Keras 教程
什么是 Keras?
Keras 是一个用 Python 编写的开源神经网络库,它运行在 Theano 或 Tensorflow 之上。它被设计为模块化、快速且易于使用。它由谷歌工程师 François Chollet 开发。Keras 不处理底层计算,而是使用另一个库来完成,这个库被称为“后端”。
Keras 是底层 API 的高级 API 包装器,能够运行在 TensorFlow、CNTK 或 Theano 之上。Keras 高级 API 处理我们构建模型、定义层或设置多输入输出模型的方式。在这个层面上,Keras 还使用损失函数和优化器函数来编译我们的模型,并使用 fit 函数进行训练。Python 中的 Keras 不处理底层 API,例如创建计算图、张量或其他变量,因为这些已经由“后端”引擎处理了。
什么是后端?
后端是 Keras 中的一个术语,它借助 Tensorflow 或 Theano 等其他库执行所有底层计算,如张量积、卷积和许多其他操作。因此,“后端引擎”将执行模型的计算和开发。Tensorflow 是默认的“后端引擎”,但我们可以在配置中更改它。
Theano、Tensorflow 和 CNTK 后端

Theano 是一个由加拿大魁北克省蒙特利尔大学的 MILA 小组开发的开源项目。它是第一个被广泛使用的框架。它是一个 Python 库,有助于使用 Numpy 或 Scipy 对多维数组进行数学运算。Theano 可以使用 GPU 加速计算,它还可以自动构建符号图来计算梯度。在其网站上,Theano 声称它可以识别数值不稳定的表达式,并用更稳定的算法来计算它们,这对我们的不稳定表达式非常有用。

另一方面,Tensorflow 是深度学习框架中的后起之秀。它由谷歌大脑团队开发,是最受欢迎的深度学习工具。它拥有众多功能,并且有研究人员为其开发做出贡献,以用于深度学习目的。

Keras 的另一个后端引擎是微软认知工具包(Microsoft Cognitive Toolkit),即 CNTK。它是由微软团队开发的开源深度学习框架。它可以在多个 GPU 或多台机器上运行,以大规模训练深度学习模型。在某些情况下,据报道 CNTK 比 Tensorflow 或 Theano 等其他框架更快。接下来,在本 Keras CNN 教程中,我们将比较 Theano、TensorFlow 和 CNTK 的后端。
比较后端
为了了解这两个后端之间的比较,我们需要进行基准测试。正如您在 Jeong-Yoon Lee 的基准测试中所看到的,比较了3个不同后端在不同硬件上的性能。结果是 Theano 比其他后端慢,据报道慢了50倍,但准确率彼此接近。
Jasmeet Bhatia 进行了另一项基准测试。他报告说,在某些测试中 Theano 比 Tensorflow 慢。但对于所测试的每个网络,总体准确率几乎相同。
因此,在 Theano、Tensorflow 和 CNTK 之间,显然 TensorFlow 比 Theano 更好。使用 TensorFlow,计算时间大大缩短,并且 CNN 优于其他两者。
接下来,在这个 Keras Python 教程中,我们将了解 Keras 和 TensorFlow 之间的区别(Keras vs Tensorflow)。
Keras 与 Tensorflow
| 参数 | Keras | Tensorflow |
|---|---|---|
| 类型 | 高级 API 包装器 | 底层 API |
| 复杂性 | 如果您懂 Python 语言,则易于使用 | 您需要学习使用某些 Tensorflow 函数的语法 |
| 目的 | 用于快速部署具有标准层的模型 | 允许您创建任意计算图或模型层 |
| 工具 | 使用其他 API 调试工具,如 TFDBG | 您可以使用 Tensorboard 可视化工具 |
| 社区 | 庞大而活跃的社区 | 庞大而活跃的社区和广泛共享的资源 |
Keras 的优势
快速部署且易于理解
Keras 可以非常快速地构建网络模型。如果您想用几行代码构建一个简单的网络模型,Python Keras 可以帮助您。请看下面的 Keras 示例。
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(64, activation='relu', input_dim=50)) #input shape of 50 model.add(Dense(28, activation='relu')) #input shape of 50 model.add(Dense(10, activation='softmax'))
由于 API 友好,我们可以轻松理解整个过程。用简单的函数编写代码,无需设置多个参数。
庞大的社区支持
有许多 AI 社区使用 Keras 作为其深度学习框架。他们中的许多人向公众发布了他们的代码和教程。
拥有多个后端
您可以选择 Tensorflow、CNTK 和 Theano 作为 Keras 的后端。您可以根据需要为不同的项目选择不同的后端。每个后端都有其独特的优势。
跨平台且易于模型部署
凭借支持的各种设备和平台,您可以在任何设备上部署 Keras,例如
- 使用 CoreML 的 iOS
- 使用 Tensorflow Android 的 Android
- 支持 .js 的 Web 浏览器
- 云引擎
- 树莓派 (Raspberry Pi)
多 GPU 支持
您可以在单个 GPU 上训练 Keras,也可以同时使用多个 GPU。因为 Keras 内置了对数据并行的支持,所以它可以处理大量数据并加快训练所需的时间。
Keras 的缺点
无法处理底层 API
Keras 只处理在其他框架或后端引擎(如 Tensorflow、Theano 或 CNTK)之上运行的高级 API。因此,如果您想为研究目的创建自己的抽象层,它就不是很有用,因为 Keras 已经有预先配置好的层了。
安装 Keras
在本节中,我们将探讨安装 Keras 的各种方法。
直接安装或虚拟环境
哪个更好?直接安装到当前的 Python 环境还是使用虚拟环境?如果您有多个项目,我建议使用虚拟环境。想知道为什么吗?这是因为不同的项目可能会使用不同版本的 Keras 库。
例如,我有一个项目需要使用 Python 3.5 和 OpenCV 3.3,以及旧版的 Keras-Theano 后端,但在另一个项目中,我必须使用最新版本的 Keras 和 Tensorflow 作为后端,并支持 Python 3.6.6。
我们不希望 Keras 库之间相互冲突,对吧?所以我们使用虚拟环境来将项目与特定类型的库隔离,或者我们可以使用像亚马逊网络服务(AWS)这样的云服务平台来为我们进行计算。
在亚马逊网络服务 (AWS) 上安装 Keras
亚马逊网络服务是一个为研究人员或任何其他目的提供云计算服务和产品的平台。AWS 出租其硬件、网络、数据库等,以便我们可以直接从互联网上使用它们。深度学习领域一个流行的 AWS 服务是亚马逊机器学习镜像深度学习服务(DL AMI)。
有关如何使用 AWS 的详细说明,请参考本教程
关于 AMI 的说明:您将有以下 AMI 可用
AWS 深度学习 AMI 是 AWS EC2 服务中的一个虚拟环境,可以帮助研究人员或从业者进行深度学习工作。DLAMI 提供从小型 CPU 引擎到高性能多 GPU 引擎的各种选择,并预配置了 CUDA、cuDNN,并附带了多种深度学习框架。
如果您想立即使用,您应该选择深度学习 AMI,因为它预装了流行的深度学习框架。
但是,如果您想为研究尝试自定义的深度学习框架,您应该安装深度学习基础 AMI,因为它附带了 CUDA、cuDNN、GPU 驱动程序等基本库以及运行您的深度学习环境所需的其他库。
如何在 Amazon SageMaker 上安装 Keras
Amazon SageMaker 是一个深度学习平台,可以帮助您使用最佳算法训练和部署深度学习网络。
作为初学者,这无疑是使用 Keras 最简单的方法。以下是在 Amazon SageMaker 上安装 Keras 的过程。
步骤 1) 打开 Amazon SageMaker
第一步,打开 Amazon Sagemaker 控制台,然后点击创建笔记本实例。

步骤 2) 输入详细信息
- 输入您的笔记本名称。
- 创建一个 IAM 角色。它将以 AmazonSageMaker-Executionrole-YYYYMMDD|HHmmSS 的格式创建一个 Amazon IAM 角色。
- 最后,选择创建笔记本实例。片刻之后,Amazon Sagemaker 会启动一个笔记本实例。
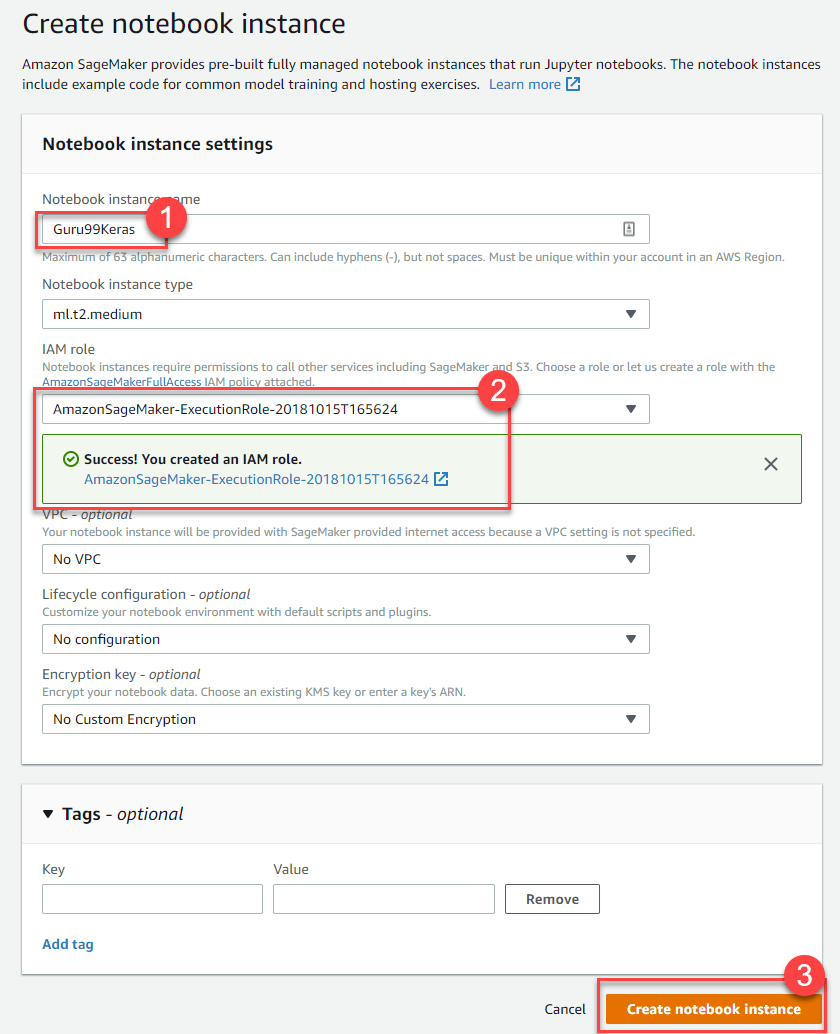
注意:如果您想从 VPC 访问资源,请将直接互联网访问设置为启用。否则,该笔记本实例将无法访问互联网,因此无法训练或托管模型。
步骤 3) 启动实例
点击“打开”以启动实例。

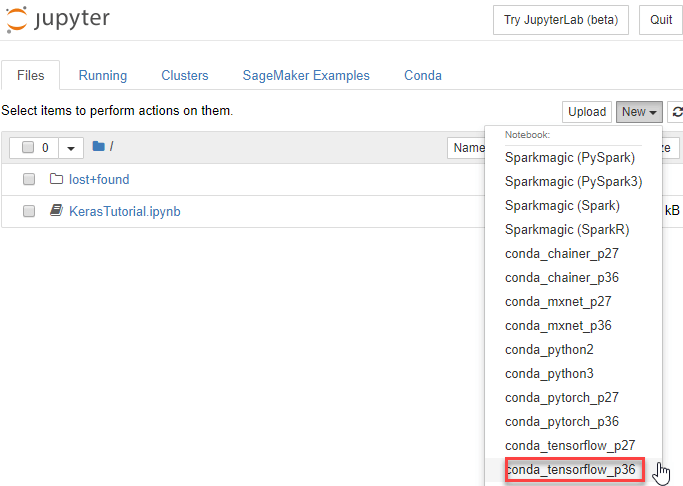
步骤 4) 开始编码
在 Jupyter 中,点击“新建”>“conda_tensorflow_p36”,然后您就可以开始编码了。
在 Linux 上安装 Keras
要启用以 Tensorflow 为后端引擎的 Keras,我们需要先安装 Tensorflow。运行此命令以安装 CPU 版本的 Tensorflow(无 GPU)。
pip install --upgrade tensorflow
如果你想为 tensorflow 启用 GPU 支持,你可以使用这个命令
pip install --upgrade tensorflow-gpu
让我们在 Python 中通过输入以下命令来检查安装是否成功:
user@user:~$ python Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow >>>
如果没有错误消息,则安装过程成功。
安装 Keras
安装完 Tensorflow 后,我们开始安装 Keras。在终端中输入此命令:
pip install keras
它将开始安装 Keras 及其所有依赖项。您应该会看到类似这样的内容:
现在我们的系统上已经安装了 Keras!
验证
在我们开始使用 Keras 之前,我们应该通过打开配置文件来检查我们的 Keras 是否使用 Tensorflow 作为其后端。
gedit ~/.keras/keras.json
你应该会看到类似这样的东西
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
如您所见,“backend” 使用的是 tensorflow。这意味着 keras 正在使用 Tensorflow 作为其后端,正如我们所预期的那样。
现在在终端中输入以下命令来运行它:
user@user:~$ python3 Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import keras Using TensorFlow backend. >>>
如何在 Windows 上安装 Keras
在我们安装 Tensorflow 和 Keras 之前,我们应该安装 Python、pip 和 virtualenv。如果您已经安装了这些库,您应该继续下一步,否则请执行以下操作。
通过此链接下载并安装 Python 3
通过运行此来安装 pip
使用此命令安装 virtualenv
pip3 install –U pip virtualenv
安装 Microsoft Visual C++ 2015 可再发行更新 3
- 前往 Visual Studio 下载网站 https://www.microsoft.com/en-us/download/details.aspx?id=53587
- 选择可再发行组件和生成工具
- 下载并安装 Microsoft Visual C++ 2015 可再发行更新 3
然后运行此脚本
pip3 install virtualenv
设置虚拟环境
这用于将工作系统与主系统隔离开来。
virtualenv –-system-site-packages –p python3 ./venv
激活环境
.\venv\Scripts\activate
在准备好环境后,Tensorflow 和 Keras 的安装过程与 Linux 相同。接下来,在本 Keras 深度学习教程中,我们将学习 Keras 深度学习的基础知识。
深度学习的 Keras 基础
Keras 中的主要结构是模型 (Model),它定义了一个网络的完整图。您可以向现有模型添加更多层,以构建您项目所需的自定义模型。
以下是如何创建一个序贯模型和一些深度学习中常用的层:
1. 序贯模型
from keras.models import Sequential from keras.layers import Dense, Activation,Conv2D,MaxPooling2D,Flatten,Dropout model = Sequential()
2. 卷积层
这是一个 Keras Python 示例,展示了一个作为输入层的卷积层,输入形状为 320x320x3,有 48 个大小为 3x3 的滤波器,并使用 ReLU 作为激活函数。
input_shape=(320,320,3) #this is the input shape of an image 320x320x3 model.add(Conv2D(48, (3, 3), activation='relu', input_shape= input_shape))
另一种类型是
model.add(Conv2D(48, (3, 3), activation='relu'))
3. 最大池化层
要对输入表示进行下采样,请使用 MaxPool2d 并指定内核大小。
model.add(MaxPooling2D(pool_size=(2, 2)))
4. 全连接层
只需指定输出大小即可添加一个全连接层。
model.add(Dense(256, activation='relu'))
5. Dropout 层
添加一个概率为 50% 的 dropout 层
model.add(Dropout(0.5))
编译、训练和评估
在我们定义了模型之后,让我们开始训练它们。首先需要使用损失函数和优化器函数来编译网络。这将允许网络改变权重并最小化损失。
model.compile(loss='mean_squared_error', optimizer='adam')
现在要开始训练,请使用 fit 将训练和验证数据馈送到模型中。这将允许您分批训练网络并设置轮次(epochs)。
model.fit(X_train, X_train, batch_size=32, epochs=10, validation_data=(x_val, y_val))
我们最后一步是使用测试数据来评估模型。
score = model.evaluate(x_test, y_test, batch_size=32)
让我们尝试使用简单的线性回归
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
import matplotlib.pyplot as plt
x = data = np.linspace(1,2,200)
y = x*4 + np.random.randn(*x.shape) * 0.3
model = Sequential()
model.add(Dense(1, input_dim=1, activation='linear'))
model.compile(optimizer='sgd', loss='mse', metrics=['mse'])
weights = model.layers[0].get_weights()
w_init = weights[0][0][0]
b_init = weights[1][0]
print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init))
model.fit(x,y, batch_size=1, epochs=30, shuffle=False)
weights = model.layers[0].get_weights()
w_final = weights[0][0][0]
b_final = weights[1][0]
print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final))
predict = model.predict(data)
plt.plot(data, predict, 'b', data , y, 'k.')
plt.show()
训练数据后,输出应该像这样:
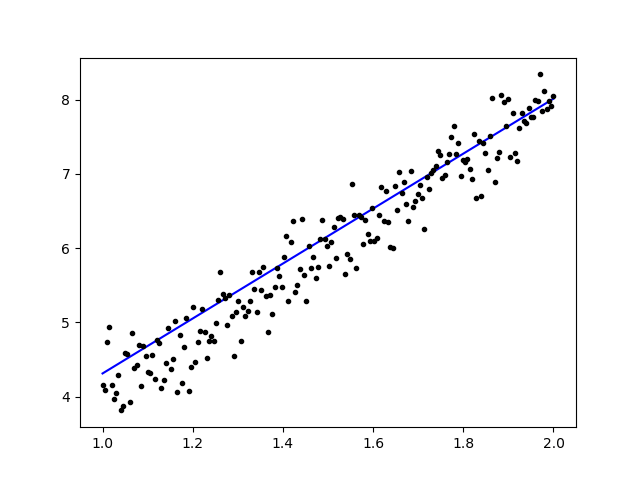
初始权重
Linear regression model is initialized with weights w: 0.37, b: 0.00
和最终权重
Linear regression model is trained to have weight w: 3.70, b: 0.61
在 Keras 中微调预训练模型及其使用方法
我们为什么以及何时使用微调模型
微调是一项调整预训练模型的任务,以便参数能够适应新模型。当我们想在新模型上从头开始训练时,我们需要大量数据,这样网络才能找到所有参数。但在这种情况下,我们将使用一个预训练模型,所以参数已经学习过了,并且有了权重。
例如,如果我们想训练自己的 Keras 模型来解决一个分类问题,但我们只有少量数据,那么我们可以通过使用迁移学习 + 微调方法来解决这个问题。
使用预训练的网络和权重,我们不需要训练整个网络。我们只需要训练用于解决我们任务的最后一层,我们称之为微调方法。
网络模型准备
对于预训练模型,我们可以加载 Keras 库中已有的各种模型,例如
- VGG16
- InceptionV3
- ResNet
- MobileNet
- Xception
- InceptionResNetV2
但在这个过程中,我们将使用 VGG16 网络模型和 imageNet 作为模型的权重。我们将微调一个网络来使用来自 Kaggle 自然图像数据集的图像对 8 种不同类型的类别进行分类。
VGG16 模型架构
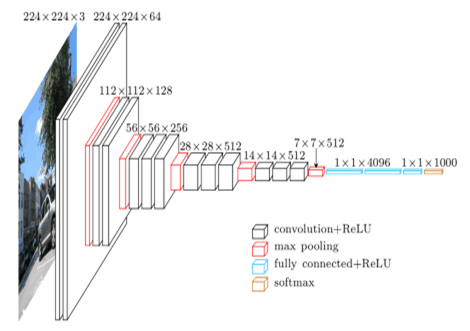
将我们的数据上传到 AWS S3 存储桶
对于我们的训练过程,我们将使用来自 8 个不同类别的自然图像,例如飞机、汽车、猫、狗、花、水果、摩托车和人。首先,我们需要将我们的数据上传到 Amazon S3 存储桶。
亚马逊 S3 存储桶
步骤 1) 登录您的 S3 账户后,让我们通过点击创建存储桶来创建一个存储桶。
步骤 2) 现在根据您的账户选择一个存储桶名称和您的区域。确保该存储桶名称可用。之后点击创建。
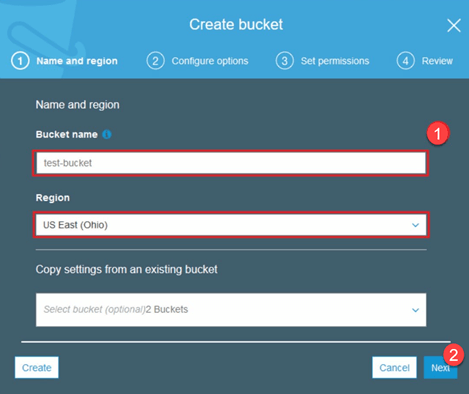
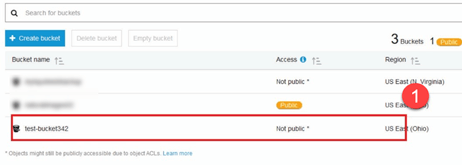
步骤 3) 如您所见,您的存储桶已准备就绪。但正如您所见,访问权限不是公开的,如果您想保持私有,这对您来说是好事。您可以在存储桶属性中将此存储桶更改为公开访问。
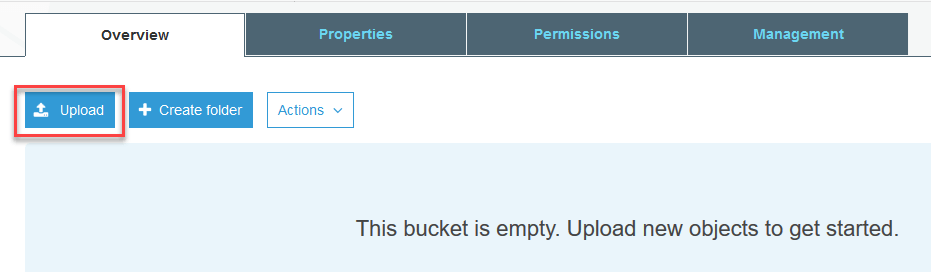
步骤 4) 现在您可以开始将您的训练数据上传到您的存储桶中。在这里,我将上传包含训练和测试过程图片的 tar.gz 文件。
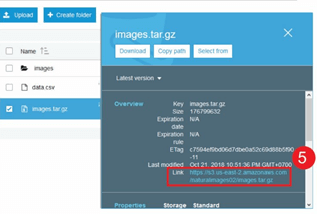
步骤 5) 现在点击您的文件并复制链接,以便我们可以下载它。
数据准备
我们需要使用 Keras 的 ImageDataGenerator 来生成我们的训练数据。
首先,您必须使用 wget 和您 S3 存储桶中文件的链接来下载。
!wget https://s3.us-east-2.amazonaws.com/naturalimages02/images.tar.gz !tar -xzf images.tar.gz
下载数据后,让我们开始训练过程。
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
train_path = 'images/train/'
test_path = 'images/test/'
batch_size = 16
image_size = 224
num_class = 8
train_datagen = ImageDataGenerator(validation_split=0.3,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
directory=train_path,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='categorical',
color_mode='rgb',
shuffle=True)
ImageDataGenerator 将从一个目录生成 X_training 数据。该目录中的子目录将用作每个对象的类别。图像将以 RGB 颜色模式加载,Y_training 数据使用分类类模式,批大小为 16。最后,对数据进行混洗。
让我们通过用 matplotlib 绘制它们来随机查看我们的图像。
x_batch, y_batch = train_generator.next()
fig=plt.figure()
columns = 4
rows = 4
for i in range(1, columns*rows):
num = np.random.randint(batch_size)
image = x_batch[num].astype(np.int)
fig.add_subplot(rows, columns, i)
plt.imshow(image)
plt.show()

之后,让我们从带有 imageNet 预训练权重的 VGG16 创建我们的网络模型。我们将冻结这些层,以便这些层不可训练,以帮助我们减少计算时间。
从 VGG16 创建我们的模型
import keras
from keras.models import Model, load_model
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.vgg16 import VGG16
#Load the VGG model
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
print(base_model.summary())
# Freeze the layers
for layer in base_model.layers:
layer.trainable = False
# # Create the model
model = keras.models.Sequential()
# # Add the vgg convolutional base model
model.add(base_model)
# # Add new layers
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(num_class, activation='softmax'))
# # Show a summary of the model. Check the number of trainable parameters
print(model.summary())
如下所示,是我们的网络模型摘要。从 VGG16 层的输入开始,然后我们添加了 2 个全连接层,它们将提取 1024 个特征,以及一个输出层,它将使用 softmax 激活函数计算 8 个类别。
Layer (type) Output Shape Param # ================================================================= vgg16 (Model) (None, 7, 7, 512) 14714688 _________________________________________________________________ flatten_1 (Flatten) (None, 25088) 0 _________________________________________________________________ dense_1 (Dense) (None, 1024) 25691136 _________________________________________________________________ dense_2 (Dense) (None, 1024) 1049600 _________________________________________________________________ dense_3 (Dense) (None, 8) 8200 ================================================================= Total params: 41,463,624 Trainable params: 26,748,936 Non-trainable params: 14,714,688
训练
# # Compile the model
from keras.optimizers import SGD
model.compile(loss='categorical_crossentropy',
optimizer=SGD(lr=1e-3),
metrics=['accuracy'])
# # Start the training process
# model.fit(x_train, y_train, validation_split=0.30, batch_size=32, epochs=50, verbose=2)
# # #save the model
# model.save('catdog.h5')
history = model.fit_generator(
train_generator,
steps_per_epoch=train_generator.n/batch_size,
epochs=10)
model.save('fine_tune.h5')
# summarize history for accuracy
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.title('loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['loss'], loc='upper left')
plt.show()
结果
Epoch 1/10 432/431 [==============================] - 53s 123ms/step - loss: 0.5524 - acc: 0.9474 Epoch 2/10 432/431 [==============================] - 52s 119ms/step - loss: 0.1571 - acc: 0.9831 Epoch 3/10 432/431 [==============================] - 51s 119ms/step - loss: 0.1087 - acc: 0.9871 Epoch 4/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0624 - acc: 0.9926 Epoch 5/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0591 - acc: 0.9938 Epoch 6/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0498 - acc: 0.9936 Epoch 7/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0403 - acc: 0.9958 Epoch 8/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0248 - acc: 0.9959 Epoch 9/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0466 - acc: 0.9942 Epoch 10/10 432/431 [==============================] - 52s 120ms/step - loss: 0.0338 - acc: 0.9947
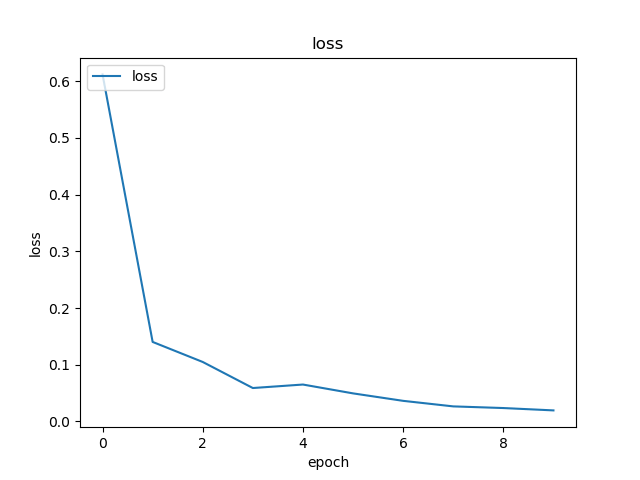
如您所见,我们的损失显著下降,准确率几乎达到 100%。为了测试我们的模型,我们从互联网上随机挑选图片,并将其放入测试文件夹中,用不同的类别进行测试。
测试我们的模型
model = load_model('fine_tune.h5')
test_datagen = ImageDataGenerator()
train_generator = train_datagen.flow_from_directory(
directory=train_path,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='categorical',
color_mode='rgb',
shuffle=True)
test_generator = test_datagen.flow_from_directory(
directory=test_path,
target_size=(image_size, image_size),
color_mode='rgb',
shuffle=False,
class_mode='categorical',
batch_size=1)
filenames = test_generator.filenames
nb_samples = len(filenames)
fig=plt.figure()
columns = 4
rows = 4
for i in range(1, columns*rows -1):
x_batch, y_batch = test_generator.next()
name = model.predict(x_batch)
name = np.argmax(name, axis=-1)
true_name = y_batch
true_name = np.argmax(true_name, axis=-1)
label_map = (test_generator.class_indices)
label_map = dict((v,k) for k,v in label_map.items()) #flip k,v
predictions = [label_map[k] for k in name]
true_value = [label_map[k] for k in true_name]
image = x_batch[0].astype(np.int)
fig.add_subplot(rows, columns, i)
plt.title(str(predictions[0]) + ':' + str(true_value[0]))
plt.imshow(image)
plt.show()
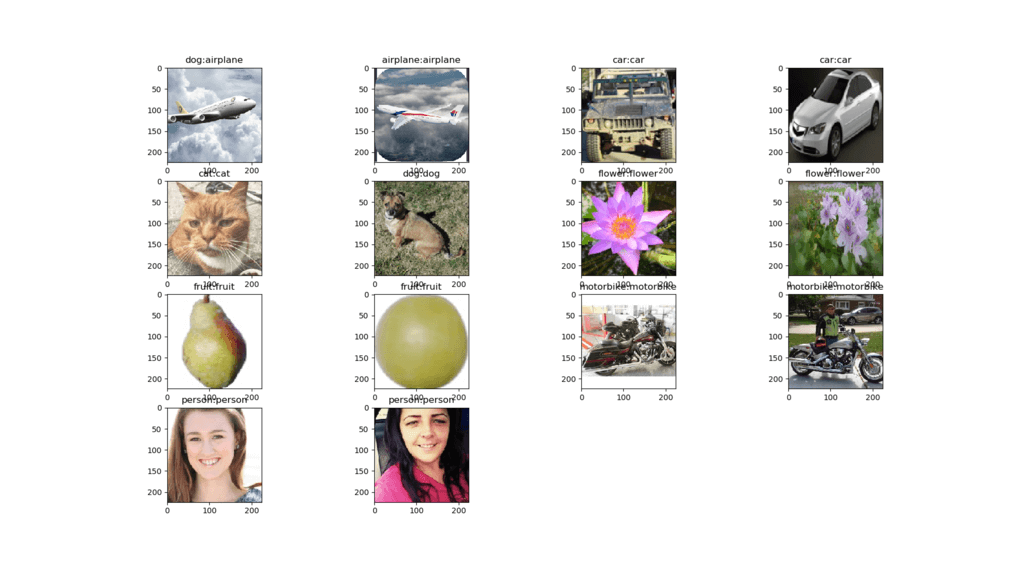
我们的测试结果如下!在 14 张图片的测试中,只有 1 张图片预测错误!
使用 Keras 的人脸识别神经网络
为什么我们需要识别
我们需要识别功能来更方便地识别或辨认一个人的脸、物体类型、从脸上估计一个人的年龄,甚至了解那个人的面部表情。
也许你每次在照片中标记朋友的脸时都会意识到,Facebook 的功能已经为你做好了,那就是在你需要标记之前就已经标记了你朋友的脸。这就是 Facebook 应用的人脸识别技术,让我们更容易地标记朋友。
那么它是如何工作的呢?每当我们标记我们朋友的脸时,Facebook 的人工智能就会学习它,并会尝试预测,直到得到正确的结果。我们将使用相同的系统来制作我们自己的人脸识别。让我们开始使用深度学习制作我们自己的人脸识别吧。
网络模型
我们将使用 VGG16 网络模型,但权重为 VGGFace。
VGG16 模型架构
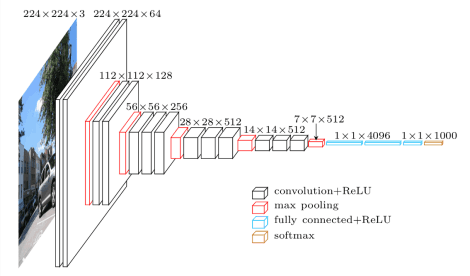
什么是 VGGFace?它是 Parkhi, Omkar M. 等人于《深度人脸识别》 BMVC (2015) 中介绍的深度人脸识别的 Keras 实现。该框架使用 VGG16 作为网络架构。
您可以从 github 下载 VGGFace。
from keras.applications.vgg16 import VGG16
from keras_vggface.vggface import VGGFace
face_model = VGGFace(model='vgg16',
weights='vggface',
input_shape=(224,224,3))
face_model.summary()
如您所见,网络摘要如下
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc6/relu (Activation) (None, 4096) 0 _________________________________________________________________ fc7 (Dense) (None, 4096) 16781312 _________________________________________________________________ fc7/relu (Activation) (None, 4096) 0 _________________________________________________________________ fc8 (Dense) (None, 2622) 10742334 _________________________________________________________________ fc8/softmax (Activation) (None, 2622) 0 ================================================================= Total params: 145,002,878 Trainable params: 145,002,878 Non-trainable params: 0 _________________________________________________________________ Traceback (most recent call last):
我们将进行迁移学习 + 微调,以使用小数据集加快训练速度。首先,我们将冻结基础层,以便这些层不可训练。
for layer in face_model.layers:
layer.trainable = False
然后我们添加我们自己的层来识别我们的测试人脸。我们将添加 2 个全连接层和一个输出层,用于检测 5 个人。
from keras.models import Model, Sequential
from keras.layers import Input, Convolution2D, ZeroPadding2D, MaxPooling2D, Flatten, Dense, Dropout, Activation
person_count = 5
last_layer = face_model.get_layer('pool5').output
x = Flatten(name='flatten')(last_layer)
x = Dense(1024, activation='relu', name='fc6')(x)
x = Dense(1024, activation='relu', name='fc7')(x)
out = Dense(person_count, activation='softmax', name='fc8')(x)
custom_face = Model(face_model.input, out)
让我们看看我们的网络摘要
Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 1024) 25691136 _________________________________________________________________ fc7 (Dense) (None, 1024) 1049600 _________________________________________________________________ fc8 (Dense) (None, 5) 5125 ================================================================= Total params: 41,460,549 Trainable params: 26,745,861 Non-trainable params: 14,714,688
如上所示,在 pool5 层之后,它将被展平为一个单一的特征向量,该向量将被密集层用于最终识别。
准备我们的面孔
现在让我们准备我们的面孔。我创建了一个包含5位名人的目录。
- 马云
- 杰森·斯坦森
- 约翰尼·德普
- 小罗伯特·唐尼
- 罗温·艾金森
每个文件夹包含 10 张图片,用于训练和评估过程。数据量非常小,但这正是挑战所在,对吧?
我们将借助 Keras 工具来帮助我们准备数据。这个函数将遍历数据集文件夹,然后准备好数据以便在训练中使用。
from keras.preprocessing.image import ImageDataGenerator
batch_size = 5
train_path = 'data/'
eval_path = 'eval/'
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
valid_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
train_path,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='sparse',
color_mode='rgb')
valid_generator = valid_datagen.flow_from_directory(
directory=eval_path,
target_size=(224, 224),
color_mode='rgb',
batch_size=batch_size,
class_mode='sparse',
shuffle=True,
)
训练我们的模型
让我们通过用损失函数和优化器编译我们的网络来开始我们的训练过程。在这里,我们使用 sparse_categorical_crossentropy 作为我们的损失函数,并借助 SGD 作为我们的学习优化器。
from keras.optimizers import SGD
custom_face.compile(loss='sparse_categorical_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
history = custom_face.fit_generator(
train_generator,
validation_data=valid_generator,
steps_per_epoch=49/batch_size,
validation_steps=valid_generator.n,
epochs=50)
custom_face.evaluate_generator(generator=valid_generator)
custom_face.save('vgg_face.h5')
Epoch 25/50
10/9 [==============================] - 60s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5659 - val_acc: 0.5851
Epoch 26/50
10/9 [==============================] - 59s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5638 - val_acc: 0.5809
Epoch 27/50
10/9 [==============================] - 60s 6s/step - loss: 1.4779 - acc: 0.8597 - val_loss: 1.5613 - val_acc: 0.5477
Epoch 28/50
10/9 [==============================] - 60s 6s/step - loss: 1.4755 - acc: 0.9199 - val_loss: 1.5576 - val_acc: 0.5809
Epoch 29/50
10/9 [==============================] - 60s 6s/step - loss: 1.4794 - acc: 0.9153 - val_loss: 1.5531 - val_acc: 0.5892
Epoch 30/50
10/9 [==============================] - 60s 6s/step - loss: 1.4714 - acc: 0.8953 - val_loss: 1.5510 - val_acc: 0.6017
Epoch 31/50
10/9 [==============================] - 60s 6s/step - loss: 1.4552 - acc: 0.9199 - val_loss: 1.5509 - val_acc: 0.5809
Epoch 32/50
10/9 [==============================] - 60s 6s/step - loss: 1.4504 - acc: 0.9199 - val_loss: 1.5492 - val_acc: 0.5975
Epoch 33/50
10/9 [==============================] - 60s 6s/step - loss: 1.4497 - acc: 0.8998 - val_loss: 1.5490 - val_acc: 0.5851
Epoch 34/50
10/9 [==============================] - 60s 6s/step - loss: 1.4453 - acc: 0.9399 - val_loss: 1.5529 - val_acc: 0.5643
Epoch 35/50
10/9 [==============================] - 60s 6s/step - loss: 1.4399 - acc: 0.9599 - val_loss: 1.5451 - val_acc: 0.5768
Epoch 36/50
10/9 [==============================] - 60s 6s/step - loss: 1.4373 - acc: 0.8998 - val_loss: 1.5424 - val_acc: 0.5768
Epoch 37/50
10/9 [==============================] - 60s 6s/step - loss: 1.4231 - acc: 0.9199 - val_loss: 1.5389 - val_acc: 0.6183
Epoch 38/50
10/9 [==============================] - 59s 6s/step - loss: 1.4247 - acc: 0.9199 - val_loss: 1.5372 - val_acc: 0.5934
Epoch 39/50
10/9 [==============================] - 60s 6s/step - loss: 1.4153 - acc: 0.9399 - val_loss: 1.5406 - val_acc: 0.5560
Epoch 40/50
10/9 [==============================] - 60s 6s/step - loss: 1.4074 - acc: 0.9800 - val_loss: 1.5327 - val_acc: 0.6224
Epoch 41/50
10/9 [==============================] - 60s 6s/step - loss: 1.4023 - acc: 0.9800 - val_loss: 1.5305 - val_acc: 0.6100
Epoch 42/50
10/9 [==============================] - 59s 6s/step - loss: 1.3938 - acc: 0.9800 - val_loss: 1.5269 - val_acc: 0.5975
Epoch 43/50
10/9 [==============================] - 60s 6s/step - loss: 1.3897 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.6432
Epoch 44/50
10/9 [==============================] - 60s 6s/step - loss: 1.3828 - acc: 0.9800 - val_loss: 1.5210 - val_acc: 0.6556
Epoch 45/50
10/9 [==============================] - 59s 6s/step - loss: 1.3848 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.5975
Epoch 46/50
10/9 [==============================] - 60s 6s/step - loss: 1.3716 - acc: 0.9800 - val_loss: 1.5216 - val_acc: 0.6432
Epoch 47/50
10/9 [==============================] - 60s 6s/step - loss: 1.3721 - acc: 0.9800 - val_loss: 1.5195 - val_acc: 0.6266
Epoch 48/50
10/9 [==============================] - 60s 6s/step - loss: 1.3622 - acc: 0.9599 - val_loss: 1.5108 - val_acc: 0.6141
Epoch 49/50
10/9 [==============================] - 60s 6s/step - loss: 1.3452 - acc: 0.9399 - val_loss: 1.5140 - val_acc: 0.6432
Epoch 50/50
10/9 [==============================] - 60s 6s/step - loss: 1.3387 - acc: 0.9599 - val_loss: 1.5100 - val_acc: 0.6266
如您所见,我们的验证准确率高达 64%,这对于少量训练数据来说是一个不错的结果。我们可以通过添加更多层或更多训练图像来改进这一点,这样我们的模型就可以学习更多关于人脸的知识,从而获得更高的准确率。
让我们用一张测试图片来测试我们的模型。

from keras.models import load_model
from keras.preprocessing.image import load_img, save_img, img_to_array
from keras_vggface.utils import preprocess_input
test_img = image.load_img('test.jpg', target_size=(224, 224))
img_test = image.img_to_array(test_img)
img_test = np.expand_dims(img_test, axis=0)
img_test = utils.preprocess_input(img_test)
predictions = model.predict(img_test)
predicted_class=np.argmax(predictions,axis=1)
labels = (train_generator.class_indices)
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class]
print(predictions)
['RobertDJr']
使用小罗伯特·唐尼的图片作为我们的测试图片,结果显示预测的人脸是正确的!
使用实时摄像头进行预测!
如果我们用网络摄像头的输入来实现它来测试我们的技能怎么样?使用 OpenCV 和 Haar 人脸级联分类器来找到我们的脸,并在我们的网络模型的帮助下,我们可以识别出这个人。
第一步是准备你和你朋友的脸。我们拥有的数据越多,结果就越好!
像上一步一样准备和训练你的网络,训练完成后,添加这一行来从摄像头获取输入图像。
#Load trained model
from keras.models import load_model
from keras_vggface import utils
import cv2
image_size = 224
device_id = 0 #camera_device id
model = load_model('my faces.h5')
#make labels according to your dataset folder
labels = dict(fisrtname=0,secondname=1) #and so on
print(labels)
cascade_classifier = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
camera = cv2.VideoCapture(device_id)
while camera.isOpened():
ok, cam_frame = camera.read()
if not ok:
break
gray_img=cv2.cvtColor(cam_frame, cv2.COLOR_BGR2GRAY)
faces= cascade_classifier.detectMultiScale(gray_img, minNeighbors=5)
for (x,y,w,h) in faces:
cv2.rectangle(cam_frame,(x,y),(x+w,y+h),(255,255,0),2)
roi_color = cam_frame [y:y+h, x:x+w]
roi color = cv2.cvtColor(roi_color, cv2.COLOR_BGR2RGB)
roi_color = cv2.resize(roi_color, (image_size, image_size))
image = roi_color.astype(np.float32, copy=False)
image = np.expand_dims(image, axis=0)
image = preprocess_input(image, version=1) # or version=2
preds = model.predict(image)
predicted_class=np.argmax(preds,axis=1)
labels = dict((v,k) for k,v in labels.items())
name = [labels[k] for k in predicted_class]
cv2.putText(cam_frame,str(name),
(x + 10, y + 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,255), 2)
cv2.imshow('video image', cam_frame)
key = cv2.waitKey(30)
if key == 27: # press 'ESC' to quit
break
camera.release()
cv2.destroyAllWindows()
Keras 和 Tensorflow 哪个更好?
Keras 在编写脚本时提供了简洁性。我们可以直接用 Keras 开始编写和理解,因为它不太难理解。它更用户友好,易于实现,不需要创建许多变量来运行模型。因此,我们不需要了解后端过程中的每一个细节。
另一方面,Tensorflow 是底层操作,如果您想制作任意的计算图或模型,它提供了灵活性和高级操作。Tensorflow 还可以借助 TensorBoard 和专门的调试器工具来可视化过程。
所以,如果你想开始学习深度学习,又不想太复杂,那就用 Keras。因为 Keras 提供了简洁性和用户友好性,比 Tensorflow 更易于使用和实现。但如果你想在深度学习项目或研究中编写自己的算法,你应该使用 Tensorflow。
摘要
那么,让我们总结一下我们在本教程中讨论和完成的所有内容。
- Keras 是一个高级 API,用于借助后端引擎使深度学习网络更容易构建。
- Keras 易于使用和理解,并支持 Python,因此感觉比以往任何时候都更自然。它非常适合想要学习深度学习的初学者,以及想要易于使用的 API 的研究人员。
- 安装过程很简单,您可以使用虚拟环境或使用外部平台,如 AWS。
- Keras 还附带了各种网络模型,这使我们更容易使用现有模型来预训练和微调我们自己的网络模型。
- 此外,全球社区有大量关于使用 Keras 的教程和文章,提供了用于深度学习目的的代码。