TensorFlow 中的 CNN 图像分类(附步骤和示例)
什么是卷积神经网络?
卷积神经网络,也称为 convnets 或 CNN,是计算机视觉应用中一种众所周知的方法。它是一类用于分析视觉图像的深度神经网络。这种架构在识别图片或视频中的物体方面占主导地位。它用于图像或视频识别、神经语言处理等应用。
卷积神经网络的架构
想想几年前的 Facebook,您将一张照片上传到您的个人资料后,系统会要求您手动为照片中的人脸添加姓名。如今,Facebook 使用 convnet 自动标记您朋友的照片。
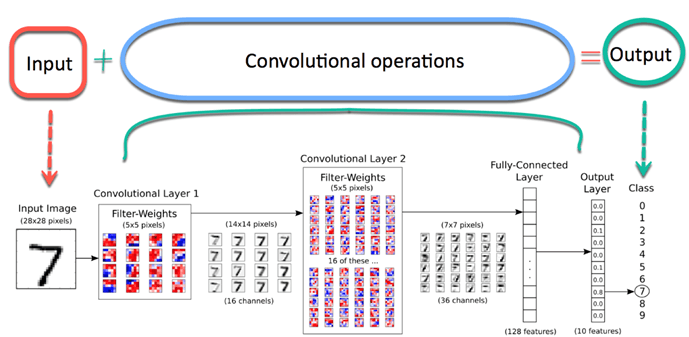
用于图像分类的卷积神经网络并不难理解。输入图像在卷积阶段进行处理,然后分配一个标签。
典型的 convnet 架构可以总结在下图所示。首先,图像被推送到网络;这被称为输入图像。然后,输入图像会经历无数个步骤;这是网络的一部分卷积。最后,神经网络可以预测图像中的数字。
图像由具有高度和宽度的像素数组组成。灰度图像只有一个通道,而彩色图像有三个通道(一个用于红色,一个用于绿色,一个用于蓝色)。通道堆叠在一起。在本教程中,您将使用只有单个通道的灰度图像。每个像素的值从 0 到 255,以反映颜色的强度。例如,值为 0 的像素显示白色,而值接近 255 的像素颜色会更深。
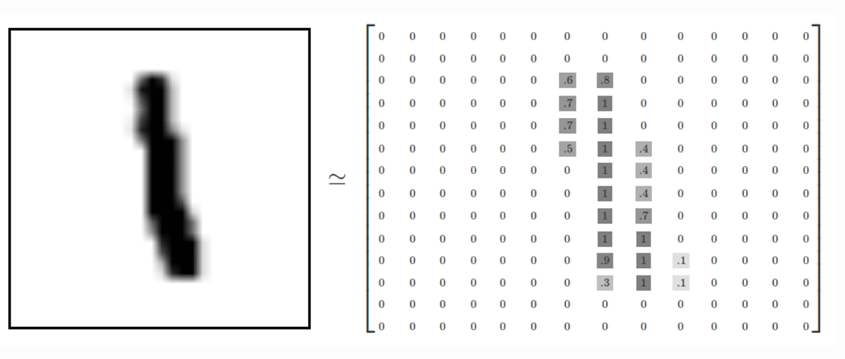
让我们看一下存储在 MNIST 数据集 中的图像。下图显示了如何以矩阵格式表示左侧的图像。请注意,原始矩阵已标准化为 0 到 1 之间。对于较深的颜色,矩阵中的值约为 0.9,而白色像素的值为 0。
卷积运算
模型中最关键的组成部分是卷积层。这部分旨在减小图像尺寸,从而加快权重计算速度并提高其泛化能力。
在卷积部分,网络保留了图像的关键特征,并排除了无关的噪声。例如,模型正在学习如何从背景中有山的图片中识别大象。如果您使用传统的神经网络,模型将为所有像素分配权重,包括那些来自山的像素,而这些像素并不重要,并且可能会误导网络。
相反,Keras 卷积神经网络将使用一种数学技术来提取最相关的像素。这种数学运算称为卷积。这种技术允许网络在每一层学习越来越复杂的特征。卷积将矩阵分成小块,以便学习每个块中最基本的元素。
卷积神经网络(ConvNet 或 CNN)的组成部分
Convnet 有四个组成部分
- 卷积
- 非线性(ReLU)
- 池化或子采样
- 分类(全连接层)
卷积
卷积的目的是局部提取图像中对象的特征。这意味着网络将学习图片中的特定模式,并能在图片中的任何地方识别它。
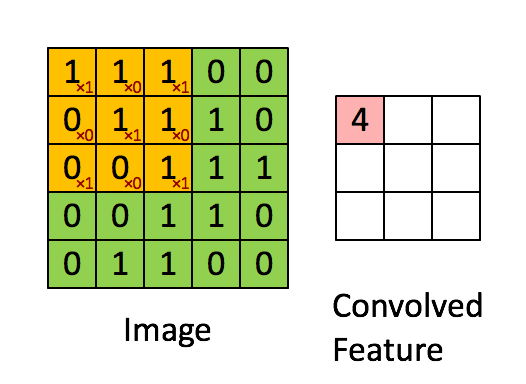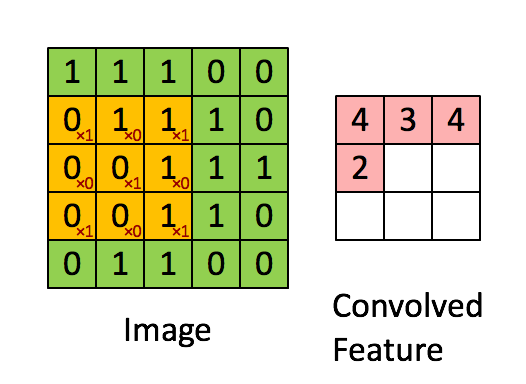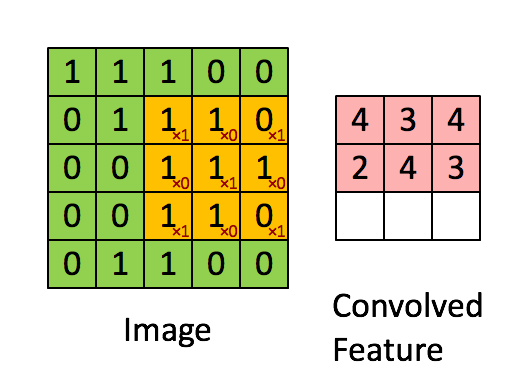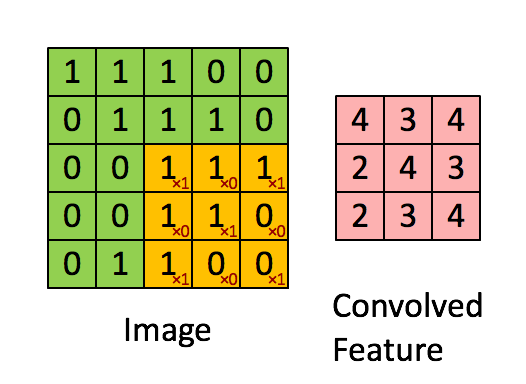
卷积是逐元素乘法。这个概念很容易理解。计算机将扫描图像的一部分,通常是 3x3 的尺寸,并将其乘以一个滤波器。逐元素乘法的结果称为特征图。此步骤一直重复,直到扫描完所有图像。请注意,卷积后,图像的尺寸会减小。
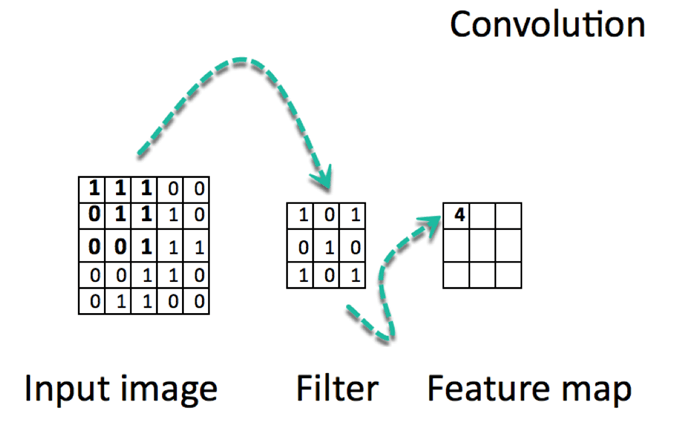
下面有一个 URL 可以实际查看卷积的工作原理。
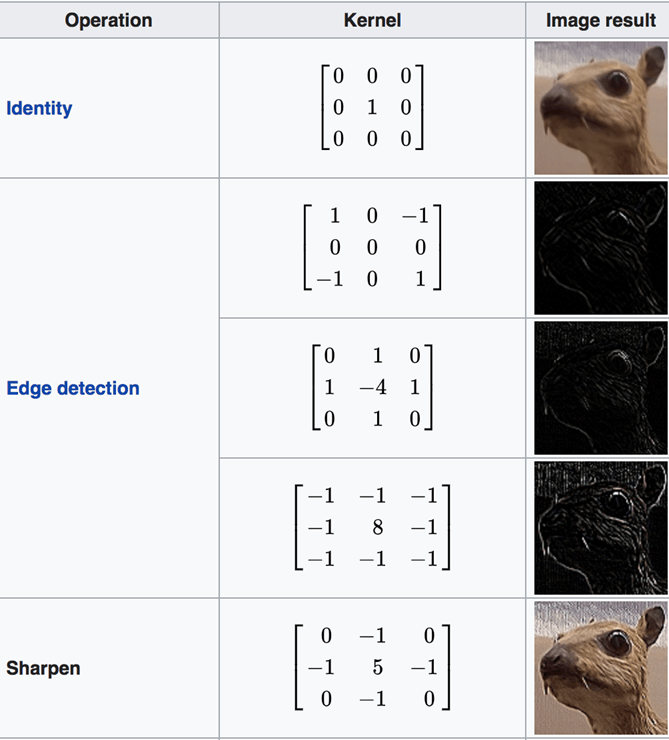
有许多可用的通道。下面列出了一些通道。您可以看到每个滤波器都有特定的用途。请注意,下图中的“核”是“滤波器”的同义词。
卷积背后的算术
卷积阶段会将滤波器应用于图像中的一小块像素。滤波器会沿着输入图像移动,通常形状为 3x3 或 5x5。这意味着网络会将这些窗口滑过所有输入图像并计算卷积。下图显示了卷积是如何操作的。块的大小为 3x3,输出矩阵是图像矩阵和滤波器之间逐元素运算的结果。
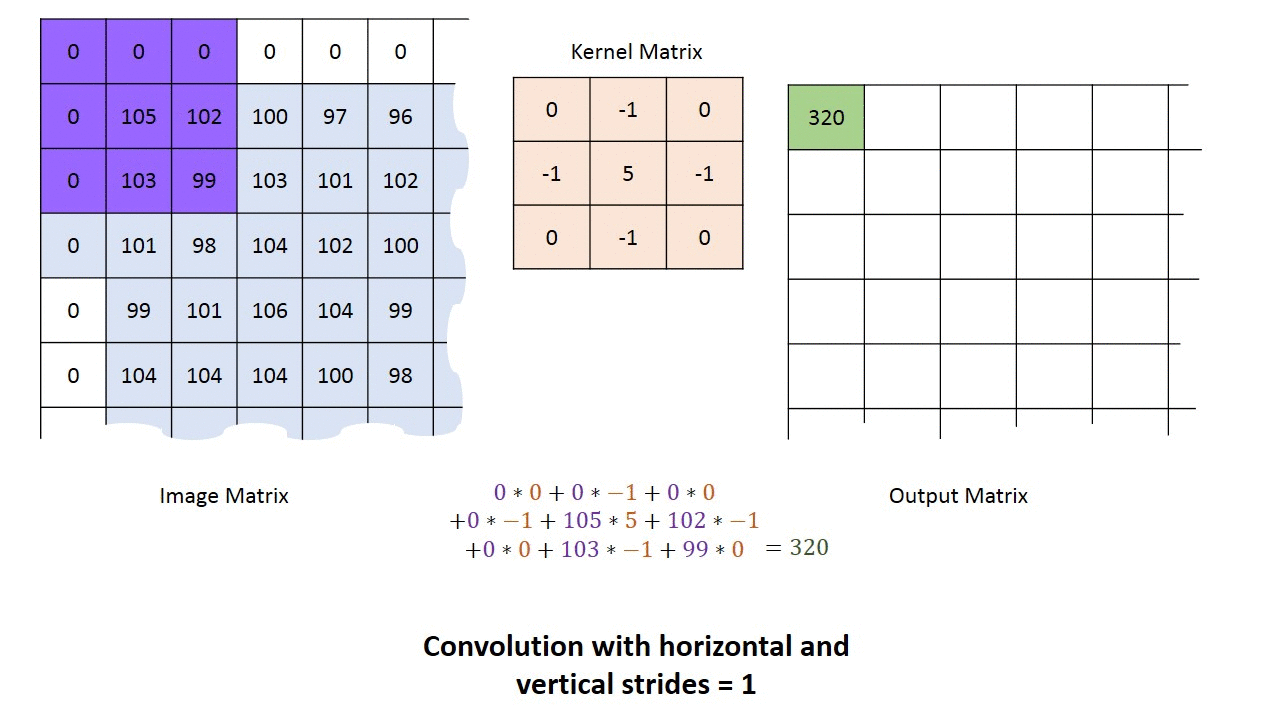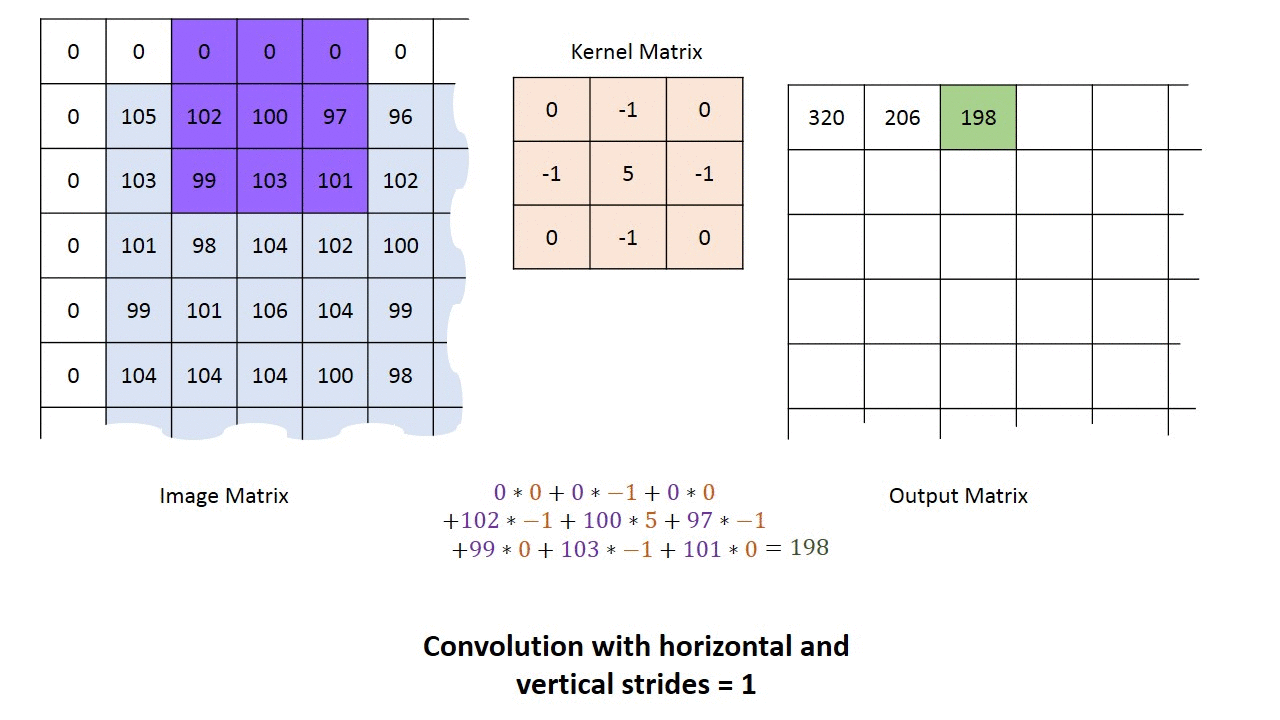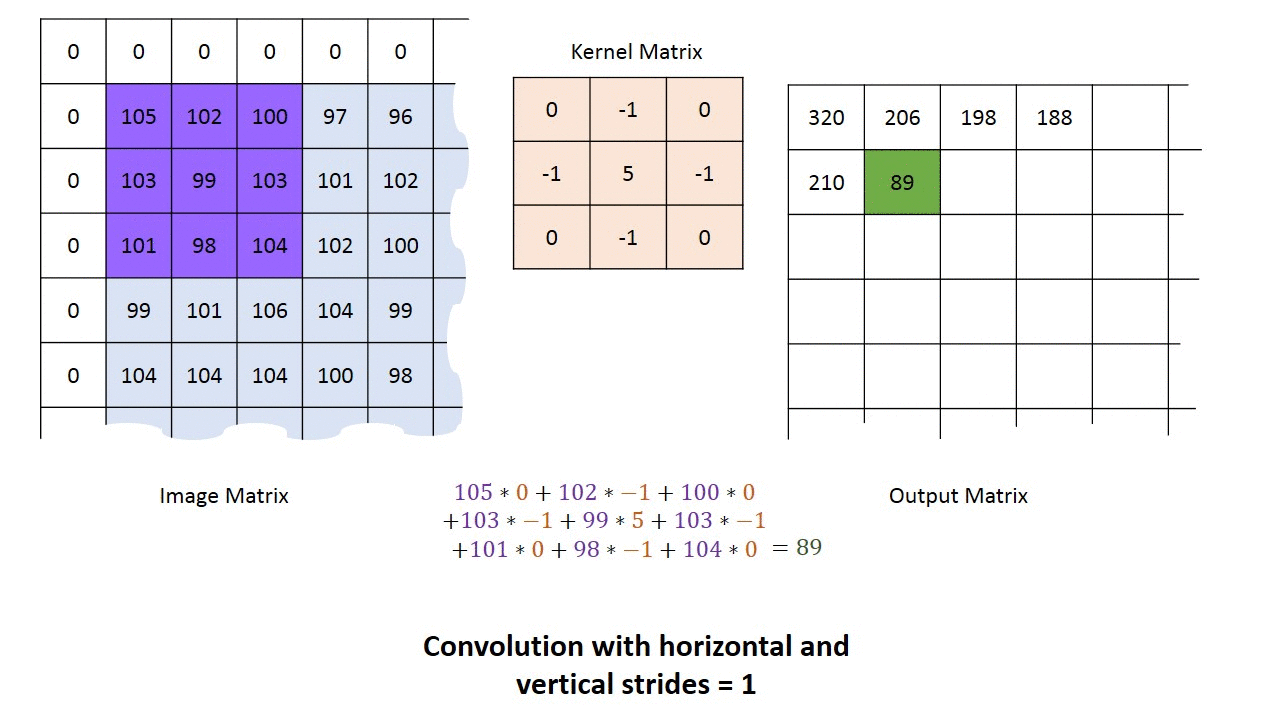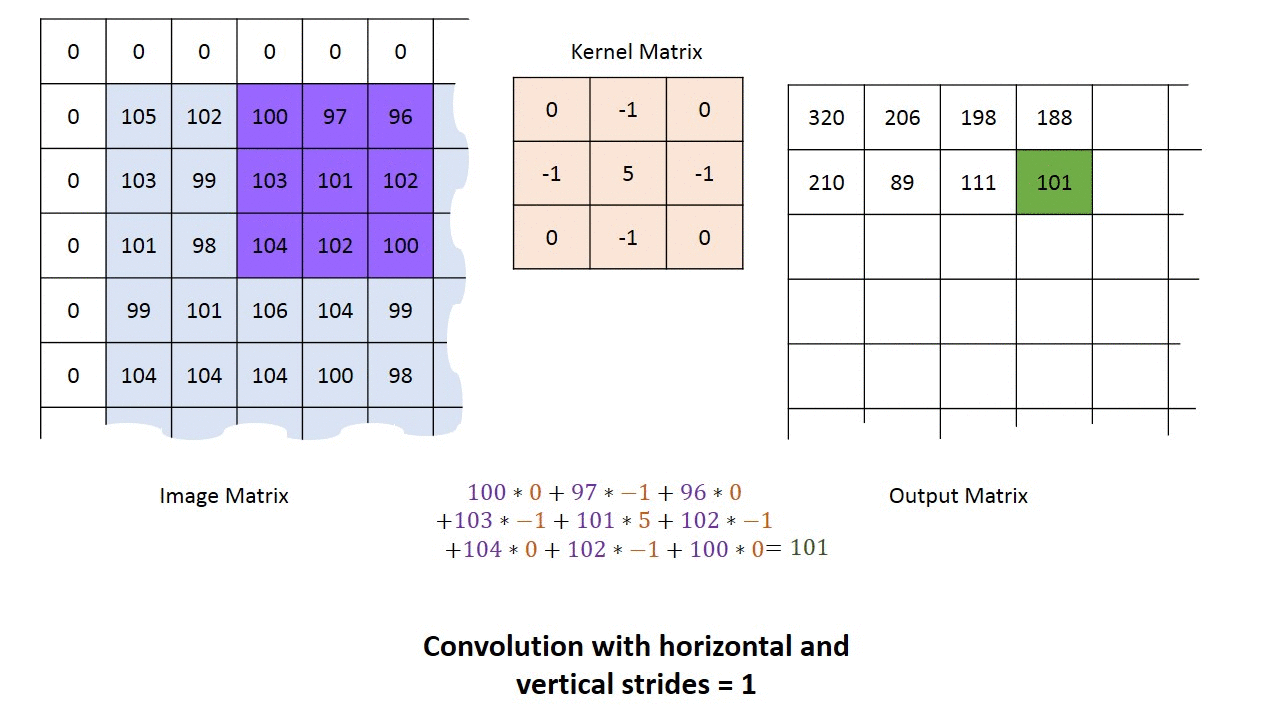
您会注意到输出的宽度和高度可能与输入的宽度和高度不同。这是由于边框效应。
边框效应
图像具有 5x5 的特征图和 3x3 的滤波器。中心只有一个窗口,滤波器可以从中筛选 3x3 的网格。输出特征图将沿 3x3 的维度缩小两个瓦片。
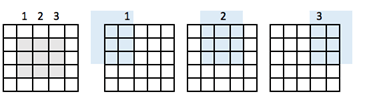
要获得与输入维度相同的输出维度,需要添加填充。填充包括在矩阵的每一侧添加适当数量的行和列。这将允许卷积中心匹配每个输入块。下图中的输入/输出矩阵具有相同的 5x5 维度。
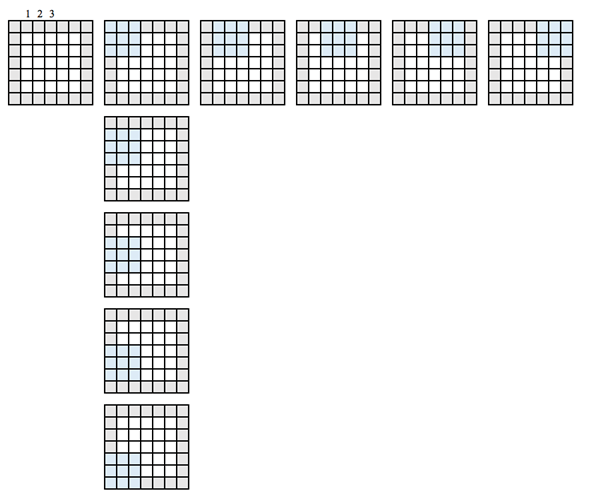
定义网络时,卷积特征由三个参数控制
- 深度:它定义了在卷积过程中应用的滤波器数量。在前面的示例中,您看到了一个深度为 1,意味着只使用了一个滤波器。在大多数情况下,有多个滤波器。下图显示了有三个滤波器的情况下的操作。

- 步幅:它定义了两次切片之间的“像素跳数”。如果步幅等于 1,窗口将以一个像素的间隔移动。如果步幅等于 2,窗口将跳过 2 个像素。如果增加步幅,您将获得更小的特征图。
步幅 1 示例

步幅 2

- 零填充:填充是将相应数量的行和列添加到输入特征图的每一侧的操作。在这种情况下,输出具有与输入相同的维度。
非线性(ReLU)
卷积运算结束后,输出会经过激活函数以实现非线性。convnet 的常用激活函数是 Relu。所有负值像素将被零替换。
池化运算
这个步骤很容易理解。池化的目的是减小输入图像的维度。执行这些步骤是为了降低运算的计算复杂度。通过减小维度,网络需要计算的权重更少,因此可以防止过拟合。
在此阶段,您需要定义大小和步幅。池化输入图像的标准方法是使用特征图的最大值。看下图。 “池化”将扫描 4x4 特征图的四个子矩阵并返回最大值。池化取 2x2 矩阵的最大值,然后将此窗口移动两个像素。例如,第一个子矩阵是 [3,1,3,2],池化将返回最大值 3。
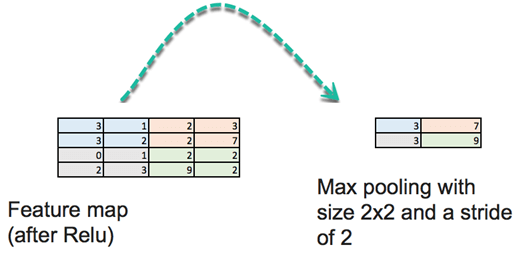
还有其他池化运算,例如均值。
此操作会大大减小特征图的大小。
全连接层
最后一步是构建一个传统的 人工神经网络,就像您在之前的教程中所做的那样。您将前一层的所有神经元连接到下一层。您使用 softmax 激活函数对输入图像上的数字进行分类。
回顾
TensorFlow 卷积神经网络在进行预测之前会编译不同的层。神经网络具有
- 卷积层
- Relu 激活函数
- 池化层
- 全连接层
卷积层对图像的子区域应用不同的滤波器。Relu 激活函数增加非线性,池化层减小特征图的维度。
所有这些层都从图像中提取关键信息。最后,特征图被输入到带有 softmax 函数的初级全连接层以进行预测。
使用 TensorFlow 训练 CNN
现在您熟悉了 convnets 的构建模块,您就可以使用 TensorFlow 构建一个了。我们将使用 MNIST 数据集进行 CNN 图像分类。
数据准备与之前的教程相同。您可以运行代码,直接跳到 CNN 的架构。
您将按照以下步骤使用 CNN 进行图像分类
步骤 1:上传数据集
步骤 2:输入层
步骤 3:卷积层
步骤 4:池化层
步骤 5:第二个卷积层和池化层
步骤 6:全连接层
步骤 7:Logit 层
步骤 1:上传数据集
MNIST 数据集可在 scikit learn 中找到,网址为 此 URL。请下载并将其存储在 Downloads 文件夹中。您可以使用 fetch_mldata('MNIST original')上传它。
创建训练/测试集
您需要使用 train_test_split 来拆分数据集。
缩放特征
最后,您可以使用 MinMaxScaler 缩放特征,如下面 TensorFlow CNN 示例中的图像分类所示。
import numpy as np
import tensorflow as tf
from sklearn.datasets import fetch_mldata
#Change USERNAME by the username of your machine
## Windows USER
mnist = fetch_mldata('C:\\Users\\USERNAME\\Downloads\\MNIST original')
## Mac User
mnist = fetch_mldata('/Users/USERNAME/Downloads/MNIST original')
print(mnist.data.shape)
print(mnist.target.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42)
y_train = y_train.astype(int)
y_test = y_test.astype(int)
batch_size =len(X_train)
print(X_train.shape, y_train.shape,y_test.shape )
## resclae
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# Train
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# test
X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
feature_columns = [tf.feature_column.numeric_column('x', shape=X_train_scaled.shape[1:])]
X_train_scaled.shape[1:]
定义 CNN
CNN 使用滤波器处理图像的原始像素以学习详细模式,而不是像传统神经网络那样处理全局模式。要构建 CNN,您需要定义
- 卷积层:对特征图应用 n 个滤波器。卷积后,需要使用 Relu 激活函数为网络增加非线性。
- 池化层:卷积后的下一步是对特征图进行下采样。目的是减小特征图的维度,以防止过拟合并提高计算速度。最大池化是常用的技术,它将特征图分成子区域(通常为 2x2 大小)并只保留最大值。
- 全连接层:前一层的所有神经元都连接到下一层。CNN 将根据卷积层提取的特征进行分类,并通过池化层进行降维。
CNN 架构
- 卷积层:应用 14 个 5x5 滤波器(提取 5x5 像素子区域),并带有 ReLU 激活函数。
- 池化层:执行最大池化,使用 2x2 滤波器和步幅 2(指定池化区域不重叠)。
- 卷积层:应用 36 个 5x5 滤波器,并带有 ReLU 激活函数。
- 池化层 #2:再次执行最大池化,使用 2x2 滤波器和步幅 2。
- 1,764 个神经元,带有 0.4 的 dropout 正则化率(任何给定元素在训练期间被丢弃的概率为 0.4)。
- 全连接层(Logit 层):10 个神经元,对应于每个数字目标类别(0-9)。
有三个重要模块可用于创建 CNN:
- conv2d():构建一个二维卷积层,参数包括滤波器数量、滤波器核大小、填充和激活函数。
- max_pooling2d():使用最大池化算法构建一个二维池化层。
- dense():构建一个带有隐藏层和单元的全连接层。
您将定义一个函数来构建 CNN。在将所有内容包装到函数中之前,我们详细了解一下如何构建每个构建块。
步骤 2:输入层
def cnn_model_fn(features, labels, mode):
input_layer = tf.reshape(tensor = features["x"],shape =[-1, 28, 28, 1])
您需要定义一个具有数据形状的张量。为此,您可以使用 tf.reshape 模块。在此模块中,您需要声明要重塑的张量和张量的形状。第一个参数是数据的特征,它在函数参数中定义。
一张图片具有高度、宽度和通道。MNIST 数据集是单色图片,尺寸为 28x28。我们将形状参数中的批处理大小设置为 -1,以便它采用特征 ["x"] 的形状。这样做的优点是将批处理大小设置为可调超参数。如果批处理大小设置为 7,则张量将提供 5,488 个值(28*28*7)。
步骤 3:卷积层
# first Convolutional Layer
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=14,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
第一个卷积层有 14 个滤波器,核大小为 5x5,填充方式相同。相同的填充意味着输出张量和输入张量应具有相同的高度和宽度。Tensorflow 将添加零行和列以确保尺寸相同。
您使用 Relu 激活函数。输出尺寸将为 [28, 28, 14]。
步骤 4:池化层
卷积后的下一步是池化计算。池化计算将减小数据的维度。您可以使用 max_pooling2d 模块,大小为 2x2,步幅为 2。您以前一层作为输入。输出尺寸将为 [batch_size, 14, 14, 14]。
# first Pooling Layer pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
步骤 5:第二个卷积层和池化层
第二个卷积层有 32 个滤波器,输出尺寸为 [batch_size, 14, 14, 32]。池化层的尺寸与之前相同,输出形状为 [batch_size, 14, 14, 18]。
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=36,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
步骤 6:全连接层
然后,您需要定义全连接层。必须先将特征图展平,然后才能连接到全连接层。您可以使用 reshape 模块,大小为 7*7*36。
全连接层将连接 1764 个神经元。您添加了一个 Relu 激活函数。此外,您添加了一个 dropout 正则化项,比率为 0.3,这意味着 30% 的权重将被设置为 0。请注意,dropout 仅在训练阶段发生。cnn_model_fn 函数有一个 mode 参数,用于声明模型是需要训练还是评估,如下面的 CNN 图像分类 TensorFlow 示例所示。
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 36])
dense = tf.layers.dense(inputs=pool2_flat, units=7 * 7 * 36, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.3, training=mode == tf.estimator.ModeKeys.TRAIN)
步骤 7:Logit 层
最后,在 TensorFlow 图像分类示例中,您可以使用模型的预测来定义最后一层。输出形状等于批处理大小和 10(总图像数)。
# Logits Layer logits = tf.layers.dense(inputs=dropout, units=10)
您可以创建一个包含类别和每个类别的概率的字典。tf.argmax() 模块返回 logit 层中的最高值。softmax 函数返回每个类别的概率。
predictions = {
# Generate predictions
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor") }
当 mode 设置为 prediction 时,您只想返回字典预测。您添加了这些代码来显示预测。
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
下一步是计算模型的损失。在上一教程中,您了解到多类别模型的损失函数是交叉熵。损失可以通过以下代码轻松计算。
# Calculate Loss (for both TRAIN and EVAL modes) loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
TensorFlow CNN 示例的最后一步是优化模型,即找到最佳权重值。为此,您可以使用学习率为 0.001 的梯度下降优化器。目标是最小化损失。
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
您已完成 CNN。但是,您希望在评估模式下显示性能指标。多类别模型的性能指标是准确率。Tensorflow 配备了一个 accuracy 模块,带有两个参数:标签和预测值。
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
就这样。您创建了第一个 CNN,并且可以将其包装到一个函数中,以便使用它来训练和评估模型。
def cnn_model_fn(features, labels, mode):
"""Model function for CNN."""
# Input Layer
input_layer = tf.reshape(features["x"], [-1, 28, 28, 1])
# Convolutional Layer
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Convolutional Layer #2 and Pooling Layer
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=36,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Dense Layer
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 36])
dense = tf.layers.dense(inputs=pool2_flat, units=7 * 7 * 36, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)
# Logits Layer
logits = tf.layers.dense(inputs=dropout, units=10)
predictions = {
# Generate predictions (for PREDICT and EVAL mode)
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
# Calculate Loss
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# Configure the Training Op (for TRAIN mode)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
# Add evaluation metrics Evaluation mode
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
以下步骤与之前的教程相同。
首先,您定义一个具有用于图像分类的 CNN 模型的估计器。
# Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn, model_dir="train/mnist_convnet_model")
CNN 需要很长时间才能训练,因此,您创建一个 Logging hook,每 50 次迭代存储 softmax 层的值。
# Set up logging for predictions
tensors_to_log = {"probabilities": "softmax_tensor"}
logging_hook = tf.train.LoggingTensorHook(tensors=tensors_to_log, every_n_iter=50)
您可以估计模型了。您设置批处理大小为 100 并对数据进行 shuffle。请注意,我们将训练步数设置为 16,000,这可能需要很长时间才能训练。请耐心等待。
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": X_train_scaled},
y=y_train,
batch_size=100,
num_epochs=None,
shuffle=True)
mnist_classifier.train(
input_fn=train_input_fn,
steps=16000,
hooks=[logging_hook])
模型训练完成后,您可以对其进行评估并打印结果。
# Evaluate the model and print results
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": X_test_scaled},
y=y_test,
num_epochs=1,
shuffle=False)
eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)
print(eval_results)
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-08-05-12:52:41
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train/mnist_convnet_model/model.ckpt-15652
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-08-05-12:52:56
INFO:tensorflow:Saving dict for global step 15652: accuracy = 0.9589286, global_step = 15652, loss = 0.13894269
{'accuracy': 0.9689286, 'loss': 0.13894269, 'global_step': 15652}
使用当前的架构,您获得的准确率为 97%。您可以更改架构、批处理大小和迭代次数来提高准确率。CNN 神经网络的表现远优于 ANN 或逻辑回归。在人工神经网络的教程中,您的准确率为 96%,低于 CNN。CNN 的性能令人印象深刻,具有更大的图像集,无论是计算速度还是准确率方面。
摘要
卷积神经网络在评估图片方面效果非常好。这种架构在识别图片或视频中的物体方面占主导地位。
要构建 TensorFlow CNN,您需要遵循七个步骤。
第 1 步:上传数据集
MNIST 数据集可在 scikit learn 中找到。请下载并将其存储在 Downloads 文件夹中。您可以使用 fetch_mldata('MNIST original')上传它。
第 2 步:输入层
此步骤会重塑数据。形状等于像素数量的平方根。例如,如果一张图片有 156 个像素,则形状为 26x26。您需要指定图片是否有颜色。如果有,则将 3 添加到形状中 - 3 用于 RGB - 否则为 1。
input_layer = tf.reshape(tensor = features["x"],shape =[-1, 28, 28, 1])
第 3 步:卷积层
接下来,您需要创建卷积层。您应用不同的滤波器来让网络学习重要的特征。您指定核的大小和滤波器的数量。
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=14,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
第 4 步:池化层
在第三步中,您添加一个池化层。此层减小输入的大小。它通过取子矩阵的最大值来做到这一点。例如,如果子矩阵是 [3,1,3,2],则池化将返回最大值 3。
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
第 5 步:添加卷积层和池化层
在此步骤中,您可以根据需要添加任意数量的卷积层和池化层。Google 使用具有 20 多个卷积层的架构。
第 6 步:全连接层
第 6 步将前面的层展平以创建全连接层。在此步骤中,您可以使用不同的激活函数并添加 dropout 效果。
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 36])
dense = tf.layers.dense(inputs=pool2_flat, units=7 * 7 * 36, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.3, training=mode == tf.estimator.ModeKeys.TRAIN)
第 7 步:Logit 层
最后一步是预测。
logits = tf.layers.dense(inputs=dropout, units=10)