Perl 教程
什么是 Perl?
Perl 是一种高级、通用、解释型、动态编程语言。Perl 是“Practical Extraction and Reporting Language”(实用提取和报告语言)的缩写,尽管 Perl 并没有官方的缩写。它由 Larry Wall 于 1987 年推出。Perl 语言最初是专门为文本编辑设计的。但现在,它被广泛用于各种目的,包括 Linux 系统管理、网络编程、Web 开发等。
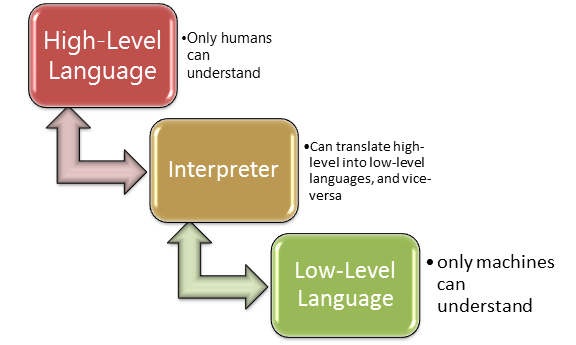
让我们简单地解释一下。虽然计算机只理解 0 和 1(二进制语言/机器语言/[低级语言]),但对我们人类来说,用二进制语言编程非常困难。Perl 是一种使用自然语言元素(普通英语中使用的词语)的编程语言,因此人类更容易理解(高级语言)。现在有一个问题:计算机无法理解我们人类容易理解的高级语言。为此,我们需要某种可以将高级语言翻译成低级语言的东西。这时解释器就派上用场了。解释器是一段软件,它将用高级语言编写的程序转换为低级语言,以便计算机理解和执行程序中编写的指令。因此,Perl 是一种解释型编程语言。
Perl 在哪里使用?
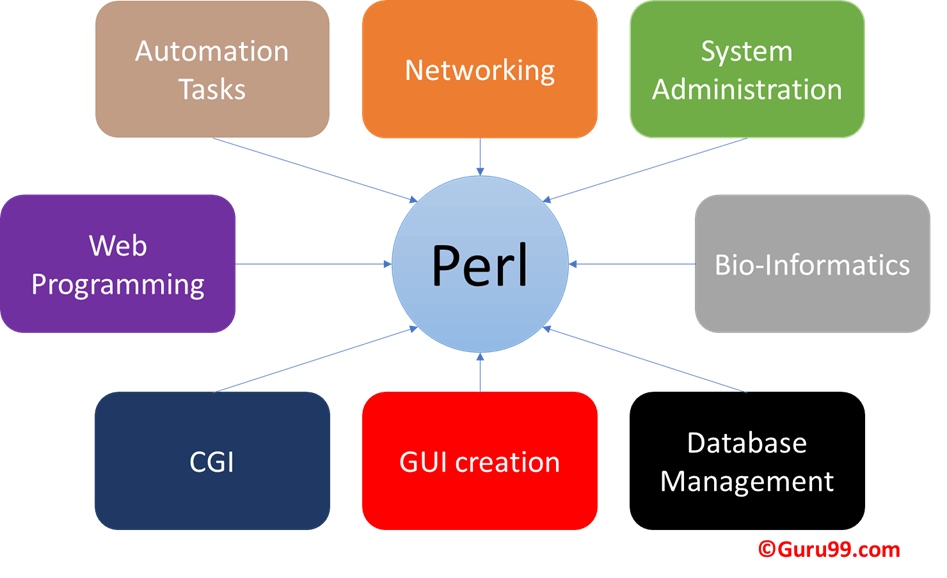
Perl 脚本语言的强大功能可以在许多领域实现。Perl 最流行的用途是 Web 开发。Perl 也用于自动化 Web 服务器中的许多任务和其他管理工作,它可以自动生成电子邮件和清理系统。Perl 仍然用于其最初的目的,即提取数据和生成报告。它可以生成资源使用报告并检查网络中的安全问题。由于这个原因,Perl 已成为 Web 开发、网络和生物信息学中流行的语言。除了所有这些,Perl 还可以用于 CGI 编程。
Perl 还可以用于图像创建和处理。除此之外,通过 telnet、FTP 等进行网络连接、创建图形用户界面、VLSI 电子设备以及创建邮件过滤器以减少垃圾邮件实践都是 Perl 的一些用例。
Perl 还以实现 OOP(面向对象编程)实践而闻名,并支持所有形式的继承(简单、多重和菱形)、多态性和封装。Perl 足够灵活,可以同时支持过程式和 OOP 实践。Perl 还有额外的模块,允许您在 Perl 脚本中编写或使用/重用用 Python、PHP、PDL、TCL、Octave、Java、C、C++、Basic、Ruby 和 Lua 编写的代码。这意味着您可以将 Perl 与这些额外的编程语言结合使用,而不是重写现有代码。
Perl 编程语言的应用
为什么要使用 Perl?
确实有其他编程语言可以完成上述所有工作,那么您为什么要专门使用 Perl 呢?Perl 非常容易学习,特别是如果您有计算机编程背景的话。Perl 的设计宗旨是让人类易于编写和理解,而不是让计算机易于处理。它使用正则表达式。其自然的语言风格不同于其他使用特定语法和句法的编程语言;因此,Perl 非常灵活,不会强加给您任何特定的解决问题或思考解决方案的方式。Perl 具有极高的可移植性。它可以在任何安装了 Perl 解释器的操作系统上运行,因此它是平台无关的。所有 Linux 操作系统都预装了 Perl,因此您可以开箱即用地在 Linux 中开始 Perl 编码。这与 Shell 脚本不同,Shell 脚本的代码会随着所使用的 Linux 发行版而变化,使其可移植性越来越差。Perl 中的小型特定任务变得非常简单快捷。通过本面向初学者的 Perl 教程,您将学习如何为特定任务编写小型快速程序。让我们以经典的 Hello World 程序为例,它用于学习任何以 UNIX 为根基的编程语言。
示例:Perl hello world

#!/usr/bin/perl print "Hello, world!";
输出
Hello, world!
上面两行代码将打印 Hello, world! 是不是很简单快捷?有 C、C++ 知识的学生会知道,在这些语言中获得相同的输出需要更多的代码行。
您可能想知道为什么 Perl 在 Web 上如此出名。很简单,因为网络上发生的大部分事情都是文本,而 Perl 非常擅长文本处理。如果我们将 Perl 与任何其他语言进行比较,那么 Perl 将是文件处理、文本处理和输出报告方面最好的语言。
Perl 最好的优点之一是它免费使用
Perl 社区坚信软件应该免费提供、免费修改和免费分发。来自 Perl 社区的几位志愿者致力于使该编程语言尽可能完善。
Perl 的优缺点
| 优点 | 缺点 |
|---|---|
|
|
|
|
|


让我们开始吧
对 Perl 的历史和 Perl 编码所需的计算机编程基本概念有了足够的了解后,是时候深入并开始学习 Perl 了。下一章将教您如何在系统上设置 Perl 并为 Perl 编码之旅做好准备。本 Perl 脚本教程将以 Linux 作为学生用于 Perl 编码的操作系统。
下载并安装 Perl – Windows、Mac 和 Linux
如何获取 Perl?
好消息是您可能已经拥有了它!
但是如果您在系统上找不到它,您仍然可以免费获得它。
要查找您是否已安装 Perl,请进入命令行并输入:perl -v
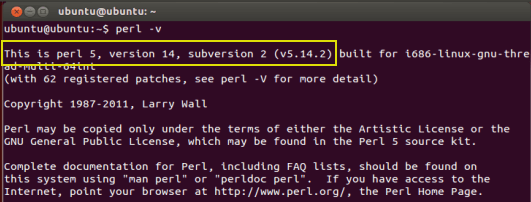
如果 Perl 已安装,该命令将显示 Perl 的版本。在此示例中,版本为 v5.14.2。但如果没有……不要惊慌……
Unix
|
已安装 预装了 Perl,但您可能需要更新到最新版本。 |
Mac OS 
|
已安装 OSX 预装了 Perl,尽管您可能需要更新到最新版本。 |
Windows
|
需要安装 两种选择可用
|
在 Linux 上更新 Perl
如果您需要更新 Perl 版本,只需输入一行命令:
sudo apt-get install perl
然后放松。其余的将自动完成。只需确保您有活跃的互联网连接。

在 Windows 上安装 perl
首先,从这个链接下载 Active Perl。按照以下步骤在 Windows 系统上安装 ActivePerl。请参见下面的屏幕截图。
步骤 1:下载安装程序并开始安装后,您将看到以下窗口,点击“下一步”继续。
步骤 2:接受许可协议以继续安装。
步骤 3:以下是即将安装的不同软件包。默认情况下,所有都将被选中。唯一不同的是 PPM(Perl 包管理器)。这是 Active Perl 提供的一个实用程序,用于在您的系统中安装外部 Perl 模块或库。点击“下一步”继续。
步骤 4:这些是可用于 Perl 的不同类型的 Perl 扩展。我们主要将 .Pl、.Plx 和 .Pm 用于 Perl。Perl 模块通常使用 .Pm 作为其文件扩展名来引用库文件。选择所有选项并点击“下一步”按钮。
步骤 5:点击“安装”按钮继续安装。
步骤 6:安装完成后,执行命令 'Perl -v' 检查 Perl 是否已成功安装在您的系统中。
对于在 Linux 和 Windows 中设置 Perl 环境,还有很多需要讨论的地方,因为此安装中不会包含许多库文件。您需要手动安装这些文件。您可以使用 CPAN(Comprehensive Perl Archive Network)或 PPM 手动安装这些文件,PPM 仅适用于 Windows 上的 Perl。但这些文件对于开始 Perl 编码来说并非强制性的。
除了此 Windows 设置外,您还可以使用 Windows 10 的新功能,即 Windows 上的 Linux 子系统,并用它来运行 Perl 代码。
第一个 Perl 程序
Hello world!
Perl 示例:Hello World
#!/usr/bin/perl -w #this is just a comment… print "Hello World";
如果您不理解这段文字,请不要担心。很快一切都会清楚的。来吧,逐行看一看
#!/usr/bin/perl
这告诉操作系统使用位于 /usr/bin/perl 的程序执行此文件。有些 IDE 不需要这一行。如果它很重要,您必须在此处写入解释器的路径。记住!这一特殊行必须在程序的开头,并且必须以 #! 开头。使用 warnings; 这是另一个特殊命令,它告诉解释器显示任何警告,即 -w,它全局激活警告。
print "Hello World";
print 指令将文本写入屏幕。行尾的分号告诉 perl 解释器指令已完成。您必须在 Perl 代码中每个指令的末尾放置一个分号。请注意引号(“)。它对于 print 指令是必需的。将上述脚本保存为 firstprog.pl
在 Windows 上
如果您安装了 Strawberry,只需点击“运行”即可。您也可以运行命令行界面并在控制台上输入
C:\> perl path\firstprog.pl
或者,如果 perl.exe 不在您的路径中
C:\> c:\perl\bin\perl.exe firstprog.pl
在 Linux/Unix 上
您只需打开终端并输入
perl firstprog.pl
如果您无法运行该程序,请确保您有运行它的权限。在终端中输入
chmod +x firstprog.pl
您的程序现在可执行并准备运行。要执行,请写入
./firstprog
安装 cpan 减号模块
模块是一组用于执行多个程序中常见操作的代码。如果您使用 Perl 模块,则无需重写代码来执行相同的操作。Perl 可以利用这样的外部代码库。最好的库之一是 CPAN。它代表综合 Perl 档案网络,包含大量可供您使用的 Perl 模块。它是一个由大量开发人员组成的社区或网络,他们贡献此类模块。通过在您的 Perl 模块中安装对 CPAN 模块的支持,您可以利用 CPAN 模块并简化您的工作。大多数 Perl 模块是用 Perl 编写的,有些使用 XS(它们是用 C 编写的),因此需要 C 编译器(这很容易设置——不要惊慌。模块可能依赖于其他模块(几乎总是在 CPAN 上),并且没有它们(或没有它们的特定版本)无法安装。值得仔细阅读下面选项的文档。CPAN 上的许多模块现在需要最新版本的 Perl(版本 5.8 或更高版本)。安装 cpanminus 脚本,用于从 CPAN 获取、解包、构建和安装模块,以简化其他模块的安装(您稍后会感谢我们)。要安装 App-cpanminus Perl 模块,请在命令行中键入
cpan App::cpanminus
cpan App::cpanminus 确保在下载和安装 perl 模块时有互联网连接。

现在安装任何模块
cpan –i <Module_Name>.
让我们看一个安装模块 File::Data(这是一个访问文件数据的接口)的例子。
Perl 变量
现在,我们来谈谈变量。您可以将变量想象成一种容器,它容纳一个或多个值。一旦定义,变量的名称保持不变,但值会反复变化。
变量有 3 种类型
Perl 中的变量类型
最简单的是标量,这就是我们今天的主题
标量变量
这种类型的变量只保存一个值。
它的名称以美元符号和 Perl 标识符(这是我们变量的名称)开头。

Perl 中的标量变量
命名约定
如果您熟悉其他编程语言,那么您会知道变量命名有一些规则。同样,Perl 有三个标量命名规则。
- 所有标量名称都将以 $ 开头。很容易记住在每个名称前加上 $。可以将其想象为 $标量。
- 像 PHP 一样,在第一个特殊字符 $ 之后,Perl 允许使用字母数字字符,即 a 到 z、A 到 Z 和 0 到 9。也允许使用下划线字符。使用下划线将变量名分成两个单词。“但第一个字符不能是数字”
- 尽管数字可以是名称的一部分,但它们不能紧跟在 $ 之后。这意味着 $ 之后的第一个字符必须是字母或下划线。来自 C/C++ 背景的人应该能够立即认识到这种相似性。示例
Perl 示例
$var; $Var32; $vaRRR43; $name_underscore_23;
然而,这些不是合法的标量变量名称。
mohohoh # $ character is missing $ # must be at least one letter $47x # second character must be a letter $variable! # you can't have a ! in a variable name
一般规则是,当 Perl 只有某个东西的一个时,它就是一个标量。标量可以从设备中读取,我们可以将其用于我们的程序。
两种标量数据类型
- 数字
- 字符串
数字
在这种标量数据类型中,我们可以指定
- 整数,简单来说就是整数,比如 2, 0, 534
- 浮点数,即实数,比如 3.14, 6.74, 0.333

注意:通常,Perl 解释器将整数视为浮点数。例如,如果您在程序中写入 2,Perl 会将其视为 2.0000
整数字面量
它由一个或多个数字组成,可选地前面带有加号或减号,并包含下划线。
Perl 示例
0; -2542; 4865415484645 #this also can be written with underscores (for clarity) : 4_865_415_484_645
如您所见——没什么特别的。但相信我,这是最常见的标量类型。它们无处不在。
浮点字面量
它由数字组成,可选地带减号、小数点和指数。
Perl 示例
3.14; 255.000; 3.6e20; # it's 3.6 times 10 to the 20th -3.6e20; # same as above, but negative -3.6e-20; #it's negative 3.6 times 10 to the -20th -3.6E-20; #we also can use E – this means the same the lowercase version -3.6e-20
八进制、十六进制和二进制表示
它是十进制系统的替代方案。让我向您展示八进制、十六进制和二进制表示。一个简短的表格介绍了这种奇怪风格的所有重要信息
| 表示 | 基础 | 前缀 |
|---|---|---|
| 八进制 | 8 | 0 (零) |
| 十六进制 | 16 | 0x |
| 二进制 | 2 | 0b |
Perl 示例
255; # 255 in decimal notation 0377; # 255 in octal notation 0xff; # 255 in hexadecimal notation 0b11111111; # 255 in binary notation
所有这些值对 Perl 来说都意味着相同。Perl 不会以相同的格式存储这些值。它将内部将这些十六进制、二进制、八进制值转换为十进制值。
赋值是标量最常见的操作,而且非常简单。Perl 为此使用等号。它从右侧获取表达式的值并将其放入我们的变量中。
让我们看一些例子
$size=15; # give $size value of 15 $y = -7.78; # give $y value of -7.78
此外,您不仅可以将数字,还可以将表达式放入变量中。
$z = 6 + 12 # give $z value of 18
字符串
字符串:它也是一种非常简单的标量类型。
Perl 中字符串的最大长度取决于计算机的内存量。字符串的大小没有限制,任意数量的字符、符号或单词都可以构成您的字符串。最短的字符串没有字符。最长的字符串可以填满所有系统内存。Perl 程序可以完全用 7 位 ASCII 字符集编写。Perl 还允许您在字符串字面量中添加任何 8 位或 16 位字符集,即非 ASCII 字符。Perl 还增加了对 Unicode UTF-8 的支持。

像数字一样,字符串也有两种不同类型
- 单引号字符串字面量
- 双引号字符串字面量
单引号字符串字面量
单引号用于封装您希望按字面意思取用的数据。一个简短的例子,一切都应该清楚了
Perl 示例
#!/usr/bin/perl $num = 7; $txt = 'it is $num'; print $txt;
输出
它是 $num
这里由于单引号,不取 $num 的值,而是将字面字符 '$'、'n'、'u' 和 'm' 添加到 $txt 的值中。
双引号字符串字面量
双引号用于封装需要先进行插值再处理的数据。这意味着转义字符和变量不会简单地按字面意思插入到后续操作中,而是在现场进行评估。转义字符可用于插入换行符、制表符等。
Perl 示例
$num = 7; $txt = "it is $num"; print $txt;
输出
它是 7
这里由于双引号,取 $num 的值并添加到 $txt 的值中
双引号会对标量和数组变量进行插值,但不会对哈希进行插值。另一方面,您可以使用双引号对数组和哈希的切片进行插值。
神秘的 \n
考虑以下程序
Perl 示例
print "hello \n";
输出
你好
Perl 不仅显示“hello\n”,还只显示“hello”。为什么?因为“\n”是一个特殊符号,表示您在程序中显示文本时希望换行。print “hello\n new line”; 下一个问题——还有其他特殊符号吗?是的,有!但别担心——只有几个。请查看下表
| 构造 | 描述 |
|---|---|
| \n | 换行 |
| \r | 回车 |
| \t | 制表符 |
| \f | 换页 |
| \b | 退格 |
| \a | 响铃 |
| \e | 转义 |
| \007 | 任何八进制 ASCII 值(此处为 007 = 响铃) |
| \x7f | 任何十六进制值(此处为 7f = 删除) |
| \\ | 反斜杠 |
| \” | 双引号 |
| \l | 下一个字母小写 |
| \L | 直到 \E,所有后续字母小写 |
| \u | 下一个字母大写 |
| \U | 直到 \E,所有后续字母大写 |
| \E | 终止 \L, \U |
我知道,不是“只有几个”……但相信我,你只需要知道
字符串变量
这与我们在数字赋值中看到的操作相同。Perl 从等号的右侧获取我们的字符串,并将该字符串放入变量中。
Perl 示例
$string = 'tutorial'; # give $string the eight-character string 'tutorial' print $string; $string = $size + 3 ; # give $string the current value of $size plus 3 print $string; $string = $ string * 5; # multiplied $string by 5 print $string;
输出
教程315
如您所见,您可以将数字和字符串放在同一个变量中。没有变量类。
字符串连接(句点)
连接运算符“.”连接两个或多个字符串。记住!如果字符串包含引号、回车符、反斜杠,所有这些特殊字符都需要用反斜杠进行转义。
Perl ' ' 变量示例
#!/usr/bin/perl $a = "Tom is"; $b = "favorite cat"; $c = $a ." mother's ". $b; print $c;
输出
汤姆是妈妈最喜欢的猫
字符串
“$a”、“$b”使用“.”运算符连接并存储在“$c”中。
最后...
数字和字符串之间的转换
如您所知,Perl 会根据需要自动在数字和字符串之间进行转换。Perl 如何知道我们现在需要什么?这很简单——一切都取决于运算符(我们稍后会讨论运算符,现在,只需接受有很多运算符,数字和字符串的运算符不同)。如果运算符期望一个数字,Perl 会将值用作数字。如果运算符期望一个字符串,Perl 会将值用作字符串。换句话说——您无需担心这种转换。一个简短的例子,一切都应该清楚了。
Perl 示例
$string = "43"; $number = 28; $result = $string + $number; print $result;
输出
71
将 $string 的值转换为整数并添加到 $number 的值中。
加法的结果 71 被赋值给 $result。
变量的作用域——访问修饰符
我们可以在程序的任何地方声明一个标量。但您需要指定一个访问修饰符
有 3 种类型的修饰符
- 我的
- 局部
- 我们的
我的:使用它,您可以声明任何在块内(即花括号内)特定的变量。
#!/usr/bin/perl
my $var=5;
if(1)
{
my $var_2 =$var;
}
print $var_2;
无输出
程序的输出将为空!
在上面的例子中,您会看到声明了两个变量,一个在 if 块内部 ($var_2),另一个在 If 块外部 ($var)。在块外部声明的变量将可供 if 块访问,但在 if 块内部声明的变量将无法被外部程序访问。
局部:通过它,我们可以将相同的变量值实际地掩盖为不同的值,而不会真正改变变量的原始值。假设我们有一个变量 $a,其值为 5,您可以通过使用 local 关键字重新声明相同的变量来实际更改该变量的值,而不会改变变量的原始值 5。让我们通过一个示例看看它是如何工作的。
#!/usr/bin/perl
$var = 5;
{
local $var = 3;
print "local,\$var = $var \n";
}
print "global,\$var = $var \n";
上述程序的输出将是这种方式。
local, $var = 3
global, $var = 5
通过这种方式,我们可以更改变量的值,而不会影响原始值。
我们的:一旦变量用访问修饰符“our”声明,它就可以在整个包中使用。假设您有一个 Perl 模块或包 test.pm,其中有一个用作用域“our”声明的变量。此变量可以在任何使用该包的脚本中访问。
如果您认真对待 Perl 编程,您应该用以下内容开始您的程序
#!/usr/local/bin/perl
use strict;
这将帮助您编写更好、更简洁的代码。“use strict”会启用严格编译指示,这将强制您使用 my 关键字声明变量。
这是一个良好的编程实践
#!/usr/local/bin/perl use strict; $var = 10; print "$var";
结果:错误
#!/usr/local/bin/perl use strict; my $var = 10; print "$var";
输出
10
Perl 数组
什么是 Perl 数组?
数组是一种特殊类型的变量,它以列表的形式存储数据;每个元素都可以通过索引号访问,每个元素都有唯一的索引号。您可以在数组中存储数字、字符串、浮点值等。这看起来很棒,那么我们如何在 Perl 中创建数组呢?在 Perl 中,您可以使用“@”字符后跟您想要的名称来定义数组。让我们考虑在 Perl 中定义一个数组。
my @array;
这就是我们在 Perl 中定义数组的方式;您可能在想如何将数据存储到其中。有不同的方式将数据存储到数组中。这取决于您将如何使用它。
my @array=(a,b,c,d); print @array;
输出
abcd
这是一个包含 4 个元素的数组。
数组索引从 0 开始,到其声明的最大大小结束,在本例中,最大索引大小为 3。

Perl 数组示例
您也可以以上述方式声明数组;唯一的区别是,它将数据存储到数组中时将空格视为分隔符。在这里,qw() 表示 quote word。此函数的意义在于生成一个单词列表。您可以通过多种方式使用 qw 声明数组。
@array1=qw/a b c d/;
@array2= qw' p q r s';
@array3=qw { v x y z};
print @array1;
print @array2;
print @array3;
输出
abcdpqrsvxyz
假设您想为数组的第 5 个元素赋值,我们该怎么做呢?
$array [4] =’e’;
顺序数组
顺序数组是指您按顺序存储数据的数组。假设您想将 1-10 个数字或字母 a-z 存储到数组中。您可以尝试以下方式,而不是键入所有字母——
@numbers= (1..10); print @numbers; #Prints numbers from 1 to 10;
输出
12345678910
Perl 数组大小
我们有一个已经可用的数组,您不知道该数组的大小是多少,那么有什么可能的方法可以找到它呢?
@array= qw/a b c d e/; print $size=scalar (@array);
我们可以在不使用函数的情况下获取数组的大小吗?是的,可以。
@array= qw/a b c d e/; print $size=scalar (@array); print "\n"; print $size=$#array + 1; # $#array will print the Max Index of the array, which is 5 in this case
输出
5
5
动态数组
上述声明数组的方法称为静态数组,您知道数组的大小。
什么是动态数组?
动态数组是那些您在声明时未指定任何值的数组。那么我们到底什么时候将值存储到那个数组中呢?很简单,我们在运行时存储它们。这是一个简单的程序。
我们将使用一些内置的 Perl 函数来完成此任务。
my $string="This is a kind of dynamic array";
my @array;
@array=split('a',$string);
foreach(@array)
{
print "$_ \n”;
# This is a special variable which stores the current value.
}
输出
这是
动态的
类型
错误
ÿ
split 函数根据提供给它的分隔符将字符串内容分割成一个数组。在这种情况下,它还将从字符串中消除分隔符,即“a”;
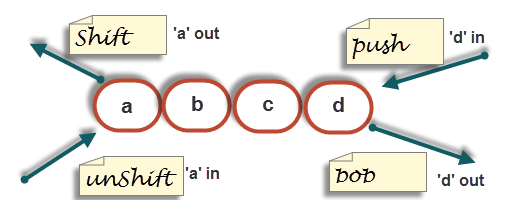
Perl 数组的 Push、Pop、shift、unshift
这些函数可以在 Perl 中用于添加/删除数组元素。
- Perl Push:在现有数组的末尾添加数组元素。
- Perl Pop:从数组中删除最后一个元素。
- Perl Shift:从数组中删除第一个元素。
- Perl Unshift:在数组的开头添加一个元素。
让我们看一个我们可以使用以下函数的例子。
@days = ("Mon","Tue","Wed");
print "1st : @days\n";
push(@days, "Thu"); # adds one element at the end of an array
print "2nd when push : @days\n";
unshift(@days, "Fri"); # adds one element at the beginning of an array
print "3rd when unshift : @days\n";
pop(@days);
print "4th when pop : @days\n"; # remove one element from the last of an array.
shift(@days); # remove one element from the beginning of an array.
print "5th when shift : @days\n";
输出
第一:周一周二周三
第二,当推时:周一周二周三周四
第三,当取消推时:周五周一周二周三周四
第四,当弹出时:周五周一周二周三
第五,当班次:周一周二周三
Perl 哈希
我们为什么需要哈希?
我们已经在前面的章节中学习了标量和数组。
标量到底做什么?它只存储整数和字符串。
数组到底做什么?它是一个标量集合,您可以使用索引访问数组的每个元素。但是,当您有成千上万条记录时,使用数组是个好主意吗?我们会忘记哪个索引有什么值。为了克服这种情况,我们有像 perl hash 这样的东西。
什么是哈希?
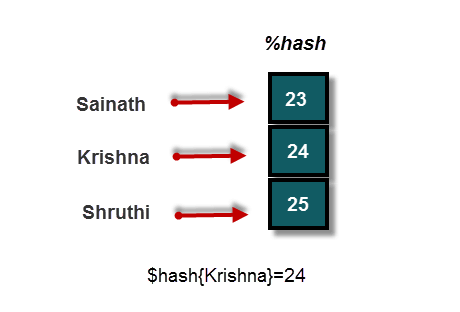
哈希也可以像数组一样存储多个标量。唯一的区别是我们没有索引,而是有键和值。哈希可以声明为以 % 开头,后跟哈希的名称。让我们看一个示例,了解如何在 Perl 中定义哈希以及如何将其与数组区分开来
考虑一个由三个人和他们的年龄组成的数组示例。
@array=('Sainath',23,'Krishna',24,'Shruthi',25); #This is how an array looks.
print @array;
输出
Sainath33Krishna24Shruthi25
这样很难知道每个人的年龄,因为我们需要记住所有人的姓名和年龄的索引位置。当只有 3 个姓名时可能很简单,但当有 1000 个或更多时呢?您知道答案。
我们可以使用哈希来克服这个问题。
哈希示例
print %hash=( 'Sainath' => 23, 'Krishna' => 24, 'Shruthi' => 25); # This is how we create a hash.
print %hash=('Sainath',23,'Krishna',24,'Shruthi',25);# This way of assigning is called list.
输出
Sainath33Krishna24Shruthi25Sainath33Krishna24Shruthi25
我们现在已经声明了一个哈希,太棒了!但是,我们如何访问或打印它呢?哈希中的每个元素都应使用其关联的键来访问,该键将有一个值被分配。因此,哈希中每个键和值之间都存在一对一的映射。
为了打印任何人的年龄,您只需要记住那个人的名字。
print $hash{'Krishna'}; # This how we should access a hash. Key enclosed within {}.
您可能想知道为什么我使用了 $hash{KeyName},记住哈希再次是标量的集合。所以,我们可以使用 $ 来表示标量来访问每个哈希元素。

注意:哈希中的每个键都应该是唯一的,否则它将覆盖您之前分配的值。
我们如何将一个哈希赋值给另一个哈希?很简单,就像我们对
我们也可以打印整个哈希。
%hash=( 'Tom' => 23); %newHash=%hash; # Assigning hash to a new hashprint %newHash; print %newHash;
输出
汤姆23
添加 Perl 哈希
如您所见,我们已经有一个哈希 %newHash,现在我们需要向其中添加更多条目。
$newHash{'Jim'}=25;
$newHash{'John'}=26;
$newHash{'Harry'}=27;
print %newHash;
输出
吉姆25约翰26哈里27
Perl 删除键
您可能希望从哈希中删除一个条目。我们可以这样做。
delete $newHash{'Jim'};#This will delete an entry from the hash.
Delete 是 Perl 的内置函数。这里,我们将看到一个将哈希赋值给数组的例子。
@array=%newHash; print "@array";
注意:无论何时打印哈希或将哈希存储到数组中。顺序可能总是不同。它并不总是相同的。
我们只能将哈希的键或值赋给数组。
@arraykeys= keys(%newHash); @arrayvalues=values(%newHash); print "@arraykeys\n"; print "@arrayvalues\n"; # \n to print new line.
要删除哈希中的所有条目,我们可以直接将哈希赋为 null。
%newHash=();# 这将重新定义哈希,使其不包含任何条目。
Perl 条件语句
我们可以在 Perl 中使用条件语句。那么什么是条件语句呢?条件语句是您实际检查代码中是否满足某些情况的语句。
想象一个例子,您正在购买一些水果,并且您不喜欢价格超过 100 美元。所以,这里的规则是 100 美元。
Perl 支持两种类型的条件语句:if 和 unless。
Perl If
如果条件为真,则执行 if 代码块。
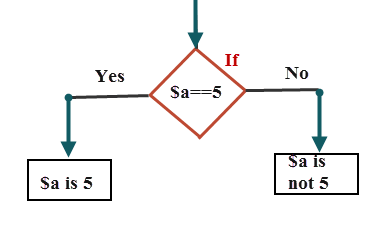
my $a=5;
if($a==5)
{
print "The value is $a";
}
输出
5
Perl If Else
这看起来不错。让我们考虑一下 $a 不等于 5 的情况。
my $a=10;
if($a==5)
{
print "The values is $a ---PASS";
}
else
{
print "The value is $a ---FAIL";
}
输出
值为 10 —失败
这样我们一次只能控制一个条件。这是限制吗?不,您也可以使用 if… elsif … else 控制各种条件。
Perl Else If
my $a=5;
if($a==6)
{
print "Executed If block -- The value is $a";
}
elsif($a==5)
{
print "Executed elsif block --The value is $a";
}
else
{
print "Executed else block – The value is $a";
}
输出
执行 elsif 块 – 值为 5
在上述情况下,由于 $a 等于 5,将执行 elsif 块。
可能存在 if 和 elsif 代码块都失败的情况。在这种情况下,将执行 else 代码块。如果您不喜欢包含 else 代码检查,可以将其删除。
Perl 嵌套 If
在这种情况下,您可以在一个 if 代码块中使用另一个 if 代码块。
my $a=11; #Change values to 11,2,5 and observe output
if($a<10){
print "Inside 1st if block";
if($a<5){
print "Inside 2nd if block --- The value is $a";
}
else{
print " Inside 2nd else block --- The value is $a";
}
}
else{
print "Inside 1st else block – The value is $a";
}
输出
在第一个 else 块内 – 值为 11
通过更改 $a 的值来执行相同的代码;您可以找出其余部分。
Perl Unless
您已经了解了 if 的作用(如果条件为真,它将执行代码块)。Unless 与 if 相反,除非条件为假,否则 unless 代码块将执行。
my $a=5;
unless($a==5)
{
print "Inside the unless block --- The value is $a";
}
else
{
print "Inside else block--- The value is $a";
}
输出
在第一个 else 块内 – 值为 5
猜猜输出会是什么。您猜对了!!!!!。输出将是 else 块的打印语句。因为 unless 代码块中的条件为真,记住除非条件为假,否则 unless 块才会执行。更改 $a 的值并执行代码,您将看到差异。
Perl 使用 if
$a= " This is Perl";
if($a eq "SASSDSS"){
print "Inside If Block";
}
else
{
print "Inside else block"
}
输出
在 else 块内
除非
$a= " This is Perl";
unless($a eq "SASSDSS"){
print "Inside unless Block";
}
else
{
print "Inside else block"
}
输出
除非块内
Perl 循环 – 控制结构
Perl 支持与其他编程语言类似的控制结构。Perl 支持四种类型的控制结构:for、foreach、while 和 until。我们使用这些语句来重复执行某些代码。
For 循环 Perl
For 代码块将执行直到条件满足。让我们以如何使用 Perl 循环数组为例。
my @array=(1..10);
for(my $count=0;$count<10;$count++)
{
print "The array index $count value is $array[$count]";
print "\n";
}
输出
数组索引 0 的值为 1
数组索引 1 的值为 2
数组索引 2 的值为 3
数组索引 3 的值为 4
数组索引 4 的值为 5
数组索引 5 的值为 6
数组索引 6 的值为 7
数组索引 7 的值为 8
数组索引 8 的值为 9
数组索引 9 的值为 10
在这里,for () 表达式中包含许多语句。每个语句都有其含义。
for ( 初始化 ; 条件; 递增)
这是使用 for 的另一种方式。
for(1..10)
{
print "$_ n";
print "\n";
}
输出
1n
2n
3n
4n
5n
6n
7n
8n
9n
10n
Perl Foreach
foreach 语句的使用方式与 for 相同;主要区别在于我们没有条件检查和增量。
让我们以 foreach perl 为例。
my @array=(1..10);
foreach my $value (@array)
{
print " The value is $value\n";
}
输出
值为 1
值为 2
值为 3
值为 4
值为 5
值为 6
值为 7
值为 8
值为 9
值为 10
Foreach 取数组的每个元素,并在每次迭代时将该值赋给 $var。我们也可以使用 $_ 来达到同样的目的。
my @array=(1..10);
foreach(@array)
{
print " The value is $_ \n"; # This is same as the above code.
}
输出
值为 1
值为 2
值为 3
值为 4
值为 5
值为 6
值为 7
值为 8
值为 9
值为 10
这对于访问数组来说不错。那么哈希呢,我们如何使用 foreach 获取哈希的键和值?
我们可以通过循环哈希来使用 foreach 访问其键和值。
my %hash=( 'Tom' => 23, 'Jerry' => 24, 'Mickey' => 25);
foreach my $key (keys %hash)
{
print "$key \n";
}
输出
米奇
汤姆
杰瑞
您可能想知道,为什么我们在 foreach() 中使用了 Keys。Keys 是 Perl 的一个内置函数,我们可以通过它快速访问哈希的键。那么值呢?我们可以使用 values 函数来访问哈希的值。
my %hash=( 'Tom' => 23, 'Jerry' => 24, 'Mickey' => 25);
foreach my $value(values %hash) # This will push each value of the key to $value
{
print " the value is $value \n";
}
输出
值为 24
值为 23
值为 25
Perl While
Perl While 循环是一种控制结构,只要条件为真,代码块就会执行。
代码块只有在条件为假时才会退出。
让我们看一个 Perl While 循环的例子。
这里有一个问题,它需要用户的输入,并且只有当输入的数字不是“7”时才会退出。
#!/usr/bin/perl
$guru99 = 0;
$luckynum = 7;
print "Guess a Number Between 1 and 10\n";
$guru99 = <STDIN>;
while ($guru99 != $luckynum)
{
print "Guess a Number Between 1 and 10 \n ";
$guru99 = <STDIN>;
}
print "You guessed the lucky number 7"
输出
猜一个 1 到 10 之间的数字
9
猜一个 1 到 10 之间的数字
5
猜一个 1 到 10 之间的数字
7
你猜中了幸运数字 7
在上面的例子中,如果我们输入除“7”之外的任何输入,while 条件将不会为真。
如果你看 while 是如何工作的,代码块只有在 while 中的条件为真时才会执行。
Perl do-while
do while 循环至少会执行一次,即使 while 部分的条件为假。
让我们用 do while 来看同样的例子。
$guru99 = 10;
do {
print "$guru99 \n";
$guru99--;
}
while ($guru99 >= 1);
print "Now value is less than 1";
输出
10
9
8
7
6
5
4
3
2
1
现在值小于1
Perl until
Until 代码块类似于条件语句中的 unless。在这里,代码块只有在 until 块中的条件为假时才会执行。
让我们以 while 的情况为例。
这里有一个问题,它需要用户的输入,并且只有当提供的姓名不是“sai”时才会退出。
print "Enter any name \n";
my $name=<STDIN>;
chomp($name);
until($name ne 'sai')
{
print "Enter any name \n";
$name=<STDIN>;
chomp($name);
}
输出
输入任意姓名 sai
Perl do-until
Do until 只能在我们只需要条件为假并且它应该至少执行一次时使用。
print "Enter any name \n";
my $name=<STDIN>;
chomp($name);
do
{
print "Enter any name \n";
$name=<STDIN>;
chomp($name);
}until($name ne 'sai');
输出
输入任意名称 Howard
输入任意姓名 Sheldon
输入任意姓名 sai
执行 while、do-while、until 和 do-until 示例代码以查看差异。
Perl 运算符
什么是运算符?
计算机语言中的运算符表示可以在计算机可以理解的某些变量或值集上执行的操作。Perl 结合了 C 语言中的大部分运算符。与其他编程语言相比,Perl 拥有更多的运算符。运算符分为算术、逻辑、关系和赋值运算符。
算术运算符
算术运算符是可用于执行一些基本数学运算的运算符。这些算术运算符是二元运算符,我们需要两个参数来执行基本运算。我们也可以使用一元运算符进行其他基本运算;您可以在下面的示例中看到差异。
| 运算符 | 描述 | 示例 |
|---|---|---|
|
+ |
加法运算用于加两个值或持有值的变量 持有的值 |
$x=5+6; # 或 $y=6; $z=$x+$y; |
|
– |
减法运算符用于减去两个值或持有值的变量 |
$x=6-5; # 或 $y=6; $z=$x-$y; |
|
* |
乘法运算符用于乘两个值或持有值的变量 |
$x=6*5; # 或 $y=6; $z=$x*$y; |
|
/ |
除法运算符用于除两个值或持有值的变量 |
$x=36/6; # 或 $y=6; $z=$x/$y; |
|
** |
指数运算符用于提供指数并获取值。 例如:22 = 4,33 = 27 |
$x=5**5; # 或 $x=4; $y=2; $z=$x**$y; |
|
% |
取模运算符用于在两个值或持有值的变量相除时获取余数 |
$x=5%2; # 或 $x=10; $y=2; $z=$x % $y; |
|
++ |
一元加法运算符将变量的值递增 1 |
$x=5; $x++; 或者 ++$x; |
|
— |
一元减法运算符用于将变量的值减 1 |
$x=5; $x--; # 后减 或者 --$x;# 前减 |
完成上述所有操作的示例。
my $x=10;
my $y=2;
my $z;
$z=$x+$y;
print ("Add of $x and $y is $z \n");
$z=$x-$y;
print ("Sub of $x and $y is $z \n");
$z=$x*$y;
print ("Mul of $x and $y is $z \n");
$z=$x/$y;
print ("Div of $x and $y is $z \n");
$z=$x**$y;
print ("Exp of $x and $y is $z \n");
$z=$x%$y;
print ("Mod of $x and $y is $z \n");
输出
10 和 2 的和是 12
10 减 2 是 8
10 乘 2 是 20
10 除以 2 是 5
10 的 2 次方是 100
10 除以 2 的余数是 0
赋值运算符
赋值运算符只是将值赋给变量,但这里我们还需要记住一件事,赋值运算符还会执行算术运算并将新值赋给执行运算的同一变量。
| 运算符 | 描述 | 示例 |
|---|---|---|
|
+= |
加法运算符用于将值添加到同一变量并赋值 |
$x=4; $x+=10; |
|
-= |
减法运算符用于从同一变量中减去值并赋值 |
$x=4; $x-=10; |
|
*= |
乘法运算符用于将值添加到同一变量并赋值 |
$x=4; $x*=10; |
|
/= |
除法运算符用于将值除以同一变量并赋值 |
$x=4; $x/=10; |
|
**= |
指数运算符用于获取指数并将其值赋给同一变量 |
$x=4; $x**=10; |
|
%= |
取模运算符用于在除法过程中获取余数并将其值赋给同一变量 |
$x=10; $x%=4; |
完成上述所有操作的示例。
my $x=10;
$x+=5;
print("Add = $x\n");
$x-=5;
print("Sub= $x\n");
$x*=5;
print("Mul = $x\n");
$x/=5;
print("Div = $x\n");
输出
加 = 15
减 = 10
乘 = 50
除 = 10
逻辑运算符和关系运算符
Perl 使用逻辑运算符来比较数字和字符串。大多数时候,逻辑运算符用于条件语句。
Perl 中的逻辑运算符和关系运算符
| 运算符 | 描述 |
|---|---|
|
==或eq |
用于检查两个变量是否相等的运算符 |
|
!=或ne |
用于检查两个变量是否不相等的运算符 |
|
> 或 gt |
用于检查以下内容的运算符 A 大于 B |
|
< 或 lt |
用于检查以下内容的运算符 A 小于 B |
|
>= 或 ge |
用于检查以下内容的运算符 A 大于或等于 B |
|
<= 或 le |
用于检查以下内容的运算符 A 小于或等于 B |
|
|| 或 或 |
用于检查 A 或 B 是否持有值的运算符 |
|
&&或 and |
用于检查 A 和 B 都持有值的运算符 |
让我们举一个例子,我们可以解释所有场景。
my $x=5;
my $y=5;
if($x == $y){
print ("True -- equal $x and $y \n");
}
else{
print ("False -- not equal $x and $y\n");
}
$x=6;
$y=7;
if($x != $y){
print ("True -- not equal $x and $y\n");
}
else{
print ("False -- equal $x and $y\n");
}
if($y > $x){
print ("True -- $y greater than $x\n");
}
else{
print ("False -- $y greater than $x\n");
}
if($x < $y){
print ("True -- $x less than $y\n");
}
else{
print ("False -- $x less than $y\n");
}
if($x <= $y){
print ("True -- $x less than $y\n");
}
else{
print ("False -- $x less than $y\n");
}
if($y >= $x){
print ("True -- $y greater than $x\n");
}
else{
print ("False -- $y greater than $x\n");
}
输出
真 — 等于 5 和 5
真 — 不等于 6 和 7
真 — 7 大于 6
真 — 6 小于 7
真 — 6 小于 7
真 — 7 大于 6
您可以在后面的章节中看到逻辑运算符的示例。
Perl 特殊变量
什么是 Perl 特殊变量?
Perl 中的特殊变量是指具有预定义含义的变量。这些变量以实名或标点符号表示。我们为所有 Perl 支持的变量(如标量特殊变量、数组特殊变量、哈希特殊变量)都有特殊变量。我们使用的大多数特殊变量都是标量。
当我们想用其名称使用特殊变量时,我们必须加载 Perl 模块“use English”,以明确告诉 Perl 解释器我们将使用其名称来使用特殊变量。
标量特殊变量
| 变量 | 描述 |
|---|---|
|
$_$ARG |
这是存储当前值的默认变量。 |
|
$0 或 $PROGRAM_NAME |
存储 Perl 脚本的文件名。 |
|
$/ |
输入记录分隔符,其默认值为 '\n',即换行符 |
|
$. |
保存正在读取的文件的当前行号 |
|
$, |
输出字段分隔符,主要由 print() 语句使用。默认值为 0,我们可以更改此变量的值。 |
|
$\ |
输出记录分隔符,此变量的值为空;我们可以为其分配任何值,print() 语句在打印输出时将使用此值。 |
|
$# |
此变量用于打印数字时的输出格式。 |
|
$%$FORMAT_PAGE_NUMBER |
将保存已读取文件的当前页码。 |
|
$=$FORMAT_LINES_PER_PAGE |
将保存已读取文件的当前页长。 |
|
$-$FORMAT_LINES_LEFT |
保存页面中剩余打印行数的数值。 |
|
$~$FORMAT_NAME |
格式名称:保存当前选定输出的格式,默认为文件句柄名称。 |
|
$^$FORMAT_TOP_NAME |
保存文件处理程序的标题格式值,默认值为 _TOP 后跟文件处理程序名称。 |
|
$|$OUTPUT_AUTOFLUSH |
默认值为零;用于在每次 write() 或 print() 后刷新输出缓冲区。 |
|
$$ |
将保存 Perl 解释器的运行进程号。 |
|
$? |
状态码:管道和系统调用。执行命令的返回状态。 |
|
$&$MATCH |
用于正则表达式,它将保存最后一次成功模式匹配的字符串。 |
|
$`$PREMATCH |
用于正则表达式,这将保存上次成功模式匹配之前的字符串。 |
|
$’$POSTMATCH |
用于正则表达式,这将保存最后一次成功模式匹配之后的字符串。 |
|
$+$LAST_PAREN_MATCH |
保存最后一次模式搜索匹配的最后一个括号的字符串。 |
|
$ |
$1, $2, $3 .... 按顺序保存模式匹配的值。 |
|
$[ |
第一个索引:数组,子字符串。 |
|
$] |
Perl 的一个版本。 |
|
$” |
用于列表元素的分隔符,默认值为空格。 |
|
$; |
多维数组中使用的下标分隔符 |
|
$! |
在数字上下文,打印错误号。在字符串上下文,打印错误。 |
|
$@ |
将保存语法错误信息,在 eval() 使用时使用。 |
|
$< |
保存运行脚本进程的真实 UID(用户 ID)。 |
|
$> |
保存运行脚本进程的有效 UID。 |
|
$( |
保存运行脚本进程的真实 GID(组 ID)。 |
|
$) |
保存运行脚本进程的有效 GID。 |
|
$^D$DEBUGGING |
保存调试标志的当前值。 |
|
$^C |
当使用 –c 命令行开关时,保存标志的当前值。 |
|
$^F |
最大系统文件描述符,默认值为 2 |
|
$^I$INPLACE_EDIT |
保存 –i 命令行开关的值。 |
|
$^M |
当 Perl 脚本因内存不足错误而崩溃时,可以使用特殊的内存池。 |
|
$^O$OSNAME |
操作系统信息已存储。Linux 系统为“Linux”,Windows 系统为“mswin32”。 |
|
$^T$BASETIME |
脚本运行时的秒数。 |
|
$^W$WARNING |
–w 命令行开关的当前值。警告开关。 |
|
$ARGV |
当使用 <> 时,当前文件的名称。 |
数组特殊变量
| 变量 | 描述 |
|---|---|
|
@INC |
保存一个路径列表,Perl 库模块或脚本在执行当前脚本时可以在这些路径中查找。这个 @INC 被 use 和 require 语句用于查找这些路径中的库模块。 |
|
@ARGV |
存储传递的命令行参数。 |
|
@_ |
在子程序中用于向子程序传递参数。 |
|
@F |
这是当使用 auto split –a(命令行开关)时,输入行存储的数组。 |
哈希特殊变量
| 变量 | 描述 |
|---|---|
|
%INC |
文件名将是键;值将是这些文件的路径。由 do、use 和 require 使用。 |
|
%ENV |
系统环境变量。 |
|
%SIG |
信号处理程序。 |
Perl 正则表达式
什么是正则表达式?
Perl 正则表达式在匹配语句或语句组中的字符串模式方面足够强大。正则表达式主要用于文本解析、模式匹配以及根据需求进行的更多操作。我们有一些运算符,它们专门用于正则表达式模式绑定 =~ 和 !~,这些是测试和赋值运算符。
正则表达式运算符

Perl 中的正则表达式运算符
- Perl 匹配 — m//
- Perl 替换 – s///
- Perl 音译 – tr///
在深入之前,我们需要了解一些关于正则表达式的知识;Perl 正则表达式语法中存在一些元字符、通配符等。
| 字符 | 含义 |
|---|---|
|
\ |
特殊或引用 |
|
* |
匹配 0 个或更多字符 |
|
+ |
匹配 1 个或更多字符 |
|
? |
匹配 0 个或 1 个字符 |
|
| |
可用于匹配替代模式 |
|
() |
用于存储匹配的模式 |
|
[] |
可以传递一组字符。专门用于数字和字母。 |
|
{} |
用于指定匹配可以执行的次数。 |
|
^ |
字符串开头 |
|
$ |
字符串结尾 |
|
\w |
用于匹配单个字符或单词,可以是字母数字,包括“_” |
|
\W |
匹配字母数字以外的任何内容 |
|
\s |
用于匹配空格 |
|
\S |
匹配除空格以外的任何内容 |
|
\d |
匹配数字。不包括小数和负数。 |
|
\D |
匹配数字以外的任何内容。 |
|
\t |
匹配制表符 |
|
\n |
匹配换行符 |
以上是模式匹配过程中可以使用的一组字符。
让我们看几个例子。
考虑一种情况,用户在脚本执行期间提供一些输入,我们想检查用户是否输入了某个名称作为输入。我们必须编写正则表达式语法来提取您的姓名并打印它。
my $userinput="Guru99 Rocks";
if($userinput=~m/.*(Guru99).*/)
{
print "Found Pattern";
}
else
{
print "unable to find the pattern";
}
输出
发现模式
在这里,我们将正则表达式写为 /.*(Guru99).*/。.* 匹配字符串中的所有字符。Perl 正则表达式中的“.”匹配任何字符,包括空格。
让我们看看如何精确地构建一个正则表达式。
考虑一个包含多个单词、数字和特殊符号的字符串示例:“Hello everyone this is my number: +91-99298373639”;
正则表达式:/^\w+\s\w+\s\w+\s\w+\s\w+\s\w+\:\+\d+\-\d+/i
单词空格单词空格单词空格单词空格单词空格单词空格特殊字符 : 空格特殊字符+数字特殊字符 –数字。
Perl 匹配运算符
匹配运算符用于匹配某个语句或变量中的字符串。
my $var="Hello this is perl";
if($var=~m/perl/)
{
print "true";
}
else
{
print "False";
}
输出
真
这段小代码将打印“true”,因为 Perl 模式匹配在变量中识别字符串。基本上,Perl 会在整个字符串中搜索 // 中提供的文本,即使只在一个地方找到,它也会返回“true”。模式可以存在于变量的任何位置。我们可以尝试用 !~ 替换 =~ 来查看这两个运算符之间的区别。
Perl 替换运算符
此运算符可用于搜索并将任何字符替换为 null 或其他字符。
my $a="Hello how are you"; $a=~s/hello/cello/gi; print $a;
输出
大提琴你好吗
注意:我们实际上可以在这个替换运算符中也使用任何模式匹配字符串,就像我们之前做的那样。这里我们使用了 'gi',g-全局,i-忽略大小写。
Perl 翻译运算符
这与替换类似,但它不使用任何 perl 正则表达式,而是我们可以直接传递我们想要替换的值或单词。
my $a="Hello how are you"; $a=~tr/hello/cello/; print $a;
输出
你好牛你还好吗
Perl 文件 I/O
Perl 被设计用于有效操作文件和 I/O 操作。Perl 的主要优势在于文件解析和文件处理。在 Perl 中进行文件处理时,会使用许多内置函数和运算符。
基本上,Perl 执行的文件操作是通过 FILEHANDLE 完成的。在打开文件进行读取或写入时,我们必须定义此 FILEHANDLE。
在本 Perl 脚本教程中,您将学习-
Perl 打开文件
我们可以使用 Perl 中可用的 open() 函数打开文件。
open(FILEHANDLE, "filename or complete path of the file");
现在我们已经打开了一个文件,现在出现了一个问题。它是用于读取还是写入?
Perl 读取文件和 Perl 写入文件
Perl 有特定的模式,需要使用它们来读取、写入或追加文件。
Read – open(my $fh,"<filename or complete path of the file"); Write – open(my $fh,">filename or complete path of the file"); Append – open(my $fh,">>filename or complete path of the file");
几个读取文件的例子
假设我们有一个名为 file.txt 的 perl 文件,其中包含几行文本。我们需要打开此文件并打印相同的内容。
open(FH,"<file.txt");
while(<FH>) # Looping the file contents using the FH as a filehandle.
{
print "$_";
}
close FH;
或
open(FH,"<file.txt");
my @content=<FH>; # specifying the input of the array is FH.
foreach(@content)
{
print "$_";
}
close FH;
这将在输出屏幕上打印文件内容。
现在,我们将编写一个程序来创建文件并向其中写入数据。
open(FH,">test.txt"); my $var=<>; print FH $var; close FH;
这将在运行时写入提供的输入,并创建一个名为 test.txt 的文件,该文件将包含输入。
上述方法总是会尝试创建一个名为 test.txt 的文件并将输入写入该文件;我们将以同样的方式追加文件。
open(FH,">>test.txt"); my $var=<>; print FH $var; close FH;
| 模式 | 描述 |
|---|---|
|
< |
读取 |
|
+< |
读写 |
|
> |
创建、写入和截断 |
|
+> |
读、写、创建和截断 |
|
>> |
写入、追加和创建 |
|
+>> |
读、写、追加和创建 |
现在我们必须看看如何使用基本示例来读取、写入和追加文件。
我们将看到更多的例子和其他有助于深入了解文件的函数。
Perl Tell
此方法将返回 FILEHANDLER 的当前位置(以字节为单位),如果未指定,则将最后一行视为位置。
open(FH, "test.pl");
while(<FH>)
{
$a=tell FH;
print "$a";
}
Perl Seek
Seek 函数类似于 fseek 系统调用。此方法用于通过指定字节以及文件指针的开头或结尾来将文件指针定位到特定位置。
seek FH, bytes, WHENCE;
WHENCE 是文件指针开始的位置。零将从文件开头设置。
示例:假设 input.txt 包含一些数据,如“Hello this is my world.”
open FH, '+<','input.txt'; seek FH, 5, 0; # This will start reading data after 5 bytes. $/ = undef; $out = <FH>; print $out; close FH;
输出
这是我的世界
Perl Unlink
Unlink 用于删除文件。
unlink("filename or complete file path");
处理目录
我们还可以通过处理目录来处理多个文件。
让我们看看如何打开一个目录。我们可以使用 opendir 和 readdir 方法。
opendir(DIR,"C:\\Program Files\\"); #DIR is the directory handler.
while(readdir(DIR)) # loop through the output of readdir to print the directory contents.
{
print "$_\n";
}
closedir(DIR); #used to close the directory handler.
或
opendir(DIR,"C:\\Program Files\\");
@content=readdir(DIR);
foreach(@content)
{
print "$_\n";
}
closedir(DIR);
这将打印该目录中所有可用的文件。
Perl 文件测试及其含义
|
-r |
检查当前用户/组是否可读文件/目录 |
|
-w |
检查当前用户/组是否可写文件/目录 |
|
-x |
检查当前用户/组是否可执行文件/目录 |
|
-o |
检查文件/目录是否属于当前用户 |
|
-R |
检查文件/目录是否可被真实用户/组读取 |
|
-W |
检查文件/目录是否可被真实用户/组写入 |
|
-X |
检查文件/目录是否可被真实用户/组执行 |
|
-O |
检查文件/目录是否属于真实用户 |
|
-e |
检查文件/目录名称是否存在 |
|
-z |
检查文件是否存在且大小为零(目录始终为假) |
|
-f |
检查条目是否是普通文件 |
|
-d |
检查条目是否是目录 |
|
-l |
检查条目是否是符号链接 |
|
-S |
检查条目是否是套接字 |
|
-p |
检查条目是否是命名管道(“FIFO”) |
|
-b |
检查条目是否是块特殊文件(如可挂载磁盘) |
|
-c |
检查条目是否是字符特殊文件(如I/O设备) |
|
-u |
检查文件或目录是否设置了setuid |
|
-g |
检查文件或目录是否设置了setgid |
|
-k |
检查文件或目录是否设置了粘滞位 |
|
-t |
给定文件句柄是否是TTY(通过isatty()系统函数,文件名无法通过此测试) |
|
-T |
检查文件是否看起来像“文本”文件 |
|
-B |
检查文件是否看起来像“二进制”文件 |
|
-M |
检查文件的修改时间(以天为单位) |
|
-A |
检查文件的访问时间(以天为单位) |
|
-C |
检查文件的Inode修改时间(以天为单位) |
Perl子程序
什么是子程序?
子程序类似于其他编程语言中的函数。我们已经使用了一些内置函数,如print、chomp、chop等。我们可以在Perl中编写自己的子程序。这些子程序可以写在程序的任何位置;最好将子程序放在代码的开头或结尾。

子程序示例
sub subroutine_name
{
Statements…; # this is how typical subroutines look like.
}
既然我们知道如何编写子程序,那么如何访问它呢?
我们需要使用子程序名称前缀加上“&”符号来访问或调用子程序。
sub display
{
print "this is a subroutine";
}
display(); # This is how we call a subroutine
传递Perl参数与Perl实参
编写子程序或Perl函数是为了将可重用代码放在其中。大多数可重用代码需要将参数传递给子程序。在这里,我们将学习如何将实参传递给子程序。
sub display
{
my $var=@_; # @_ is a special variable which stores the list of arguments passed.
print "$var is the value passed";
}
display(2,3,4); #this is how we need to pass the arguments.
输出
传递的值是3
@_ 是一个特殊的数组变量,用于存储传递给子程序的实参。
Perl Shift
我们还可以使用“shift”关键字,它一次将一个参数移到一个变量或$_[0]、$_[1]...,它们是@_数组的单个元素
sub display
{
my $var=shift;
print "$var is passed";
}
display("hello");
输出
“hello”被传递
子程序通常用于面向对象编程,以及需要放置更多可重用代码的地方。
子程序的主要功能是完成某些任务并返回可重用代码的结果。

我们可以使用return关键字从子程序返回值。
sub add
{
my $a=shift;
my $b=shift;
return($a+$b);
}
my $result=add(5,6);
print $result;
输出
11
$result将保存$a和$b相加的值。
我们还可以直接将哈希和数组传递给子程序。
sub hash
{
my %hash=@_;
print %hash;
}
%value= ( 1=>'a', 2=>'b');
&hash(%value);
输出
1a2b
我们还可以返回哈希或数组。
sub hashArray
{
my %hash=@_;
print "Inside Sub-routine";
print %hash;
return(%hash);
}
%hash=(1=>'a', 2=>'b');
my(@ret)=hashArray(%hash);
print "After Sub-routine call";
print @ret;
输出
子程序内部2b1a子程序调用后2b1a
Perl格式
Perl有一种机制,我们可以用它生成报告。使用此功能,我们可以在输出屏幕或文件中打印时,按照我们想要的方式精确地制作报告。可以使用Perl中提供的printf或sprintf函数编写简单的格式。
printf "%05d\n", 30;
这将包括在数字30前面添加前导零,使总数字计数达到5。同样的操作也可以用于sprintf。
sprintf "%05d\n", 30; # This will print the same as printf.
使用printf和sprintf,我们可以获得大多数Perl格式。在报告的情况下,这将难以实现。
===========================================================================
姓名 地址 年龄 电话
===========================================================================
Krishna Chennai 24 929309242
Shruthi Chennai 24 929309232
以上是我们需要在Perl中以相同方式打印的报告示例。这可以通过使用perl printf和perl sprintf来实现。使用格式可以有效地实现它。
格式可以按以下方式声明。
format FORMATNAME=FORMATLIST.
在这里,我们将使用特定的write方法将数据打印到输出屏幕或文件中。
| 符号 | 描述 |
|---|---|
|
@ |
用于表示字段占位符的开始 |
|
> |
文本右对齐 |
|
< |
文本左对齐 |
|
| |
居中对齐 |
|
# |
如果提供了多个#,则表示数字。如果只提供一个#,则视为注释 |
|
. |
小数点 |
|
^ |
字段占位符的开始也可以用于多行和自动换行 |
|
~ |
如果变量为空,则该行应为空 |
|
@* |
多行。 |
($name,$addr,$age,$phone)=("krishna","chennai","24","929309242");
write;
($name,$addr,$age,$phone)=("shruthi","chennai","24","929309232");
write;
format STDOUT_TOP=
===============================================================
NAME ADDRESS AGE PHONE
===============================================================
.
format STDOUT=
@<<<<<<<<<<<<< @<<<<<<<<<<<<<<<<<<<<< @<<< @<<<<<<<<<<
$name, $addr, $age, $phone
.
执行代码以查看输出。
我们使用@符号来指定字段占位符或字符串的开始,’<’表示每个字符。
我们使用STDOUT打印到标准输出。我们可以将其更改为用于将数据写入文件的文件句柄。
open(REPORT,">test.txt");
($name,$addr,$age,$phone)=("krishna","chennai","24","929309232");
write REPORT;
($name,$addr,$age,$phone)=("shruthi","chennai","24","929309232");
write REPORT;
format REPORT_TOP=
===============================================================
NAME ADDRESS AGE PHONE
===============================================================
.
format REPORT=
@<<<<<<<<<<<<< @<<<<<<<<<<<<<<<<<<<<< @<<< @<<<<<<<<<<
$name, $addr, $age, $phone
我们可以将“<”替换为“>”或“|”来更改文本的对齐方式。STDOUT_TOP用于设计格式的标题。我们也可以将它与文件句柄FH_TOP(FH是文件句柄)一起使用。这将把格式输出到我们正在处理的文件中。
Perl编码标准
每个程序员都有自己编写代码的习惯,这些标准应该足够熟悉,以便其他程序员能够正确理解和支持代码。

Perl中的编码标准
编写代码简单易行。问题出现在后续阶段需要维护时。在编写代码时,需要遵循适当的指南和编码标准。Perl也定义了一些对程序员编写代码有用的标准。建议在编写代码时加载“strict”和“warnings module”。这些模块都有其自身的重要性。Strict将强制我们在使用变量之前声明变量,并且还会告知代码中是否存在任何裸词。Warnings module可以通过在shebang中向Perl解释器传递“-w”选项来替代使用。Warnings将在输出屏幕上打印。
#!/usr/bin/perl –w
以下是一些标准列表。
- 使用“strict”和“warnings”模块。
- 删除未使用的变量。
- 变量名应该对其他用户来说是可理解的。例如:$name, @fileData等。
- 编写脚本时需要文档。
- 不要硬编码任何值,而是尝试动态获取这些值或在运行时要求用户输入(文件路径、文件名)。
- 最大化代码重用。尝试将可重用代码放在子程序中。
- 子程序应该有有意义的名称。
- 子程序需要编写适当的注释和文档。
- 始终初始化变量。
- 始终检查系统调用的返回码。打开文件可能会成功也可能失败,这里有一个返回码将在文件不存在时显示错误状态。
例如:open(FH, "
- 子程序应该始终返回值。
- 大括号在同一行打开。
- 单行BLOCK可以与大括号放在同一行。
- 在循环中使用标签,在必要时很容易退出循环。
- 当长短语作为变量名或子程序编写时,使用下划线。
- 编码时尽量使用简单的正则表达式。
符合编码标准的完美示例
#######################################################################
Program to read the file content
# Date: 22-2-2013
# Author : Guru99
########################################################################
#!/usr/bin/perl
use strict;
use warnings;
my $line;
open FR, "file.txt" || die("Cannot open the file $!");
while ($line=<FR>)
{
print $line;
} # Looping file handler to print data
Perl错误处理
什么是异常?
异常是程序执行期间发生的事件,它将暂停或终止您的程序。
错误处理
错误处理是每个程序员在编程时都必须注意的问题。Perl也提供了错误处理技术,我们可以用它捕获错误并相应地处理它们。

Perl中的错误处理
有很多方法可以检查程序中的错误。我们需要检查我们正在使用的函数的返回代码。如果我们能够正确处理这些返回代码,那么大部分错误处理都可以实现。
系统调用会返回什么?
在系统调用中,返回状态将存储在两个特殊变量 $? 和 $! 中
$! – 这将捕获错误号或与错误消息关联的错误号。
$? – 这将保存 system() 函数的返回状态。
使用Perl运算符或逻辑
在使用系统调用时,我们可以使用逻辑或运算符进行错误处理。
例如
open(FH,"<test.txt");
如果文件存在,这将以读取模式打开文件。
如果文件丢失怎么办?
open(FH,"<test.txt") or die("File not exists $!"); # This will perl exit the program if the file not exists.
open(FH,"<test.txt") or warn ("File not exists $!"); # This will print a warning message on STDERR
Perl Eval
Eval函数可以处理致命错误、编译时错误、运行时错误以及在某个时间点终止代码的错误。
Perl Eval函数可以包含一个代码块或一个表达式。Eval将其中的所有内容都视为字符串。
考虑调用一个在脚本中未定义的子程序的情况。在这种情况下,脚本将终止并显示“未定义的子程序&XYZ”的错误,此错误可以在eval函数中处理。
evals块有很多用途;其中一个用途是,当我们想在运行时加载特定于操作系统的模块时。
例如:除以零会导致致命错误;为了处理这个问题,我们可以将代码放在evals块中。
$a=5;
$b=0;
eval
{
'$result=$a/$b';
}
if($@)
{
print "$@"; # All the error codes returned by evals will get stored in $@.
}
输出
C:\Users\XYZ\Text.pl 第8行语法错误,靠近“)”
“{”
由于编译错误,C:\Users\XYZ\Text.pl 的执行中止。
示例:使用perl die语句的eval。
sub test
{
die "Dieing in sub test \n";
}
eval
{
test();
};
print "Caught : $@\n";
输出
捕获:子测试中退出
使用Perl Try
Perl 不像其他编程语言那样支持 try、catch 和 finally 代码块。我们仍然可以通过加载外部 Perl 模块来使用它们。
使用 Try::Tiny;
使用此功能,我们可以将代码放在 try 块中,并在 warn 块中捕获错误。
在 eval 中使用的 $@,Try::Tiny 使用 $_。
# 使用 catch 处理器处理错误
try
{
die "Die now";
}
catch
{
warn "caught error: $_"; # not $@
};
使用 finally。
my $y;
try
{
die 'foo'
}
finally
{
$y = 'bar'
};
try
{
die 'Die now'
}
catch
{
warn "Returned from die: $_"
}
finally
{
$y = 'gone'
};
输出
C:\Users\XYZ\Text.pl 第4行 foo。
我们可以这样使用try、catch和finally。
try { # 语句 }
catch { # 语句 }
finally { # 语句 };
或者
try
{
# statement
}
finally
{
# statement
};
输出
或者
try
{
# statement
}
finally
{
# statement
}
catch
{
# statement
};
输出
Perl套接字编程
什么是套接字?

套接字是一种介质,通过它两台计算机可以使用网络地址和端口在网络上进行交互。
假设A(服务器)和B(客户端)是两个系统,它们必须使用套接字相互交互以运行某些程序。
要实现这一点,我们需要在A(服务器)和B(客户端)中都创建套接字,A将处于接收状态,B将处于发送状态。
A(服务器)
在这里,服务器希望从B(客户端)接收连接并执行一些任务,然后将结果发送回B(客户端)。当我们执行代码时,A中的操作系统尝试创建一个套接字并将一个端口绑定到该套接字。然后它将监听来自发送方B的连接。
B(客户端)。
在这里,客户端希望将其系统中的某些程序发送到A(服务器)进行一些处理。当我们执行代码时,B中的操作系统尝试创建一个套接字与A(服务器)通信,B必须指定A的IP地址和端口号,B希望连接到该端口号。
如果一切顺利,两个系统将通过一个端口交互以交换信息。Perl也支持套接字编程。
Perl有一个原生API,通过它可以实现套接字。为了方便起见,有许多CPAN模块可以使用它们编写套接字程序。
服务器操作
- 创建套接字
- 将套接字与地址和端口绑定
- 在该端口地址上监听套接字
- 接受尝试使用服务器的端口和IP连接的客户端连接
- 执行操作
客户端操作
- 创建套接字
- 使用其端口地址连接到服务器
- 执行操作

Socket.io
这是一个用于套接字编程的模块,它基于面向对象编程。该模块不支持网络中使用的INET网络类型。
IO::Socket::INET
此模块支持INET域,并基于IO::Sockets构建。IO::Sockets中所有可用的方法都继承在INET模块中。
使用TCP协议的客户端和服务器
TCP是一种面向连接的协议;我们将使用此协议进行套接字编程。
在进一步操作之前,让我们看看如何为IO::Socket::INET模块创建一个对象并创建一个套接字。
$socket = IO::Socket::INET->new(PeerPort => 45787, PeerAddr => inet_ntoa(INADDR_BROADCAST), Proto => udp,LocalAddr => 'localhost',Broadcast => 1 ) or die "Can't create socket and bind it : $@n";
IO::Socket::INET 模块中的 new 方法接受一个哈希作为子程序的输入参数。这个哈希是预定义的,我们只需要为我们想要使用的键提供值。这个哈希使用了一系列键。
|
PeerAddr |
远程主机地址 |
|
PeerHost |
PeerAddr 的同义词 |
|
PeerPort |
远程端口或服务 |
|
LocalAddr |
本地主机绑定地址 |
|
LocalHost |
LocalAddr 的同义词 |
|
LocalPort |
本地主机绑定端口 |
|
Proto |
协议名称(或编号) |
|
类型 |
套接字类型 |
|
监听 |
监听队列大小 |
|
ReuseAddr |
绑定前设置 SO_REUSEADDR |
|
重复使用 |
绑定前设置 SO_REUSEADDR |
|
ReusePort |
绑定前设置 SO_REUSEPORT |
|
广播 |
绑定前设置 SO_BROADCAST |
|
超时 |
各种操作的超时值 |
|
MultiHomed |
尝试多宿主主机的所有地址 |
|
阻塞 |
确定连接是否为阻塞模式 |
Server.pl
use IO::Socket;
use strict;
use warnings;
my $socket = new IO::Socket::INET (
LocalHost => 'localhost',
LocalPort => '45655',
Proto => 'tcp',
Listen => 1,
Reuse => 1,
);
die "Could not create socket: $!n" unless $socket;
print "Waiting for the client to send datan";
my $new_socket = $socket->accept();
while(<$new_socket>) {
print $_;
}
close($socket);
Client.pl
use strict; use warnings; use IO::Socket; my $socket = new IO::Socket::INET ( PeerAddr => 'localhost', PeerPort => '45655', Proto => 'tcp', ); die "Could not create socket: $!n" unless $socket; print $socket "Hello this is socket connection!n"; close($socket);
注意
在套接字编程中,如果我们正在本地主机上运行,则必须先执行 Server.pl,然后分别在不同的命令提示符下执行 client.pl。
Perl模块和包是什么
模块和包彼此密切相关且相互独立。包:Perl包也称为命名空间,其中包含所有独特的变量,如哈希、数组、标量和子程序。模块:模块是可重用代码的集合,我们在其中编写子程序。这些模块可以加载到Perl程序中,以使用这些模块中编写的子程序。
什么是Perl模块?
标准模块将在Perl安装在任何系统上时安装。CPAN:全面的Perl存档网络 – Perl模块的全球存储库。我们自己的自定义Perl模块可以由我们编写。基本上,当模块加载到任何脚本中时,它将导出其所有全局变量和子程序。这些子程序可以直接调用,就像它们在脚本本身中声明一样。Perl模块可以以.pm扩展名写入文件名,例如:Foo.pm。模块可以通过在程序开头使用“package Foo”来编写。
基本Perl模块
#!/usr/bin/perl
package Arithmetic;
sub add
{
my $a=$_[0];
my $b=$_[1];
return ($a+$b);
}
sub subtract
{
my $a=$_[0];
my $b=$_[1];
return ($a-$b);
}
1;
无输出
要使用此Perl模块,我们必须将其放置在当前工作目录中。
我们可以在代码的任何地方使用require或use加载Perl模块。require和use之间的主要区别是,require在运行时加载模块,而use在编译时加载模块。
#!/usr/bin/perl require Arithmetic; print Arithmetic::add(5,6); print Arithmetic:: subtract (5,6);
在上面的示例中,我们使用完全限定模块名称访问子程序。
我们也可以使用“use Arithmetic”访问包。
导出器
此模块具有导入方法的默认功能。
#!/usr/bin/perl
package Arithmetic;
require Exporter;
@ISA= qw(Exporter); # This is basically for implementing inheritance.
@EXPORT = qw(add);
@EXPORT_OK = qw(subtract);
sub add
{
my $a=$_[0];
my $b=$_[1];
return ($a+$b);
}
sub subtract
{
my $a=$_[0];
my $b=$_[1];
return ($a-$b);
}
1;
@EXPORT 数组可用于传递变量和子程序的列表,这些变量和子程序将默认导出到模块的调用者。
@EXPORT_OK 数组可用于传递变量和子程序的列表,这些变量和子程序将按需导出,用户在加载模块时必须指定。
#!/usr/bin/perl use Arithmetic qw(subtract); print add(5,6); print subtract (5,6);
默认情况下,add 子程序将被导出。如果未在加载模块时指定,则 subtract 方法不会被导出。
Perl中的面向对象编程
在本节中,我们将学习如何创建Perl面向对象模块。首先,让我们看看什么是对象?对象是一个实例,通过它我们可以访问、修改和定位任何Perl模块中的某些数据。这无非是将您现有的Perl包、变量和子程序在引用其他编程语言时像类、对象和方法一样运行。
创建类
我们已经从上一个主题中了解了如何创建模块。类的目的是存储方法和变量。Perl模块将包含作为方法的子程序。我们需要访问这些变量和子程序对象。
Perl构造函数
Perl 中的构造函数是一种方法,它将执行并返回一个带有模块名称标记的引用。这被称为祝福类。我们使用一个特定的变量来祝福 Perl 类,即 bless。
#!/usr/bin/perl
package Arithmetic;
sub new
{
my $class=shift;
my $self={};
bless $self, $class;
return $self;
}
sub add
{
my $self= shift;
my $a=$_[0];
my $b=$_[1];
return ($a+$b);
}
sub subtract
{
my $self= shift;
my $a=$_[0];
my $b=$_[1];
return ($a-$b);
}
1;
new方法用作类的构造函数,此构造函数将为我们创建一个对象并将其返回给调用此构造函数的脚本。
#!/usr/bin/perl use Arithmetic; my $obj= Arithmetic->new(); my $result= $obj->add(5,6); print "$result"; $result = $obj->subtract(6,5); print "$result";
这里,我们需要了解对象是如何创建的。每当我们尝试为类创建对象时,都需要使用类的完整名称。假设,如果perl类位于 lib\Math\Arithmetic.pm。并且,如果我们想从lib目录访问此perl类,那么在脚本中调用时必须提供类的完整路径。
使用 lib::Math::Arithmetic;
my $obj = lib::Math::Arithmetic->new();
Perl中对象的创建就是这样发生的。
@INC
Perl脚本如何知道库模块存在于何处?Perl只知道脚本的当前目录和Perl内置库路径。每当我们使用不在当前目录或Perl库路径中的Perl模块时,脚本总是会失败。关于@INC,这是一个数组,它保存了所有需要查找Perl模块的目录路径。尝试执行此命令并查看输出将是什么。
perl –e "print @INC"
这将给出一些输出,那就是lib模块可用的路径。每当我们使用任何新的库模块时,我们都需要告诉Perl解释器查看Perl模块可用的特定位置。
push(@INC, "PATH TO YOUR MODULE");
将此作为代码的第一行。这将告诉您的解释器查看该路径。或 use
lib Arithmetic; # List here is your Perl Module location
Perl析构函数
对象的析构函数在脚本退出之前默认在结束时调用。它用于从内存中销毁您的对象。
Perl 与 Shell 脚本

- Perl编程不会导致可移植性问题,这在shell脚本中使用不同的shell时很常见。
- Perl中的错误处理非常容易
- 由于其广阔性,您可以轻松地在Perl上编写长而复杂的程序。这与Shell形成对比,Shell不支持命名空间、模块、对象、继承等。
- Shell可用的可重用库较少。与Perl的CPAN无法相比
- Shell安全性较低。它调用外部函数(mv、cp等命令依赖于所使用的shell)。相反,Perl在使用内部函数时做了有用的工作。
PERL在自动化测试中的应用
Perl广泛应用于自动化领域。它可能不是世界上最好的编程语言,但它最适合某些类型的任务。让我们讨论一下Perl在自动化测试中的应用场景和原因。
存储测试

什么是存储?数据存储在文件中。
假设我们有一个存储相关的测试用例,我们需要将数据写入一个分区,然后读取并验证数据是否正确写入。
这可以手动完成,但一个手动测试人员能重复10000次吗?那将是一场噩梦!我们需要自动化。
自动化任何与存储相关的东西的最佳工具是Perl,因为它拥有文件处理技术、正则表达式和强大的文件解析能力,与其他编程语言相比,它消耗的执行时间最少。
为什么我们需要测试存储?想象一下大型数据中心,数据将以每秒存储数千条记录的速度不断地从一个系统流向另一个系统。测试这种存储机制的健壮性至关重要。
许多公司,如惠普、戴尔、IBM以及许多服务器制造商,都使用Perl作为接口来测试存储和网络领域的功能。NetApp就是这样一家完全专注于存储的公司,并使用Perl作为编程语言来自动化测试用例。
如果您对Perl自动化感兴趣,那么建议您学习存储和网络概念。
服务器和网络测试

使用Perl进行服务器和网络测试
PERL广泛用于服务器正常运行时间和性能监控。
考虑一个拥有100个主机(服务器)的数据中心。您需要连接到每个主机,远程执行一些命令。您还想重新启动系统并检查它何时重新上线。
手动为所有100个主机执行此任务将是一场噩梦。但是我们可以使用PERL轻松自动化此任务。
使用PERL实现上述自动化的设计步骤
- 从文件中获取主机信息,例如(IP、用户名和密码)。
- 使用Net::SSH2连接到每个系统并建立通道以执行命令。
- 执行所需的一组命令,例如:ls、dir、ifconfig、ps等。
- 重新启动系统。
- 等待10分钟,直到系统启动。
- 使用Net::Ping模块ping系统并打印状态。
我们将编写上述场景的代码。
我们假设有一个名为Input.txt的文件,它将存储我们需要连接并执行命令的所有主机的完整信息。
Input.txt
192.168.1.2 root password
192.168.1.3 root password
192.168.1.4 root root123
HostCheck.pl
use Net::SSH2;
use Net::Ping;
use strict;
use warnings;
my $ping = Net::Ping->new(); # Creating object for Net::Ping
my $SSHObj = Net::SSH2->new(); #Creating object for Net::SSH2
open( FH, "Input.txt" ); # Opening file and placing content to FH
my @hosts = <FH>;
my $ip;
my @ips;
foreach (@hosts)
{
if ( $_ =~ /(.*)\s+(\w+)\s+(.*)/ ) #Regex to get each info from file
{
$ip = $1;
my $user = $2;
my $password = $3;
$SSHObj->connect($ip);
print "Connecting to host -- $ip --Uname:$user --Password:$password\n";
my $status = $SSHObj->auth_password( $user, $password );
print "$status\n";
die("unable to establish connection to -- $ip") unless ($status);
my $shell = $SSHObj->channel();
print "$_\n" while <$shell>;
$shell->blocking(1);
$shell->pty('tty');
$shell->shell();
sleep(5);
#Executing the list of command on particular host. Can be any command
print $shell "ls \n";
print "$_\n" while <$shell>;
print $shell "ps \n";
print "$_\n" while <$shell>;
print $shell "dir \n";
print "$_\n" while <$shell>;
print $shell "init 6\n"; #rebooting the system
push( @ips, $ip );
}
}
sleep 600;
foreach (@ips)
{
if ( $ping->ping($_) )
{
print "$_ is alive.\n" if $ping->ping($_);
}
else
{
print "$_ is not still up --waiting for it to come up\n";
}
}
网页测试
Perl不仅限于存储和网络测试。我们还可以使用PERL执行基于Web的测试。WWW-Mechanize是用于Web测试的一个模块。基本上,它不会启动任何浏览器来测试Web应用程序的功能,而是使用HTML页面的源代码。
我们还可以使用Selenium IDE、RC、Web driver进行基于浏览器的测试。Perl支持Selenium。
\n”; # 这将保留模式匹配后的剩余字符串。
打印“