PyTorch 教程
Pytorch 教程摘要
在本 Pytorch 教程中,您将从零开始学习所有概念。本教程涵盖了从基础到高级的主题,如 Pytorch 的定义、优缺点、比较、安装、Pytorch 框架、回归和图像分类。本 Pytorch 教程完全免费。
什么是 PyTorch?
PyTorch 是一个开源的、基于 Torch 的机器学习库,使用 Python 进行自然语言处理。它类似于 NumPy,但具有强大的 GPU 支持。它提供了动态计算图,您可以在运行时借助 autograd 对其进行修改。PyTorch 也比其他一些框架更快。它由 Facebook 的人工智能研究小组于 2016 年开发。
PyTorch 的优点和缺点
以下是 PyTorch 的优点和缺点
PyTorch 的优点
- 简单的库
PyTorch 代码简单。它易于理解,您可以立即使用该库。例如,请看下面的代码片段
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
如上所述,您可以轻松定义网络模型,并且无需太多培训即可快速理解代码。
- 动态计算图

Pytorch 提供动态计算图 (DAG)。计算图是一种在图模型或理论(如节点和边)中表达数学表达式的方法。节点将执行数学运算,边是一个张量,将被输入到节点中并携带节点的输出张量。
DAG 是一种具有任意形状的图,能够对不同的输入图进行操作。每次迭代都会创建一个新的图。因此,可以拥有相同的图结构或创建一个具有不同操作的新图,我们也可以称之为动态图。
- 更好的性能
社区和研究人员通过基准测试和比较框架来评估哪个更快。一个 GitHub 仓库 深度学习框架和 GPU 基准测试 报告称,在每秒处理的图像数量方面,PyTorch 比其他框架更快。
如下所示,是 vgg16 和 resnet152 的比较图
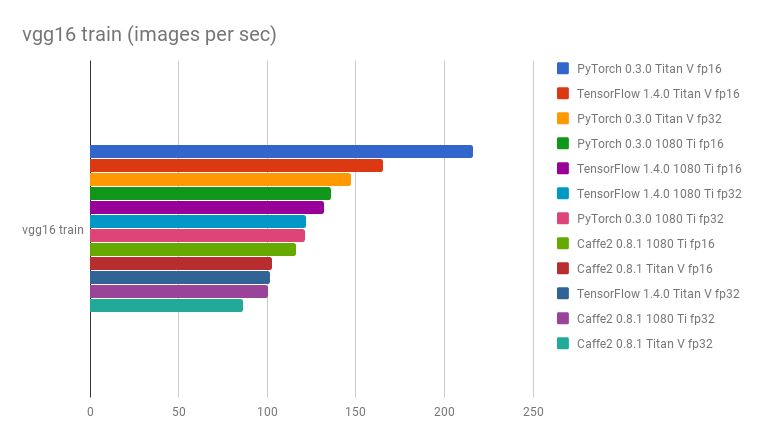
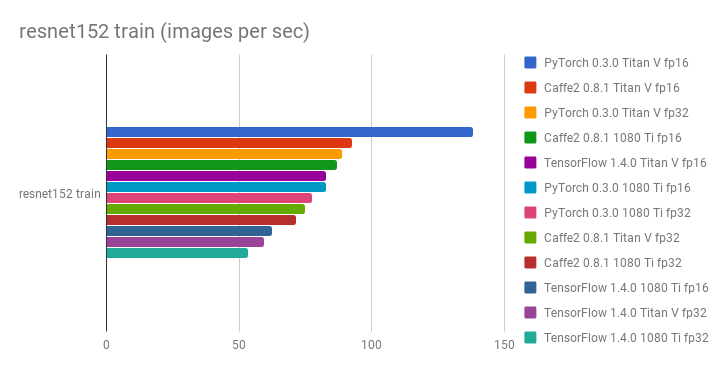
- 原生 Python
PyTorch 更加基于 Python。例如,如果您想训练一个模型,您可以使用原生的控制流,如循环和递归,而无需添加更多的特殊变量或会话来运行它们。这对训练过程非常有帮助。
Pytorch 还实现了命令式编程,这无疑更具灵活性。因此,可以在计算过程中打印出张量的值。
PyTorch 的缺点
PyTorch 需要第三方应用程序进行可视化。它还需要一个用于生产环境的 API 服务器。
接下来在这个 PyTorch 教程中,我们将学习 PyTorch 和 TensorFlow 之间的区别。
PyTorch 对比 Tensorflow
| 参数 | PyTorch | Tensorflow |
|---|---|---|
| 模型定义 | 模型在子类中定义,并提供易于使用的包 | 模型定义复杂,您需要理解其语法 |
| GPU 支持 | 是 | 是 |
| 图类型 | 动态 | 静态 |
| 工具 | 没有可视化工具 | 您可以使用 Tensorboard 可视化工具 |
| 社区 | 社区仍在成长中 | 庞大而活跃的社区 |
安装 PyTorch
Linux
在 Linux 中安装它非常直接。您可以选择使用虚拟环境或直接使用 root 权限安装。在终端中输入此命令
pip3 install --upgrade torch torchvision
AWS Sagemaker
亚马逊网络服务 中的 Sagemaker 平台之一,提供强大的机器学习引擎,带有预安装的深度学习配置,供数据科学家或开发人员在任何规模下构建、训练和部署模型。
首先打开 Amazon Sagemaker 控制台,点击创建笔记本实例并填写您的笔记本的所有详细信息。
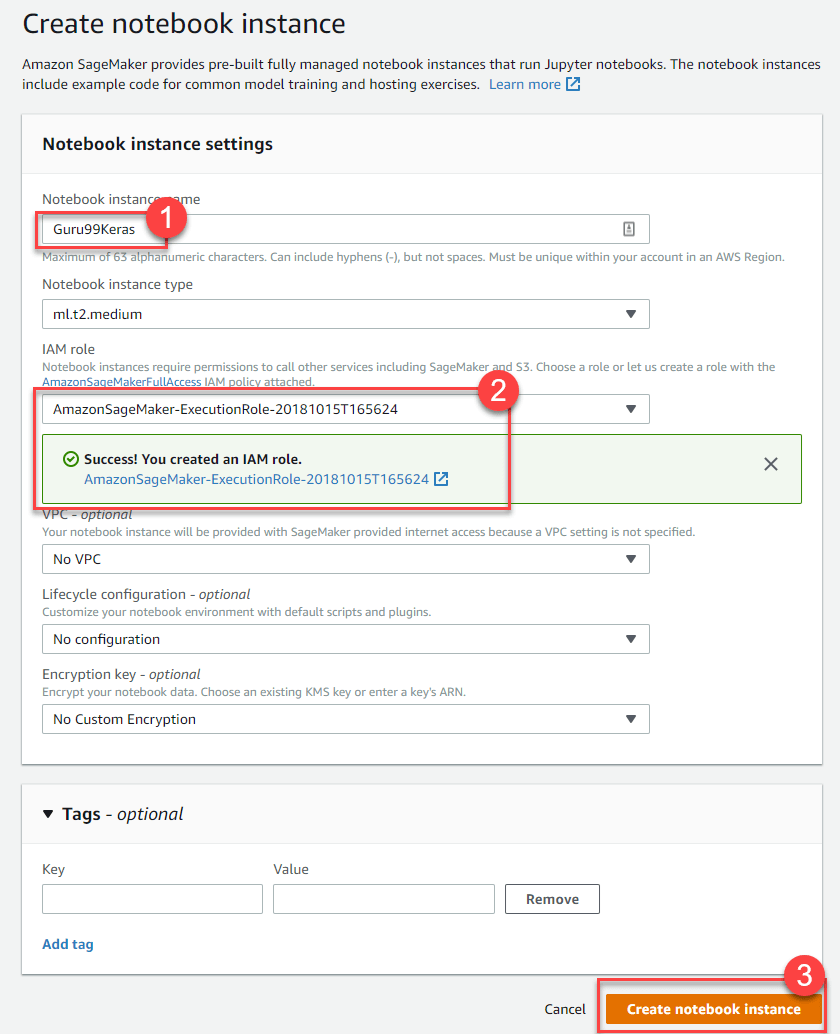
下一步,点击打开以启动您的笔记本实例。

最后,在 Jupyter 中,点击新建并选择 conda_pytorch_p36,然后您就可以使用已安装 Pytorch 的笔记本实例了。
接下来在这个 PyTorch 教程中,我们将学习 PyTorch 框架的基础知识。
PyTorch 框架基础
在我们深入探讨之前,让我们学习一下 PyTorch 的基本概念。PyTorch 对每个变量都使用张量,类似于 numpy 的 ndarray,但支持 GPU 计算。在这里,我们将解释网络模型、损失函数、反向传播和优化器。
网络模型
网络可以通过子类化 torch.nn 来构建。主要有 2 个部分,
- 第一部分是定义您将使用的参数和层
- 第二部分是称为前向传播过程的主要任务,它将接收输入并预测输出。
Import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 20, 5)
self.conv2 = nn.Conv2d(20, 40, 5)
self.fc1 = nn.Linear(320, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
return F.log_softmax(x)
net = Model()
如上所示,您创建了一个名为 Model 的 nn.Module 类。它包含 2 个 Conv2d 层和一个线性层。第一个 conv2d 层接收 3 个输入,输出形状为 20。第二个层将接收 20 个输入,并产生一个形状为 40 的输出。最后一层是一个形状为 320 的全连接层,并将产生 10 个输出。
前向传播过程将接收一个输入 X,并将其馈送到 conv1 层并执行 ReLU 函数,
同样,它也会馈送到 conv2 层。之后,x 将被重塑为 (-1, 320) 并馈送到最终的 FC 层。在发送输出之前,您将使用 softmax 激活函数。
反向传播过程由 autograd 自动定义,因此您只需要定义前向传播过程。
损失函数
损失函数用于衡量预测模型预测预期结果的好坏。PyTorch 在 torch.nn 模块中已经有许多标准的损失函数。例如,您可以使用交叉熵损失来解决多类 PyTorch 分类问题。定义损失函数和计算损失很容易
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
使用 PyTorch 可以轻松地使用您自己的损失函数计算。
反向传播
要执行反向传播,您只需调用 los.backward()。误差将被计算出来,但请记住用 zero_grad() 清除现有的梯度
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
优化器
torch.optim 提供了常见的优化算法。您可以通过一个简单的步骤定义一个优化器
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
您需要传递网络模型参数和学习率,以便在每次迭代中,参数将在反向传播过程后更新。
使用 PyTorch 进行简单回归
让我们通过 PyTorch 示例学习简单的回归
步骤 1) 创建我们的网络模型
我们的网络模型是一个简单的线性层,输入和输出形状均为 1。
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
net = Net()
print(net)
网络输出应该像这样
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
步骤 2) 测试数据
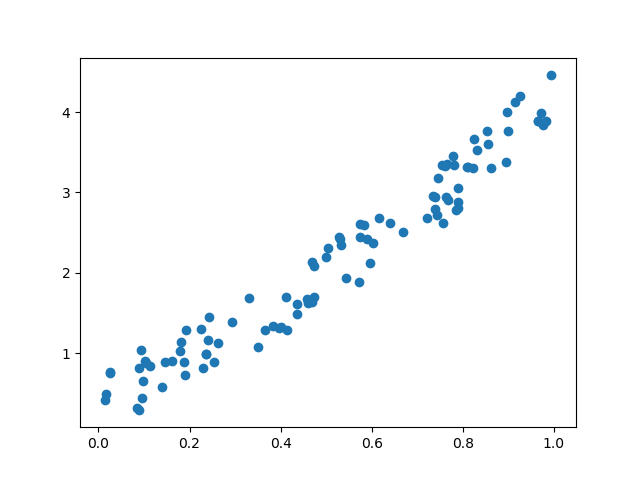
在开始训练过程之前,您需要了解我们的数据。我们创建一个随机函数来测试我们的模型。Y = x3 sin(x)+ 3x+0.8 rand(100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
这是我们函数的散点图
在开始训练过程之前,您需要将 numpy 数组转换为 Torch 和 autograd 支持的变量,如下面的 PyTorch 回归示例所示。
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
步骤 3) 优化器和损失
接下来,您应该为我们的训练过程定义优化器和损失函数。
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
步骤 4) 训练
现在让我们开始训练过程。通过 250 个 epoch,我们将迭代我们的数据,以找到超参数的最佳值。
inputs = Variable(x)
outputs = Variable(y)
for i in range(250):
prediction = net(inputs)
loss = loss_func(prediction, outputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 10 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.show()
步骤 5) 结果
如下所示,您已成功使用神经网络执行 PyTorch 回归。实际上,在每次迭代中,图中的红线都会更新并改变其位置以拟合数据。但在这张图片中,它只向您展示了最终结果,如下面的 PyTorch 示例所示
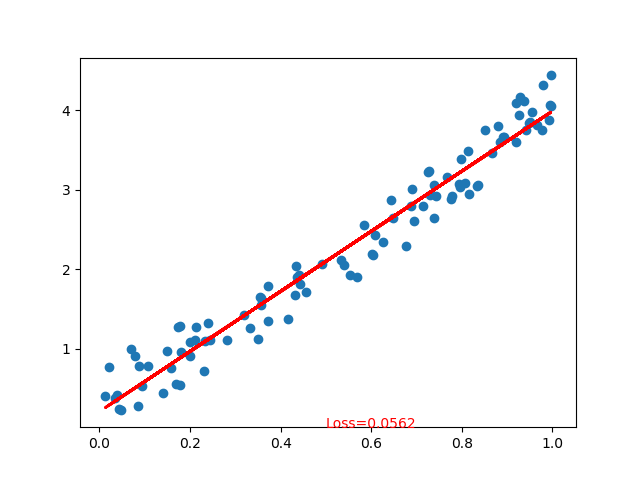
使用 PyTorch 进行图像分类示例
学习深度学习基础知识的流行方法之一是使用 MNIST 数据集。它是深度学习中的“Hello World”。该数据集包含从 0 到 9 的手写数字,总共有 60,000 个训练样本和 10,000 个测试样本,这些样本已经用 28×28 像素的大小进行了标记。

步骤 1) 预处理数据
在此 PyTorch 分类示例的第一步中,您将使用 torchvision 模块加载数据集。
在开始训练过程之前,您需要了解数据。Torchvision 将加载数据集并根据网络的要求对图像进行转换,例如形状和图像归一化。
import torch
import torchvision
import numpy as np
from torchvision import datasets, models, transforms
# This is used to transform the images to Tensor and normalize it
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
training = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(training, batch_size=4,
shuffle=True, num_workers=2)
testing = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(testing, batch_size=4,
shuffle=False, num_workers=2)
classes = ('0', '1', '2', '3',
'4', '5', '6', '7', '8', '9')
import matplotlib.pyplot as plt
import numpy as np
#create an iterator for train_loader
# get random training images
data_iterator = iter(train_loader)
images, labels = data_iterator.next()
#plot 4 images to visualize the data
rows = 2
columns = 2
fig=plt.figure()
for i in range(4):
fig.add_subplot(rows, columns, i+1)
plt.title(classes[labels[i]])
img = images[i] / 2 + 0.5 # this is for unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()
transform 函数将图像转换为张量并对值进行归一化。函数 torchvision.transforms.MNIST 将在目录中下载数据集(如果不存在),根据需要设置数据集进行训练,并执行转换过程。
为了可视化数据集,您使用 data_iterator 来获取下一批图像和标签。您使用 matplot 来绘制这些图像及其相应的标签。如下所示是我们的图像及其标签。
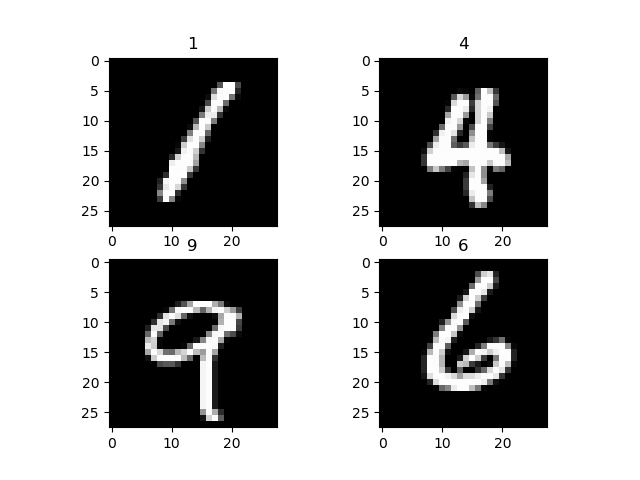
步骤 2) 网络模型配置
现在,在这个 PyTorch 示例中,您将为 PyTorch 图像分类创建一个简单的神经网络。
在这里,我们向您介绍另一种在 PyTorch 中创建网络模型的方法。我们将使用 nn.Sequential 来创建一个序列模型,而不是创建一个 nn.Module 的子类。
import torch.nn as nn
# flatten the tensor into
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
#sequential based model
seq_model = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Dropout2d(),
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
Flatten(),
nn.Linear(320, 50),
nn.ReLU(),
nn.Linear(50, 10),
nn.Softmax(),
)
net = seq_model
print(net)
这是我们网络模型的输出
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
网络解释
- 该序列的第一层是一个 Conv2D 层,输入形状为 1,输出形状为 10,内核大小为 5
- 接下来,您有一个 MaxPool2D 层
- 一个 ReLU 激活函数
- 一个 Dropout 层,用于丢弃低概率值。
- 然后是第二个 Conv2d,输入形状为来自上一层的 10,输出形状为 20,内核大小为 5
- 接下来是一个 MaxPool2d 层
- ReLU 激活函数。
- 之后,您将在将其馈送到线性层之前将张量展平
- 线性层将我们的输出映射到第二个带有 softmax 激活函数的线性层
步骤 3) 训练模型
在开始训练过程之前,需要设置标准和优化器函数。
对于标准,您将使用 CrossEntropyLoss。对于优化器,您将使用 SGD,学习率为 0.001,动量为 0.9,如下面的 PyTorch 示例所示。
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
前向过程将接收输入形状并将其传递给第一个 conv2d 层。然后从那里,它将被馈送到 maxpool2d,并最终放入 ReLU 激活函数。同样的过程将在第二个 conv2d 层中发生。之后,输入将被重塑为 (-1,320) 并馈送到 fc 层以预测输出。
现在,您将开始训练过程。您将遍历我们的数据集 2 次,或者说 epoch 为 2,并在每 2000 个批次时打印出当前的损失。
for epoch in range(2):
#set the running loss at each epoch to zero
running_loss = 0.0
# we will enumerate the train loader with starting index of 0
# for each iteration (i) and the data (tuple of input and labels)
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# clear the gradient
optimizer.zero_grad()
#feed the input and acquire the output from network
outputs = net(inputs)
#calculating the predicted and the expected loss
loss = criterion(outputs, labels)
#compute the gradient
loss.backward()
#update the parameters
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 1000 == 0:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
在每个 epoch,枚举器将获取下一组输入和相应标签的元组。在我们向网络模型馈送输入之前,我们需要清除之前的梯度。这是必需的,因为在反向过程(反向传播过程)之后,梯度将被累积而不是被替换。然后,我们将从预测输出和预期输出中计算损失。之后,我们将进行反向传播以计算梯度,最后,我们将更新参数。
这是训练过程的输出
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
步骤 4) 测试模型
在您训练了我们的模型之后,您需要用其他图像集来测试或评估它。
我们将为 test_loader 使用一个迭代器,它将生成一批图像和标签,这些图像和标签将被传递给训练好的模型。预测的输出将被显示并与预期输出进行比较。
#make an iterator from test_loader
#Get a batch of training images
test_iterator = iter(test_loader)
images, labels = test_iterator.next()
results = net(images)
_, predicted = torch.max(results, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
fig2 = plt.figure()
for i in range(4):
fig2.add_subplot(rows, columns, i+1)
plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]])
img = images[i] / 2 + 0.5 # this is to unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()
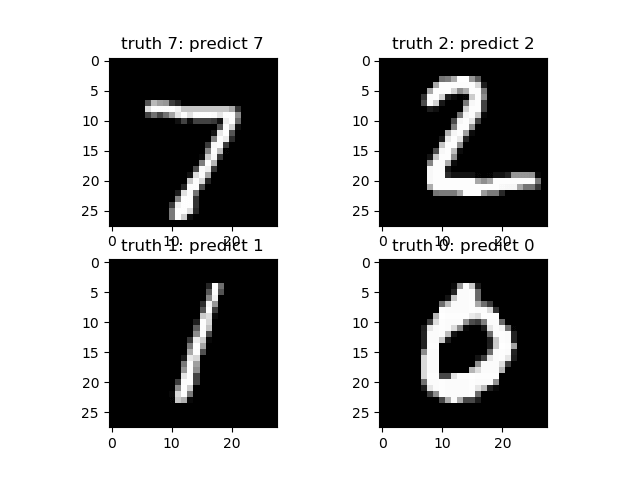
摘要
- PyTorch 是一个开源的、基于 Torch 的机器学习库,用于使用 Python 进行自然语言处理。
- PyTorch 的优点:1) 简单的库,2) 动态计算图,3) 更好的性能,4) 原生 Python
- PyTorch 对每个变量都使用张量,类似于 numpy 的 ndarray,但支持 GPU 计算。
- 学习深度学习基础知识的流行方法之一是使用 MNIST 数据集。