带 Facet 和交互项的 TensorFlow 线性回归
在本教程中,您将学习如何检查数据并进行准备,以创建简单的线性回归任务。
本教程分为两部分
- 寻找交互作用
- 测试模型
在上一教程中,您使用了波士顿数据集来估算房屋的中位数价格。波士顿数据集的规模较小,只有506个观测值。该数据集被认为是尝试新线性回归算法的基准。
该数据集包含
| 变量 | 描述 |
|---|---|
| zn | 每镇25,000平方英尺以上住宅用地所占比例。 |
| indus | 每镇非零售商业用地所占比例。 |
| nox | 氮氧化物浓度 |
| rm | 每户平均房间数 |
| age | 1940年前自住单位的比例 |
| dis | 到五个波士顿就业中心的加权距离 |
| tax | 每10,000美元的房产总税率 |
| ptratio | 每镇学生教师比例 |
| medv | 自住房屋的中位数价格(千美元) |
| crim | 每镇人均犯罪率 |
| chas | 查尔斯河虚拟变量(1如果临近河流;0否则) |
| B | 每镇黑人比例 |
在本教程中,我们将使用线性回归器来估算中位数价格,但重点将放在机器学习的一个特定过程:“数据准备”。
模型是对数据中模式的泛化。要捕捉这种模式,您需要先找到它。在运行任何机器学习算法之前,进行数据分析是一个好习惯。
选择正确的特征对模型的成功至关重要。想象一下,您试图估算一个人的工资,如果您不将性别作为协变量包含在内,您最终会得到一个糟糕的估算。
另一种改进模型的方法是查看自变量之间的相关性。回到之前的例子,您可以认为教育是一个预测工资的绝佳候选变量,而职业也是。公平地说,职业取决于教育程度,也就是说,更高的教育程度通常会导致更好的职业。如果我们推广这个想法,我们可以说因变量与解释变量之间的相关性可以被另一个解释变量所放大。
为了捕捉教育对职业的有限影响,我们可以使用交互项。

如果查看工资方程,它将变成
![]()
如果 ![]() 为正,则意味着教育程度的提高会使高职业水平下房屋中位价的增幅更大。换句话说,教育和职业之间存在交互作用。
为正,则意味着教育程度的提高会使高职业水平下房屋中位价的增幅更大。换句话说,教育和职业之间存在交互作用。
在本教程中,我们将尝试查看哪些变量可以作为交互项的良好候选。我们将测试添加此类信息是否能带来更好的价格预测。
摘要统计
在继续进行模型之前,您可以遵循几个步骤。如前所述,模型是数据的泛化。最佳实践是理解数据,然后进行预测。如果您不了解数据,那么改进模型的机会就很渺茫。
第一步,将数据加载为 pandas 数据框,并创建训练集和测试集。
提示:在本教程中,您需要安装 matplotlit 和 seaborn。您可以使用Jupyter即时安装 Python 包。您不应这样做
!conda install -- yes matplotlib
但
import sys
!{sys.executable} -m pip install matplotlib # Already installed
!{sys.executable} -m pip install seaborn
请注意,如果您已经安装了 matplotlib 和 seaborn,则此步骤不是必需的。
Matplotlib 是在Python中创建图表的库。Seaborn 是一个建立在 matplotlib 之上的统计可视化库。它提供了吸引人且精美的图表。
下面的代码导入了必要的库。
import pandas as pd from sklearn import datasets import tensorflow as tf from sklearn.datasets import load_boston import numpy as np
sklearn 库包含 Boston 数据集。您可以调用其 API 来导入数据。
boston = load_boston() df = pd.DataFrame(boston.data)
特征名称存储在 feature_names 对象中,以数组形式。
boston.feature_names
输出
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
您可以重命名列。
df.columns = boston.feature_names df['PRICE'] = boston.target df.head(2)

您将 CHAS 变量转换为字符串变量,并将其标记为 yes(如果 CHAS = 1)和 no(如果 CHAS = 0)。
df['CHAS'] = df['CHAS'].map({1:'yes', 0:'no'})
df['CHAS'].head(5)
0 no
1 no
2 no
3 no
4 no
Name: CHAS, dtype: object
使用 pandas,拆分数据集非常简单。您将数据集随机划分为80%的训练集和20%的测试集。Pandas有一个内置的函数来拆分数据框样本。
第一个参数 frac 是一个介于0到1之间的值。您将其设置为0.8以随机选择数据框的80%。
Random_state 允许每个人获得相同的数据框。
### Create train/test set df_train=df.sample(frac=0.8,random_state=200) df_test=df.drop(df_train.index)
您可以获取数据的形状。它应该是
- 训练集:506*0.8 = 405
- 测试集:506*0.2 = 101
print(df_train.shape, df_test.shape)
输出
(405, 14) (101, 14)
df_test.head(5)
输出
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | PRICE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | no | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | no | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 3 | 0.03237 | 0.0 | 2.18 | no | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 6 | 0.08829 | 12.5 | 7.87 | no | 0.524 | 6.012 | 66.6 | 5.5605 | 5.0 | 311.0 | 15.2 | 395.60 | 12.43 | 22.9 |
| 7 | 0.14455 | 12.5 | 7.87 | no | 0.524 | 6.172 | 96.1 | 5.9505 | 5.0 | 311.0 | 15.2 | 396.90 | 19.15 | 27.1 |
数据是混乱的;它通常是不平衡的,并散布着会影响分析和机器学习训练的异常值。
整理数据集的第一步是了解它需要在哪里进行清理。整理数据集可能很棘手,尤其是要以任何可推广的方式进行。
Google Research 团队开发了一个名为Facets的工具来完成这项工作,该工具可以帮助可视化数据并以各种方式对其进行切片。这是理解数据集布局的好起点。
Facets 可以帮助您找到数据与您设想的不符之处。
除了其 Web 应用程序外,Google 还方便将该工具包嵌入 Jupyter notebook 中。
Facets 有两个部分
- Facets概览
- Facets深度剖析
Facets概览
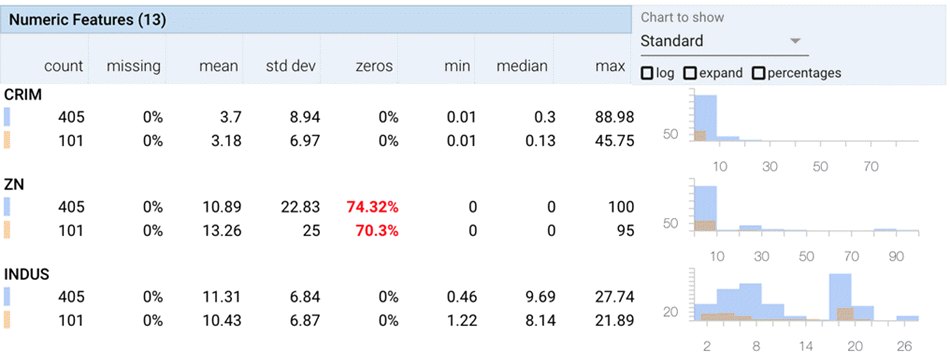
Facets Overview 提供了数据集的概览。Facets Overview 将数据的列拆分为包含关键信息的行,显示
- 缺失观测值的百分比
- 最小值和最大值
- 统计数据,如平均值、中位数和标准差。
- 它还添加了一个显示零值百分比的列,这在大多数值为零时很有用。
- 可以查看测试数据集以及训练集中每个特征的这些分布。这意味着您可以仔细检查测试集是否与训练数据具有相似的分布。
在进行任何机器学习任务之前,这是至少应该做的。有了这个工具,您就不会错过这个关键步骤,它还会突出一些异常情况。
Facets深度剖析
Facets Deep Dive 是一个很棒的工具。它可以让您更清晰地了解数据集,并放大到查看单个数据。这意味着您可以按行和按列对数据集的任何特征进行分面。
我们将使用这两个工具处理 Boston 数据集。
注意:您不能同时使用 Facets Overview 和 Facets Deep Dive。您需要先清除 notebook 才能更改工具。
安装 Facet
您可以使用 Facet Web 应用程序进行大部分分析。在本教程中,您将了解如何在 Jupyter Notebook 中使用它。
首先,您需要安装 nbextensions。可以使用此代码完成。您将以下代码复制并粘贴到您机器的终端中。
pip install jupyter_contrib_nbextensions
之后,您需要将存储库克隆到您的计算机。您有两种选择
选项 1)将此代码复制并粘贴到终端中(推荐)
如果您尚未在计算机上安装 Git,请访问此 URL https://git-scm.cn/download/win 并按照说明操作。完成后,您可以在 Mac 用户的终端或 Windows 用户的 Anaconda prompt 中使用 git 命令。
git clone https://github.com/PAIR-code/facets
选项 2)前往 https://github.com/PAIR-code/facets 并下载存储库。
如果选择第一种选项,文件将保存在您的下载文件夹中。您可以将文件保留在下载文件夹中,也可以将其拖到其他路径。
您可以使用此命令行检查 Facets 的存储位置
echo `pwd`/`ls facets`
现在您已经找到了 Facets,需要将其安装到 Jupyter Notebook 中。您需要将工作目录设置为 facets 所在路径。
您的当前工作目录和 Facets zip 的位置应相同。
您需要将工作目录指向 Facet
cd facets
要在 Jupyter 中安装 Facets,您有两种选择。如果您为所有用户安装了 Jupyter,请复制此代码
可以使用 jupyter nbextension install facets-dist/
jupyter nbextension install facets-dist/
否则,请使用
jupyter nbextension install facets-dist/ --user
好的,您已经准备就绪。让我们打开 Facet Overview。
概述
Overview 使用 Python 脚本来计算统计数据。您需要将名为 generic_feature_statistics_generator 的脚本导入 Jupyter。不用担心,脚本位于 facets 文件中。
您需要找到它的路径。这很容易做到。打开 facets,打开 facets_overview 文件,然后是 python。复制路径
之后,返回 Jupyter,然后编写以下代码。将路径 ‘/Users/Thomas/facets/facets_overview/python’ 更改为您的路径。
# Add the facets overview python code to the python path# Add t
import sys
sys.path.append('/Users/Thomas/facets/facets_overview/python')
您可以使用以下代码导入脚本。
from generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
在 Windows 中,相同的代码变成
import sys sys.path.append(r"C:\Users\Admin\Anaconda3\facets-master\facets_overview\python") from generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
要计算特征统计信息,您需要使用 GenericFeatureStatisticsGenerator() 函数,并使用 ProtoFromDataFrames 对象。您可以将数据框存储在字典中。例如,如果我们想为训练集创建摘要统计信息,我们可以将信息存储在字典中,并在 ProtoFromDataFrames 对象中使用它。
-
'name': 'train', 'table': df_train
Name 是表中显示的名称,您使用要计算摘要的表的名称。在您的示例中,包含数据的表是 df_train。
# Calculate the feature statistics proto from the datasets and stringify it for use in facets overview
import base64
gfsg = GenericFeatureStatisticsGenerator()
proto = gfsg.ProtoFromDataFrames([{'name': 'train', 'table': df_train},
{'name': 'test', 'table': df_test}])
#proto = gfsg.ProtoFromDataFrames([{'name': 'train', 'table': df_train}])
protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8")
最后,您只需复制并粘贴以下代码。代码直接来自 GitHub。您应该能看到这个
# Display the facets overview visualization for this data# Displ
from IPython.core.display import display, HTML
HTML_TEMPLATE = """<link rel="import" href="/nbextensions/facets-dist/facets-jupyter.html" >
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))
图表
在检查数据及其分布后,您可以绘制相关矩阵。相关矩阵计算皮尔逊系数。该系数的范围在 -1 到 1 之间,正值表示正相关,负值表示负相关。
您有兴趣查看哪些变量可以作为交互项的良好候选。
## Choose important feature and further check with Dive
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="ticks")
# Compute the correlation matrix
corr = df.corr('pearson')
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,annot=True,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
输出
<matplotlib.axes._subplots.AxesSubplot at 0x1a184d6518>
png
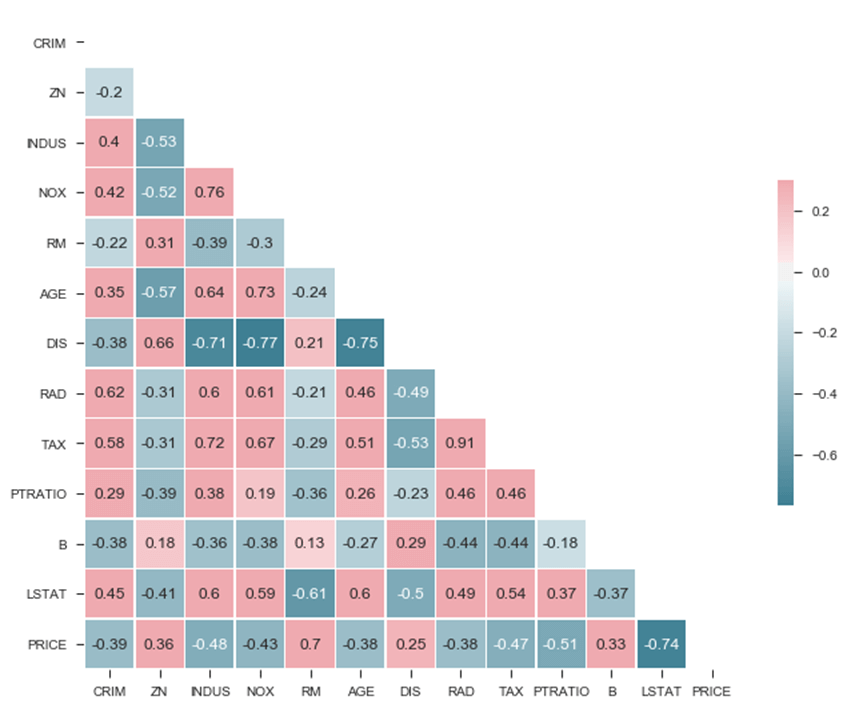
从矩阵中,您可以看到
- LSTAT
- RM
与 PRICE 强相关。另一个有趣的特征是 NOX 和 INDUS 之间存在很强的正相关,这意味着这两个变量同向移动。此外,它们也与 PRICE 相关。DIS 也与 IND 和 NOX 高度相关。
您初步了解到 IND 和 NOX 可以作为截距项的良好候选,而 DIS 也可能值得关注。
您可以更深入一些,绘制一个对网格图。它将更详细地说明您之前绘制的相关性图。
我们绘制的对网格图组成如下
- 上半部分:带拟合线的散点图
- 对角线:核密度图
- 下半部分:多元核密度图
您选择关注四个自变量。选择对应于与 PRICE 强相关的变量。
- INDUS
- NOX
- RM
- LSTAT
此外,还有 PRICE。
请注意,标准误差会默认添加到散点图中。
attributes = ["PRICE", "INDUS", "NOX", "RM", "LSTAT"] g = sns.PairGrid(df[attributes]) g = g.map_upper(sns.regplot, color="g") g = g.map_lower(sns.kdeplot,cmap="Reds", shade=True, shade_lowest=False) g = g.map_diag(sns.kdeplot)
输出
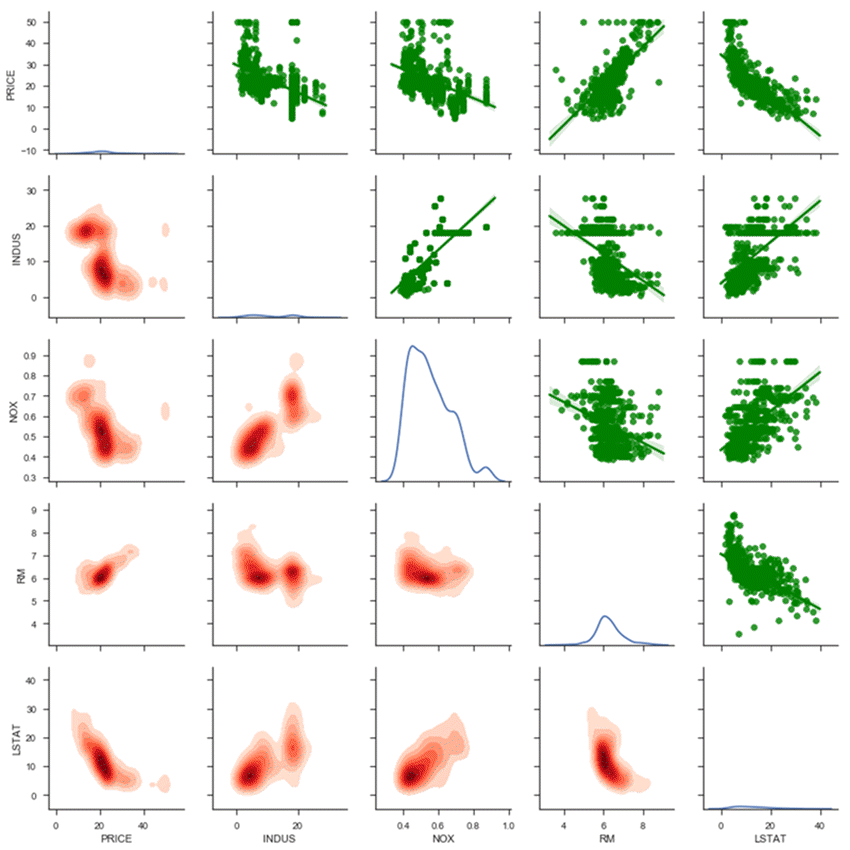
让我们从上半部分开始
- Price 与 INDUS、NOX 和 LSTAT 呈负相关;与 RM 呈正相关。
- LSTAT 和 PRICE 之间存在轻微的非线性关系。
- 当价格等于 50 时,看起来像一条直线。根据数据集的描述,PRICE 在 50 的值处被截断了。
对角线
- NOX 似乎有两个簇,一个在 0.5 左右,一个在 0.85 左右。
要详细了解,您可以查看下半部分。多元核密度图很有意义,因为它为大多数点着色。与散点图的区别在于,即使对于给定的坐标没有数据点,它也会绘制概率密度。当颜色越深时,表示该区域周围点的浓度越高。
如果您查看 INDUS 和 NOX 的多元密度,您可以看到正相关和两个簇。当工业份额超过 18 时,氮氧化物浓度超过 0.6。
您可以考虑在线性关系中添加 INDUS 和 NOX 之间的交互。
最后,您可以使用 Google 创建的第二个工具 Facets Deep Dive。该界面分为四个主要部分。中心区域是数据的可缩放显示。在面板顶部,有一个下拉菜单,您可以在其中更改数据的排列以控制分面、定位和颜色。右侧是特定数据行的详细视图。这意味着您可以点击中心可视化中的任何数据点来查看该特定数据点的详细信息。
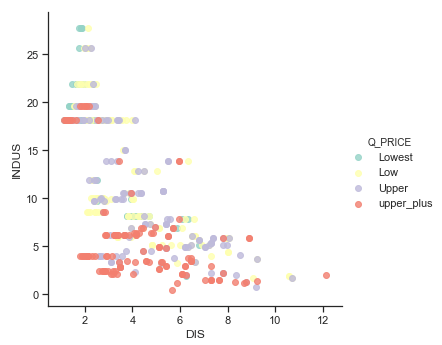
在数据可视化步骤中,您有兴趣查看自变量与房屋价格之间的成对相关性。但这至少涉及三个变量,并且 3D 图很难处理。
解决此问题的一种方法是创建分类变量。也就是说,我们可以创建 2D 图并为点着色。您可以将 PRICE 变量分为四个类别,每个类别是一个四分位数(即 0.25、0.5、0.75)。我们称这个新变量为 Q_PRICE。
## Check non linearity with important features df['Q_PRICE'] = pd.qcut(df['PRICE'], 4, labels=["Lowest", "Low", "Upper", "upper_plus"]) ## Show non linearity between RM and LSTAT ax = sns.lmplot(x="DIS", y="INDUS", hue="Q_PRICE", data=df, fit_reg = False,palette="Set3")
Facets深度剖析
要打开 Deep Dive,您需要将数据转换为 json 格式。Pandas 有一个用于此的对象。您可以在 Pandas 数据集后使用 to_json。
第一行代码处理数据集的大小。
df['Q_PRICE'] = pd.qcut(df['PRICE'], 4, labels=["Lowest", "Low", "Upper", "upper_plus"]) sprite_size = 32 if len(df.index)>50000 else 64 jsonstr = df.to_json(orient='records')
下面的代码来自 Google GitHub。运行代码后,您应该能看到这个
# Display thde Dive visualization for this data
from IPython.core.display import display, HTML
# Create Facets template
HTML_TEMPLATE = """<link rel="import" href="/nbextensions/facets-dist/facets-jupyter.html">
<facets-dive sprite-image-width="{sprite_size}" sprite-image-height="{sprite_size}" id="elem" height="600"></facets-dive>
<script>
document.querySelector("#elem").data = {jsonstr};
</script>"""
# Load the json dataset and the sprite_size into the template
html = HTML_TEMPLATE.format(jsonstr=jsonstr, sprite_size=sprite_size)
# Display the template
display(HTML(html))
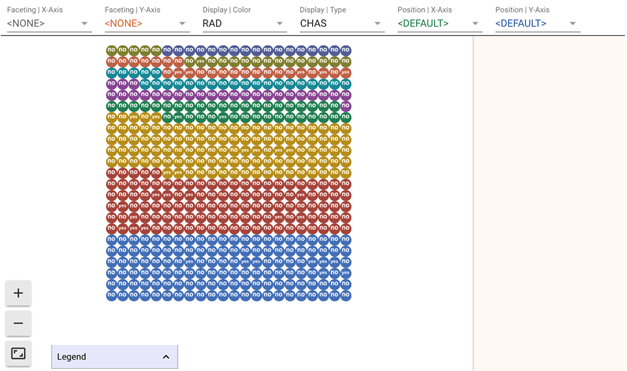
您有兴趣查看行业费率、氧化物浓度、到工作中心的距离与房价之间是否存在联系。
为此,您首先按行业范围拆分数据,并按房价四分位数着色。
- 选择 faceting X 并选择 INDUS。
- 选择 Display 并选择 DIS。这将根据房屋价格的四分位数对点进行着色。
在这里,颜色越深表示到第一个工作中心的距离越远。
到目前为止,它再次显示了您所知道的,较低的行业费率,较高的价格。现在您可以按 INDUX、按 NOX 进行细分。
- 选择 faceting Y 并选择 NOX。
现在您可以看到离第一个工作中心远的房屋拥有最低的行业份额,因此氧化物浓度最低。如果您选择以 Q_PRICE 显示类型并放大左下角,您可以看到它是哪种价格类型。
您还有另一个线索,IND、NOX 和 DIS 之间的交互作用可能可以很好地改进模型。
TensorFlow
在本节中,您将使用 TensorFlow Estimators API 来估算线性分类器。您将按以下步骤进行:
- 准备数据
- 估算基准模型:无交互作用
- 估算带交互作用的模型
请记住,机器学习的目标是最小化误差。在这种情况下,均方误差最低的模型将获胜。TensorFlow Estimator 会自动计算此指标。
数据准备
在大多数情况下,您需要转换数据。这就是为什么 Facets Overview 如此引人入胜。从摘要统计中,您可以看到存在异常值。这些值会影响估算,因为它们不像您正在分析的人群。异常值通常会使结果产生偏差。例如,正异常值倾向于高估系数。
解决此问题的一个好方法是标准化变量。标准化意味着标准差为一,均值为零。标准化过程包括两个步骤。首先,它减去变量的平均值。其次,它除以标准差,使分布具有单位标准差。
sklearn 库有助于标准化变量。您可以为此目的使用预处理模块和 scale 对象。
您可以使用以下函数来缩放数据集。请注意,您不缩放标签列和分类变量。
from sklearn import preprocessing
def standardize_data(df):
X_scaled = preprocessing.scale(df[['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT']])
X_scaled_df = pd.DataFrame(X_scaled, columns = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'])
df_scale = pd.concat([X_scaled_df,
df['CHAS'],
df['PRICE']],axis=1, join='inner')
return df_scale
您可以使用该函数来构建缩放后的训练/测试集。
df_train_scale = standardize_data(df_train) df_test_scale = standardize_data(df_test)
基本回归:基准
首先,您将训练并测试一个没有交互作用的模型。目的是查看模型的性能指标。
训练模型的方式与“高级 API”教程完全相同。您将使用 TensorFlow Estimator LinearRegressor。
作为回顾,您需要选择
- 要放入模型的特征
- 转换特征
- 构建线性回归器
- 构建 input_fn 函数
- 训练模型
- 测试模型
您使用数据集中的所有变量来训练模型。总共有十一个连续变量和一个分类变量。
## Add features to the bucket: ### Define continuous list CONTI_FEATURES = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT'] CATE_FEATURES = ['CHAS']
您将特征转换为数值列或分类列。
continuous_features = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES]
#categorical_features = tf.feature_column.categorical_column_with_hash_bucket(CATE_FEATURES, hash_bucket_size=1000)
categorical_features = [tf.feature_column.categorical_column_with_vocabulary_list('CHAS', ['yes','no'])]
您使用 linearRegressor 创建模型。您将模型存储在 train_Boston 文件夹中。
model = tf.estimator.LinearRegressor(
model_dir="train_Boston",
feature_columns=categorical_features + continuous_features)
输出
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'train_Boston', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a19e76ac8>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
训练或测试数据中的每一列都通过 get_input_fn 函数转换为 Tensor。
FEATURES = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT', 'CHAS']
LABEL= 'PRICE'
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
您在训练数据上估算模型。
model.train(input_fn=get_input_fn(df_train_scale,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
输出
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train_Boston/model.ckpt. INFO:tensorflow:loss = 56417.703, step = 1 INFO:tensorflow:global_step/sec: 144.457 INFO:tensorflow:loss = 76982.734, step = 101 (0.697 sec) INFO:tensorflow:global_step/sec: 258.392 INFO:tensorflow:loss = 21246.334, step = 201 (0.383 sec) INFO:tensorflow:global_step/sec: 227.998 INFO:tensorflow:loss = 30534.78, step = 301 (0.439 sec) INFO:tensorflow:global_step/sec: 210.739 INFO:tensorflow:loss = 36794.5, step = 401 (0.477 sec) INFO:tensorflow:global_step/sec: 234.237 INFO:tensorflow:loss = 8562.981, step = 501 (0.425 sec) INFO:tensorflow:global_step/sec: 238.1 INFO:tensorflow:loss = 34465.08, step = 601 (0.420 sec) INFO:tensorflow:global_step/sec: 237.934 INFO:tensorflow:loss = 12241.709, step = 701 (0.420 sec) INFO:tensorflow:global_step/sec: 220.687 INFO:tensorflow:loss = 11019.228, step = 801 (0.453 sec) INFO:tensorflow:global_step/sec: 232.702 INFO:tensorflow:loss = 24049.678, step = 901 (0.432 sec) INFO:tensorflow:Saving checkpoints for 1000 into train_Boston/model.ckpt. INFO:tensorflow:Loss for final step: 23228.568. <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x1a19e76320>
最后,您估算模型在测试集上的性能。
model.evaluate(input_fn=get_input_fn(df_test_scale,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
输出
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-05-29-02:40:43
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train_Boston/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-05-29-02:40:43
INFO:tensorflow:Saving dict for global step 1000: average_loss = 86.89361, global_step = 1000, loss = 1650.9785
{'average_loss': 86.89361, 'global_step': 1000, 'loss': 1650.9785}
模型的损失为 1650。这是下一节需要打破的指标。
改进模型:交互项
在教程的第一部分,您看到了变量之间存在有趣的关联。不同的可视化技术表明 INDUS 和 NOS 相互关联,并会放大对价格的影响。不仅 INDUS 和 NOS 之间的交互作用影响价格,而且当它与 DIS 交互时,这种影响会更强。
现在是时候泛化这个想法,看看您是否可以改进模型预测。
您需要向每个数据集(训练集 + 测试集)添加两个新列。为此,您创建一个函数来计算交互项,再创建一个函数来计算三项交互作用。每个函数都会生成一个新列。在新变量创建后,您可以将它们连接到训练数据集和测试数据集。
首先,您需要为 INDUS 和 NOX 之间的交互创建一个新变量。
以下函数返回两个数据框,train 和 test,其中包含 var_1 和 var_2(在本例中为 INDUS 和 NOX)之间的交互作用。
def interaction_term(var_1, var_2, name):
t_train = df_train_scale[var_1]*df_train_scale[var_2]
train = t_train.rename(name)
t_test = df_test_scale[var_1]*df_test_scale[var_2]
test = t_test.rename(name)
return train, test
您存储这两个新列。
interation_ind_ns_train, interation_ind_ns_test= interaction_term('INDUS', 'NOX', 'INDUS_NOS')
interation_ind_ns_train.shape
(325,)
其次,您创建第二个函数来计算三项交互作用。
def triple_interaction_term(var_1, var_2,var_3, name):
t_train = df_train_scale[var_1]*df_train_scale[var_2]*df_train_scale[var_3]
train = t_train.rename(name)
t_test = df_test_scale[var_1]*df_test_scale[var_2]*df_test_scale[var_3]
test = t_test.rename(name)
return train, test
interation_ind_ns_dis_train, interation_ind_ns_dis_test= triple_interaction_term('INDUS', 'NOX', 'DIS','INDUS_NOS_DIS')
现在您拥有所有需要的列,可以将它们添加到 train 和 test 数据集中。您将这两个新数据框命名为
- df_train_new
- df_test_new
df_train_new = pd.concat([df_train_scale,
interation_ind_ns_train,
interation_ind_ns_dis_train],
axis=1, join='inner')
df_test_new = pd.concat([df_test_scale,
interation_ind_ns_test,
interation_ind_ns_dis_test],
axis=1, join='inner')
df_train_new.head(5)
输出

就是这样,您可以估算带有交互项的新模型,并查看性能指标。
CONTI_FEATURES_NEW = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT',
'INDUS_NOS', 'INDUS_NOS_DIS']
### Define categorical list
continuous_features_new = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES_NEW]
model = tf.estimator.LinearRegressor(
model_dir="train_Boston_1",
feature_columns= categorical_features + continuous_features_new)
输出
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'train_Boston_1', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a1a5d5860>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
代码
FEATURES = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT','INDUS_NOS', 'INDUS_NOS_DIS','CHAS']
LABEL= 'PRICE'
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
model.train(input_fn=get_input_fn(df_train_new,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
输出
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train_Boston_1/model.ckpt. INFO:tensorflow:loss = 56417.703, step = 1 INFO:tensorflow:global_step/sec: 124.844 INFO:tensorflow:loss = 65522.3, step = 101 (0.803 sec) INFO:tensorflow:global_step/sec: 182.704 INFO:tensorflow:loss = 15384.148, step = 201 (0.549 sec) INFO:tensorflow:global_step/sec: 208.189 INFO:tensorflow:loss = 22020.305, step = 301 (0.482 sec) INFO:tensorflow:global_step/sec: 213.855 INFO:tensorflow:loss = 28208.812, step = 401 (0.468 sec) INFO:tensorflow:global_step/sec: 209.758 INFO:tensorflow:loss = 7606.877, step = 501 (0.473 sec) INFO:tensorflow:global_step/sec: 196.618 INFO:tensorflow:loss = 26679.76, step = 601 (0.514 sec) INFO:tensorflow:global_step/sec: 196.472 INFO:tensorflow:loss = 11377.163, step = 701 (0.504 sec) INFO:tensorflow:global_step/sec: 172.82 INFO:tensorflow:loss = 8592.07, step = 801 (0.578 sec) INFO:tensorflow:global_step/sec: 168.916 INFO:tensorflow:loss = 19878.56, step = 901 (0.592 sec) INFO:tensorflow:Saving checkpoints for 1000 into train_Boston_1/model.ckpt. INFO:tensorflow:Loss for final step: 19598.387. <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x1a1a5d5e10>
model.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
输出
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-05-29-02:41:14
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train_Boston_1/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-05-29-02:41:14
INFO:tensorflow:Saving dict for global step 1000: average_loss = 79.78876, global_step = 1000, loss = 1515.9863
{'average_loss': 79.78876, 'global_step': 1000, 'loss': 1515.9863}
新损失为 1515。仅通过添加两个新变量,您就能够降低损失。这意味着您可以比基准模型做出更好的预测。