 sec) INFO:tensorflow:global_step/sec: 202.195 INFO:tensorflow:loss = 33.263622, step = 601 (0.497 sec) INFO:tensorflow:global_step/sec: 216.756 INFO:tensorflow:loss = 37.7902, step = 701 (0.459 sec) INFO:tensorflow:global_step/sec: 240.215 INFO:tensorflow:loss = 61.732605, step = 801 (0.416 sec) INFO:tensorflow:global_step/sec: 220.336 INFO:tensorflow:loss = 46.938225, step = 901 (0.456 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train4/model.ckpt. INFO:tensorflow:Loss for final step: 43.4942. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x181ff39e48>
model_regu.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
输出
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:29:07
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train4/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:29:09
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.83833915, accuracy_baseline = 0.76377374, auc = 0.8869794, auc_precision_recall = 0.7014905, average_loss = 0.34691378, global_step = 1000, label/mean = 0.23622628, loss = 44.12581, precision = 0.69720596, prediction/mean = 0.23662092, recall = 0.5579823
{'accuracy': 0.83833915,
'accuracy_baseline': 0.76377374,
'auc': 0.8869794,
'auc_precision_recall': 0.7014905,
'average_loss': 0.34691378,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 44.12581,
'precision': 0.69720596,
'prediction/mean': 0.23662092,
'recall': 0.5579823}
使用此超参数,您略微提高了准确率指标。在下一个教程中,您将学习如何使用核方法改进线性分类器。
摘要
要训练模型,您需要
- 定义特征:自变量:X
- 定义标签:因变量:y
- 构建训练/测试集
- 定义初始权重
- 定义损失函数:MSE
- 优化模型:梯度下降
- 定义
- 学习率
- Epoch 数量
- 批量大小
- 类数
在本教程中,您学习了如何为线性回归分类器使用高级 API。您需要定义
- 特征列。如果是连续的:tf.feature_column.numeric_column()。您可以使用 python 列表推导式填充列表。
- Estimator:tf.estimator.LinearClassifier(feature_columns, model_dir, n_classes = 2)
- 一个用于导入数据、批量大小和 epoch 的函数:input_fn()
之后,您就可以使用 train()、evaluate() 和 predict() 来训练、评估和进行预测了。
要提高模型性能,您可以
- 使用多项式回归
- 交互项:tf.feature_column.crossed_column
- 添加正则化参数