什么是 TensorFlow?它是如何工作的?简介与架构
让我们从 TensorFlow 介绍开始这个教程
什么是 TensorFlow?
TensorFlow 是一个用于创建机器学习应用程序的开源端到端平台。它是一个符号数学库,使用数据流和可微分编程来执行各种任务,专注于深度神经网络的训练和推理。它允许开发人员使用各种工具、库和社区资源来创建机器学习应用程序。
目前,世界上最著名的深度学习库是谷歌的 TensorFlow。谷歌在其所有产品中都使用机器学习来改进搜索引擎、翻译、图像字幕或推荐。
TensorFlow 示例
为了举一个具体的例子,谷歌用户可以通过 AI 体验更快、更完善的搜索体验。如果用户在搜索栏中输入一个关键字,谷歌会推荐下一个可能的词。

谷歌希望利用机器学习来利用其海量数据集,为用户提供最佳体验。有三个不同的群体使用机器学习:
- 研究人员
- 数据科学家
- 程序员
他们都可以使用相同的工具集进行协作,并提高效率。
谷歌拥有的不仅仅是任何数据;它们拥有世界上最大的计算机,因此 Tensor Flow 被构建为可扩展的。TensorFlow 是由 Google Brain Team 开发的一个库,用于加速机器学习和深度神经网络研究。
它被构建为可以在多个 CPU 或 GPU 甚至移动操作系统上运行,并且它在 Python、C++ 或 Java 等多种语言中都有包装器。
TensorFlow 的历史
几年前,当处理海量数据时,深度学习开始超越所有其他机器学习算法。谷歌发现它可以使用这些深度神经网络来改进其服务。
- Gmail
- 照片
- 谷歌搜索引擎
他们构建了一个名为 **Tensorflow** 的框架,让研究人员和开发人员能够在一个 AI 模型上进行协作。一旦开发和扩展,它就允许许多人使用它。
它于 2015 年底首次公开,而第一个稳定版本出现在 2017 年。它根据 Apache 开源许可证开源。您可以免费使用、修改和重新分发修改版本,而无需向 Google 支付任何费用。
在接下来的 TensorFlow 深度学习教程中,我们将学习 TensorFlow 架构以及 TensorFlow 如何工作。
TensorFlow 如何工作
TensorFlow 使您能够构建数据流图和结构,通过将多维数组(称为 Tensor)作为输入来定义数据如何在图中移动。它允许您构建一个可以对这些输入执行的操作流程图,输入从一端进入,然后通过这个多操作系统,从另一端输出。
TensorFlow 架构
Tensorflow 架构分为三个部分:
- 数据预处理
- 构建模型
- 模型训练和评估
它之所以被称为 TensorFlow,是因为它将输入作为多维数组,也称为 **张量**。您可以构建一个您想对该输入执行的操作 **流程图**(称为 Graph)。输入从一端进入,然后通过这个多操作系统流动,并从另一端输出。
这就是为什么它被称为 TensorFlow,因为张量进入它,流过一系列操作,然后从另一侧出来。
TensorFlow 可以在哪里运行?
TensorFlow 的硬件和 软件要求 可分为:
开发阶段:这是您训练模型的时候。训练通常在您的台式机或笔记本电脑上进行。
运行阶段或推理阶段:训练完成后,TensorFlow 可以在许多不同的平台上运行。您可以在以下平台上运行它:
- 运行 Windows、macOS 或 Linux 的桌面
- 云作为一项网络服务
- 移动设备,如 iOS 和 Android
您可以跨多台机器进行训练,然后在训练好的模型后,在另一台机器上运行它。
模型可以在 GPU 和 CPU 上进行训练和使用。GPU 最初是为视频游戏设计的。在 2010 年底,斯坦福大学的研究人员发现 GPU 在矩阵运算和代数运算方面也非常出色,因此它们在执行这类计算时速度非常快。深度学习依赖于大量的矩阵乘法。TensorFlow 在计算矩阵乘法方面速度非常快,因为它是用 C++ 编写的。尽管它是用 C++ 实现的,但 TensorFlow 可以通过其他语言(主要是 Python)进行访问和控制。
最后,TensorFlow 的一个重要特性是 TensorBoard。TensorBoard 可以图形化地、可视化地监控 TensorFlow 的运行情况。
TensorFlow 组件
张量
Tensorflow 的名称直接来源于其核心框架:**张量**。在 Tensorflow 中,所有计算都涉及张量。张量是 n 维的**向量**或**矩阵**,代表所有类型的数据。张量中的所有值都持有相同的、已知(或部分已知)**形状**的数据类型。数据的形状是矩阵或数组的维度。
张量可以源自输入数据或计算结果。在 TensorFlow 中,所有操作都在一个**图**内进行。图是一系列连续发生的计算。每个操作称为一个**op 节点**,它们相互连接。
图概述了操作和节点之间的连接。但是,它不显示值。节点边缘是张量,即填充操作数据的媒介。
图
TensorFlow 使用图框架。该图收集并描述了训练期间进行的所有系列计算。图有很多优点:
- 它被设计为在多个 CPU 或 GPU 甚至移动操作系统上运行。
- 图的可移植性允许保存计算以供立即或将来使用。图可以保存以供将来执行。
- 图中的所有计算都是通过连接张量来完成的。
- 张量有一个节点和一个边。节点承载数学运算并产生端点输出。边解释了节点之间的输入/输出关系。
为什么 TensorFlow 如此受欢迎?
TensorFlow 是最好的库,因为它对所有人都是可访问的。Tensorflow 库包含了不同的 API,可以构建如 CNN 或 RNN 等大规模深度学习架构。TensorFlow 基于图计算;它允许开发人员通过 Tensorboad 可视化神经网络的构建。此工具有助于调试程序。最后,Tensorflow 被构建为可以大规模部署。它可以在 CPU 和 GPU 上运行。
与其他的深度学习框架相比,Tensorflow 在 GitHub 上吸引了最大的关注度。
TensorFlow 算法
以下是 TensorFlow 支持的算法:
目前,TensorFlow 1.10 为以下内容提供了内置 API:
- 线性回归:tf.estimator.LinearRegressor
- 分类:tf.estimator.LinearClassifier
- 深度学习分类:tf.estimator.DNNClassifier
- 深度学习一键深度:tf.estimator.DNNLinearCombinedClassifier
- 提升树回归:tf.estimator.BoostedTreesRegressor
- 提升树分类:tf.estimator.BoostedTreesClassifier
TensorFlow 中的计算如何工作
import numpy as np import tensorflow as tf
在代码的前两行,我们已将 tensorflow 导入为 tf。使用 Python,将库简称为常见的做法。这样做的优点是避免在需要使用库时输入完整的库名称。例如,我们可以导入 tensorflow 并将其命名为 tf,然后在使用 tensorflow 函数时调用 tf。
让我们通过简单的 TensorFlow 示例来练习 TensorFlow 的基本工作流程。让我们创建一个将两个数字相乘的计算图。
在示例中,我们将 X_1 和 X_2 相乘。Tensorflow 将创建一个节点来连接操作。在我们的示例中,它被称为 multiply。当图确定后,Tensorflow 的计算引擎将把 X_1 和 X_2 相乘。
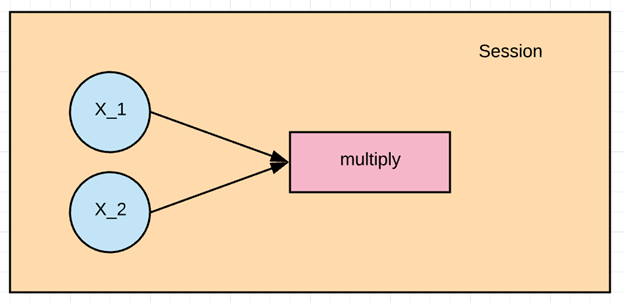
最后,我们将运行一个 TensorFlow 会话,该会话将使用 X_1 和 X_2 的值运行计算图,并打印乘法结果。
让我们定义 X_1 和 X_2 输入节点。当我们在 Tensorflow 中创建节点时,我们必须选择要创建的节点类型。X1 和 X2 节点将是占位符节点。占位符为每次计算分配一个新值。我们将它们创建为 TF 点占位符节点。
步骤 1:定义变量
X_1 = tf.placeholder(tf.float32, name = "X_1") X_2 = tf.placeholder(tf.float32, name = "X_2")
当我们创建占位符节点时,我们必须传入数据类型。我们将在此处添加数字,因此我们可以使用浮点数据类型,让我们使用 tf.float32。我们还需要为该节点指定一个名称。当我们在模型的可视化图表中查看时,此名称将会显示。让我们通过传递一个名为 name 的参数并将其值设置为 X_1 来命名此节点,然后我们以相同的方式定义 X_2。X_2。
步骤 2:定义计算
multiply = tf.multiply(X_1, X_2, name = "multiply")
现在我们可以定义执行乘法运算的节点。在 Tensorflow 中,我们可以通过创建 tf.multiply 节点来做到这一点。
我们将把 X_1 和 X_2 节点传递给乘法节点。这告诉 tensorflow 在计算图中链接这些节点,所以我们要求它获取 x 和 y 的值并相乘。我们还给乘法节点命名为 multiply。这就是我们简单计算图的全部定义。
步骤 3:执行操作
要执行图中的操作,我们必须创建一个会话。在 Tensorflow 中,这是通过 tf.Session() 完成的。现在我们有了会话,我们可以通过调用 session 来让会话在我们的计算图上运行操作。要运行计算,我们需要使用 run。
当加法运算运行时,它会发现需要获取 X_1 和 X_2 节点的值,所以我们也需要为 X_1 和 X_2 提供值。我们可以通过提供一个名为 feed_dict 的参数来实现。我们将 1,2,3 作为 X_1 的值,将 4,5,6 作为 X_2 的值。
我们使用 print(result) 打印结果。我们应该看到 4、10 和 18,分别对应 1×4、2×5 和 3×6。
X_1 = tf.placeholder(tf.float32, name = "X_1")
X_2 = tf.placeholder(tf.float32, name = "X_2")
multiply = tf.multiply(X_1, X_2, name = "multiply")
with tf.Session() as session:
result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
print(result)
[ 4. 10. 18.]
将数据加载到 TensorFlow 的选项
在训练 机器学习算法 之前的第一个步骤是加载数据。有两种常用的加载数据方式:
1. **将数据加载到内存中**:这是最简单的方法。您将所有数据作为一个数组加载到内存中。您可以编写 Python 代码。这些代码行与 Tensorflow 无关。
2. **Tensorflow 数据管道**:Tensorflow 具有内置 API,可以帮助您轻松加载数据、执行操作并向机器学习算法提供数据。此方法效果非常好,尤其是在您拥有大型数据集时。例如,图像记录以巨大且不适合内存而闻名。数据管道会自行管理内存。
使用什么解决方案?
加载数据到内存
如果您的数据集不是太大,即小于 10 GB,您可以使用第一种方法。数据可以放入内存。您可以使用一个名为 Pandas 的著名库来导入 CSV 文件。您将在下一个教程中了解更多关于 pandas 的信息。
使用 Tensorflow 数据管道加载数据
第二种方法最适用于您拥有大型数据集。例如,如果您有一个 50 GB 的数据集,而您的计算机只有 16 GB 的内存,那么机器就会崩溃。
在这种情况下,您需要构建一个 Tensorflow 数据管道。该数据管道将批量或小块地加载数据。每个批次将推送到数据管道并准备好进行训练。构建数据管道是一个很好的解决方案,因为它允许您使用并行计算。这意味着 TensorFlow 将跨多个 CPU 训练模型。它促进了计算,并允许训练强大的神经网络。
您将在接下来的教程中了解如何构建一个重要的数据管道来为您的神经网络提供数据。
总而言之,如果您有一个小型数据集,您可以使用 Pandas 库将数据加载到内存中。
如果您有一个大型数据集并希望利用多个 CPU,那么使用 Tensorflow 数据管道会更方便。
如何创建 TensorFlow 数据管道
以下是创建 TensorFlow 数据管道的步骤:
在之前的示例中,我们手动添加了三个 X_1 和 X_2 的值。现在,我们将学习如何将数据加载到 Tensorflow 中。
步骤 1:创建数据
首先,让我们使用 numpy 库生成两个随机值。
import numpy as np x_input = np.random.sample((1,2)) print(x_input)
[[0.8835775 0.23766977]]
步骤 2:创建占位符
与前面的示例一样,我们创建一个名为 X 的占位符。我们需要显式指定张量的形状。在这种情况下,我们将加载一个只包含两个值的数组。我们可以将形状写为 shape=[1,2]。
# using a placeholder x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
步骤 3:定义数据集方法
接下来,我们需要定义数据集,在其中填充占位符 x 的值。我们需要使用 tf.data.Dataset.from_tensor_slices 方法。
dataset = tf.data.Dataset.from_tensor_slices(x)
步骤 4:创建数据管道
在第四步中,我们需要初始化数据将流经的数据管道。我们需要创建一个带 make_initializable_iterator 的迭代器。我们将其命名为 iterator。然后我们需要调用此迭代器来提供下一个数据批次,get_next。我们将其命名为 get_next。请注意,在我们的示例中,只有一个数据批次,只包含两个值。
iterator = dataset.make_initializable_iterator() get_next = iterator.get_next()
步骤 5:执行操作
最后一步与前面的示例类似。我们初始化一个会话,并运行操作迭代器。我们将 feed_dict 与由 numpy 生成的值一起填充。这两个值将填充占位符 x。然后我们运行 get_next 来打印结果。
with tf.Session() as sess:
# feed the placeholder with data
sess.run(iterator.initializer, feed_dict={ x: x_input })
print(sess.run(get_next)) # output [ 0.52374458 0.71968478]
[0.8835775 0.23766978]
摘要
- TensorFlow 含义:TensorFlow 是近些年来最著名的深度学习库。使用 TensorFlow 的从业者可以构建任何深度学习结构,例如 CNN、RNN 或简单的神经网络。
- TensorFlow 主要被学术界、初创公司和大型公司使用。谷歌几乎在所有谷歌日常产品中都使用 TensorFlow,包括 Gmail、Photo 和 Google Search Engine。
- Google Brain 团队开发 TensorFlow 是为了弥合研究人员和产品开发人员之间的差距。2015 年,他们公开了 TensorFlow;它正迅速普及。如今,TensorFlow 是 GitHub 上拥有最多存储库的深度学习库。
- 从业人员使用 Tensorflow 是因为它易于大规模部署。它内置可在云端或 iOS 和 Android 等移动设备上运行。
Tensorflow 在会话中工作。每个会话都由一个具有不同计算的图定义。一个简单的例子可以是两个数字相乘。在 Tensorflow 中,需要三个步骤:
- 定义变量
X_1 = tf.placeholder(tf.float32, name = "X_1") X_2 = tf.placeholder(tf.float32, name = "X_2")
- 定义计算
multiply = tf.multiply(X_1, X_2, name = "multiply")
- 执行操作
with tf.Session() as session:
result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
print(result)
Tensorflow 的一个常见做法是创建数据管道来加载数据。如果您遵循这五个步骤,您将能够将数据加载到 TensorFLow 中。
- 创建数据
import numpy as np x_input = np.random.sample((1,2)) print(x_input)
- 创建占位符
x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
- 定义数据集方法
dataset = tf.data.Dataset.from_tensor_slices(x)
- 创建数据管道
iterator = dataset.make_initializable_iterator() get_next = iterator.get_next()
- 执行程序
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict={ x: x_input })
print(sess.run(get_next))