人工神经网络教程与 TensorFlow ANN 示例
什么是人工神经网络?
人工神经网络 (ANN) 是受生物神经网络启发的计算机系统,用于基于称为人工神经元的连接单元集合来创建人工智能大脑。它旨在像人类一样分析和处理信息。人工神经网络具有自学习能力,可以提供更好的结果,因为可用的数据越多。
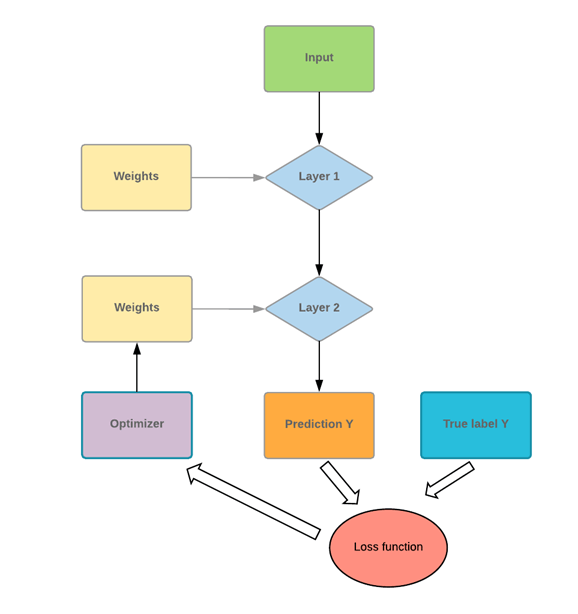
人工神经网络 (ANN) 由四个主要对象组成
- 层:所有学习都发生在层中。有3层:1)输入层 2)隐藏层和 3)输出层
- 特征和标签:网络的输入数据(特征)和网络输出(标签)
- 损失函数:用于估计学习阶段性能的指标
- 优化器:通过更新网络中的知识来改进学习
神经网络将输入数据传递给一系列层。网络需要使用损失函数来评估其性能。损失函数为网络提供了它需要遵循的路径,然后才能掌握知识。网络需要借助优化器来改进其知识。
如果您查看上图,您将理解底层机制。
程序接收一些输入值并将其推入两个全连接层。想象一下你有一个数学问题,你做的第一件事就是阅读相应的章节来解决问题。你应用新知识来解决问题。你很有可能不会得到很好的分数。这对于网络来说也是一样的。第一次看到数据并做出预测时,它不会与实际数据完全匹配。
为了提高其知识,网络使用优化器。在我们的类比中,优化器可以被认为是重读章节。通过再次阅读,您获得了新的见解/课程。同样,网络使用优化器,更新其知识,并测试其新知识以检查它还需要学习多少。程序将重复此步骤,直到它产生尽可能低的错误。
在我们的数学问题类比中,这意味着您一遍又一遍地阅读教科书的章节,直到您彻底理解课程内容。即使阅读多次后,如果您仍然出错,也意味着您已经达到了当前材料的知识容量。您需要使用不同的教科书或测试不同的方法来提高您的分数。对于神经网络也是如此。如果错误率远未达到 100%,但曲线是平的,则意味着在当前架构下,它无法再学习任何东西。网络需要得到更好的优化才能提高知识。
神经网络架构
人工神经网络架构包含以下组件
- 层
- 激活函数
- 损失函数
- 优化器
层
层是所有学习发生的地方。层内有无限数量的权重(神经元)。典型的神经网络通常通过密集连接层(也称为全连接层)进行处理。这意味着所有输入都连接到输出。
典型的神经网络接收输入向量和一个包含标签的标量。最方便的设置是二元分类,只有两个类别:0 和 1。
网络接收输入,将其发送到所有连接的节点,并通过激活函数计算信号。
上图描绘了这个想法。第一层是输入值,第二层(称为隐藏层)接收来自前一层的加权输入。
- 第一个节点是输入值
- 神经元分解为输入部分和激活函数。左侧接收来自前一层的所有输入。右侧是将输入之和传递到激活函数。
- 由隐藏层计算并用于进行预测的输出值。对于分类,它等于类别的数量。对于回归,只预测一个值。
激活函数
节点的激活函数定义了给定一组输入时的输出。您需要一个激活函数来允许网络学习非线性模式。常见的激活函数是Relu,整流线性单元。该函数为所有负值返回零。
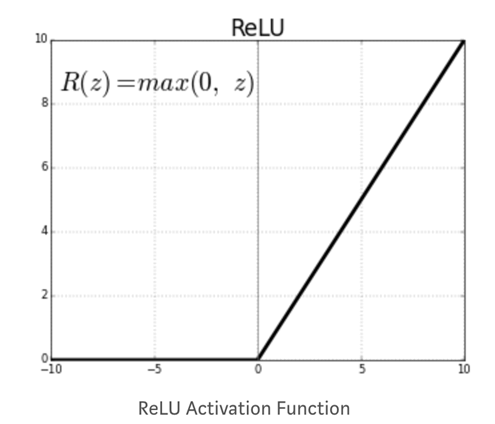
其他激活函数是
- 分段线性
- Sigmoid
- Tanh
- Leaky Relu
构建神经网络时需要做出的关键决定是
- 神经网络中有多少层
- 每层有多少隐藏单元
具有许多层和隐藏单元的神经网络可以学习数据的复杂表示,但这会使网络的计算成本非常高。
损失函数
定义了隐藏层和激活函数后,您需要指定损失函数和优化器。
对于二元分类,通常使用二元交叉熵损失函数。在线性回归中,您使用均方误差。
损失函数是评估优化器性能的重要指标。在训练过程中,此指标将被最小化。您需要根据您正在处理的问题类型仔细选择此数量。
优化器
损失函数是模型性能的度量。优化器将帮助改进网络的权重以降低损失。有不同的优化器可用,但最常见的是随机梯度下降。
传统的优化器有
- 动量优化,
- Nesterov 加速梯度,
- AdaGrad,
- Adam 优化
神经网络的局限性
以下是神经网络的局限性
过拟合
复杂神经网络的一个常见问题是难以泛化到未见数据。具有许多权重的神经网络可以很好地识别训练集中的特定细节,但通常会导致过拟合。如果组内数据不平衡(即某些组可用的数据不足),网络将在训练期间学习得很好,但将无法将此类模式泛化到从未见过的数据。
机器学习中优化和泛化之间存在权衡。
优化模型需要找到最小化训练集损失的最佳参数。
然而,泛化告诉我们模型在未见过的数据上的表现。
为防止模型捕捉训练数据的特定细节或不需要的模式,您可以使用不同的技术。最好的方法是拥有一个平衡且数据量充足的数据集。减少过拟合的艺术称为正则化。让我们回顾一些传统技术。
网络大小
具有过多层和隐藏单元的神经网络被认为是高度复杂的。减少模型复杂性的一种直接方法是减小其大小。没有最佳方法来定义层数。您需要从少量层开始,并增加其大小,直到找到过拟合的模型。
权重正则化
防止过拟合的标准技术是为网络的权重添加约束。约束强制网络的权重只取较小的值。将约束添加到误差的损失函数中。有两种正则化
L1:Lasso:成本与权重系数的绝对值成正比
L2:Ridge:成本与权重系数的值的平方成正比
Dropout
Dropout 是一种奇特但有用的技术。具有 Dropout 的网络意味着一些权重将被随机设置为零。想象一下您有一个权重数组 [0.1, 1.7, 0.7, -0.9]。如果神经网络有 Dropout,它将变为 [0.1, 0, 0, -0.9],其中 0 是随机分布的。控制 Dropout 的参数是 Dropout 率。该速率定义了要设置为零的权重数量。通常费率在 0.2 到 0.5 之间。
TensorFlow 中的神经网络示例
让我们来看一个实际的人工神经网络示例,看看神经网络如何处理典型的分类问题。有两个输入,x1 和 x2,具有随机值。输出是二进制类别。目标是根据两个特征对标签进行分类。要执行此任务,神经网络架构定义如下:
- 两个隐藏层
- 第一层有四个全连接神经元
- 第二层有两个全连接神经元
- 激活函数是 Relu
- 添加 L2 正则化,学习率为 0.003
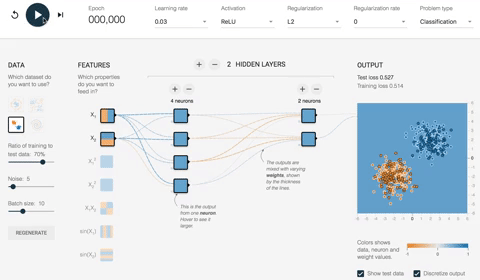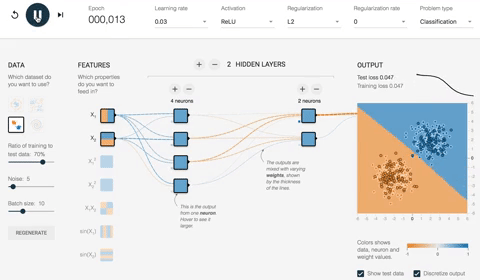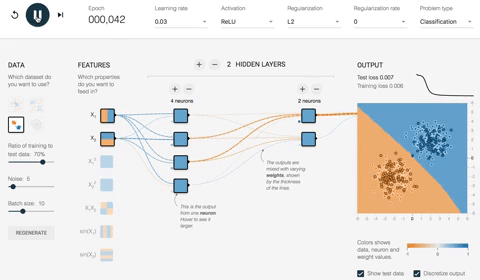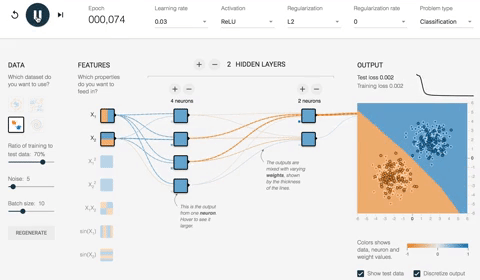
网络将在 180 个 epoch 中以 10 的批次大小优化权重。在下面的 ANN 示例视频中,您可以查看权重如何随着时间演变以及网络如何改进分类映射。
首先,网络为所有权重分配随机值。
- 使用随机权重(即,未经优化)时,输出损失为 0.453。下图用不同的颜色表示网络。
- 通常,橙色表示负值,而蓝色表示正值。
- 数据点的表示相同;蓝色的表示正标签,橙色的表示负标签。
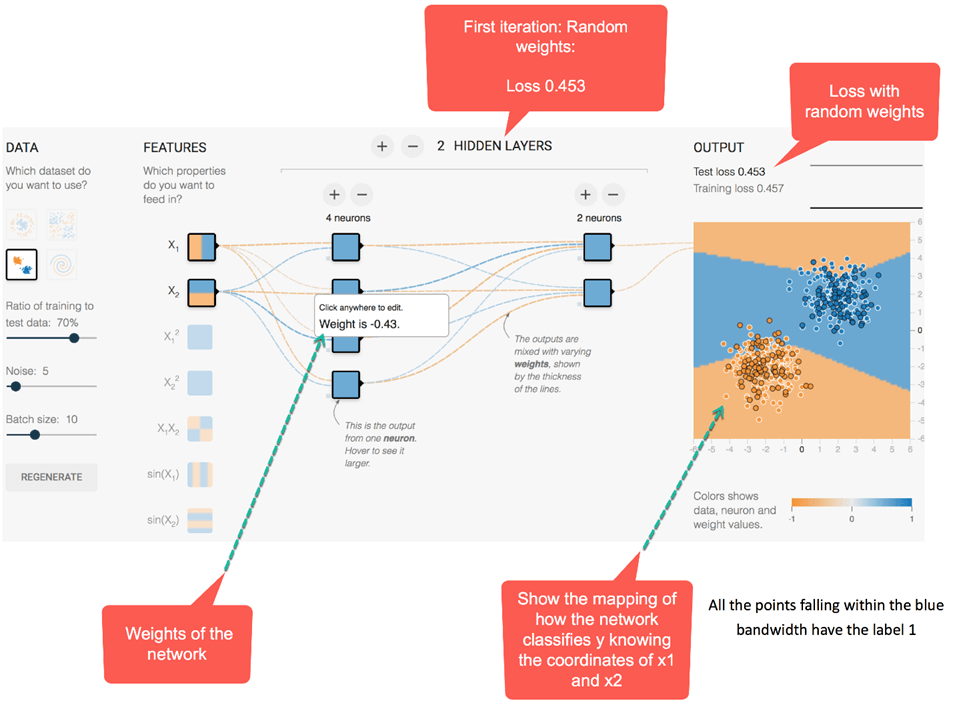
在第二个隐藏层内部,线条的颜色根据权重的符号着色。橙色线条表示负权重,蓝色线条表示正权重。
正如您所看到的,在输出映射中,网络犯了很多错误。让我们看看优化后的网络行为。
下面的 ANN 示例图片描绘了优化网络的結果。首先,您会注意到网络已成功学会如何对数据点进行分类。您可以看到,在之前的图片中,初始权重为 -0.43,而优化后权重为 -0.95。
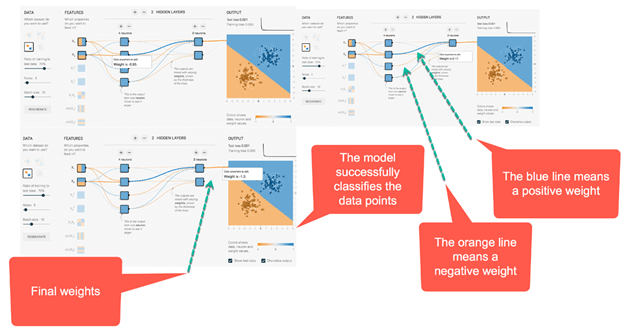
这个想法可以推广到具有更多隐藏层和神经元的网络。您可以在 链接 中进行尝试。
如何使用 TensorFlow 训练神经网络
以下是使用 TensorFlow ANN 和 API 的 estimator DNNClassifier 训练神经网络的分步过程。
我们将使用 MNIST 数据集来训练您的第一个神经网络。使用 TensorFlow 训练神经网络并不复杂。预处理步骤与之前的教程完全相同。您将按以下步骤进行
- 步骤1: 导入数据
- 步骤 2:转换数据
- 步骤 3:构造张量
- 步骤 4:构建模型
- 步骤 5:训练和评估模型
- 步骤 6:改进模型
步骤 1) 导入数据
首先,您需要导入必要的库。您可以使用 scikit learn 导入 MNIST 数据集,如下面的 TensorFlow 神经网络示例所示。
MNIST 数据集是常用于测试新技术或算法的数据集。该数据集包含 28x28 像素的图像,其中包含从 0 到 9 的手写数字。目前,在测试集上最低的错误率为 0.27%,由一个由 7 个卷积神经网络组成的委员会实现。
import numpy as np import tensorflow as tf np.random.seed(1337)
您可以暂时在此地址下载 scikit learn。将数据集复制并粘贴到方便的文件夹中。要将数据导入 python,您可以使用 scikit learn 的 fetch_mldata。将文件路径粘贴到 fetch_mldata 中以获取数据。
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata(' /Users/Thomas/Dropbox/Learning/Upwork/tuto_TF/data/mldata/MNIST original')
print(mnist.data.shape)
print(mnist.target.shape)
之后,您导入数据并获取两个数据集的形状。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42) y_train = y_train.astype(int) y_test = y_test.astype(int) batch_size =len(X_train) print(X_train.shape, y_train.shape,y_test.shape )
步骤 2)转换数据
在之前的教程中,您了解到需要转换数据以限制异常值的影响。在本神经网络教程中,您将使用 min-max 缩放器转换数据。公式是
(X-min_x)/(max_x - min_x)
Scikit learns 已为此提供了一个函数:MinMaxScaler()
## resclae from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # Train X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) # test X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
步骤 3)构造张量
您现在已经熟悉了在 Tensorflow 中创建张量的方法。您可以将训练集转换为数字列。
feature_columns = [tf.feature_column.numeric_column('x', shape=X_train_scaled.shape[1:])]
步骤 4)构建模型
神经网络的架构包含 2 个隐藏层,第一个层有 300 个单元,第二个层有 100 个单元。我们根据自己的经验使用这些值。您可以调整这些值,看看它们如何影响网络的准确性。
要构建模型,您可以使用 estimator DNNClassifier。您可以将层数添加到 feature_columns 参数中。您需要将类别数量设置为 10,因为训练集中有十个类别。您已经熟悉了 estimator 对象的语法。feature_columns、n_classes 和 model_dir 参数与上一教程中的参数完全相同。新的 hidden_unit 参数控制层数以及要连接到神经网络的节点数。在下面的代码中,有两个隐藏层,第一个连接 300 个节点,第二个连接 100 个节点。
要构建 estimator,请使用 tf.estimator.DNNClassifier 并指定以下参数
- feature_columns:定义网络中要使用的列
- hidden_units:定义隐藏神经元的数量
- n_classes:定义要预测的类别数量
- model_dir:定义 TensorBoard 的路径
estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[300, 100],
n_classes=10,
model_dir = '/train/DNN')
步骤 5)训练和评估模型
您可以使用 numpy 方法来训练模型并对其进行评估
# Train the estimator
train_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_train_scaled},
y=y_train,
batch_size=50,
shuffle=False,
num_epochs=None)
estimator.train(input_fn = train_input,steps=1000)
eval_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_test_scaled},
y=y_test,
shuffle=False,
batch_size=X_test_scaled.shape[0],
num_epochs=1)
estimator.evaluate(eval_input,steps=None)
输出
{'accuracy': 0.9637143,
'average_loss': 0.12014342,
'loss': 1682.0079,
'global_step': 1000}
当前架构在评估集上的准确率为 96%。
步骤 6)改进模型
您可以尝试通过添加正则化参数来改进模型。
我们将使用 Adam 优化器,Dropout 率为 0.3,L1 为 X,L2 为 y。在 TensorFlow 神经网络中,您可以通过 train 对象后跟优化器名称来控制优化器。TensorFlow 是用于 Proximal AdaGrad 优化器的内置 API。
要为深度神经网络添加正则化,您可以使用 tf.train.ProximalAdagradOptimizer 并指定以下参数
- 学习率:learning_rate
- L1 正则化:l1_regularization_strength
- L2 正则化:l2_regularization_strength
estimator_imp = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[300, 100],
dropout=0.3,
n_classes = 10,
optimizer=tf.train.ProximalAdagradOptimizer(
learning_rate=0.01,
l1_regularization_strength=0.01,
l2_regularization_strength=0.01
),
model_dir = '/train/DNN1')
estimator_imp.train(input_fn = train_input,steps=1000)
estimator_imp.evaluate(eval_input,steps=None)
输出
{'accuracy': 0.95057142,
'average_loss': 0.17318928,
'loss': 2424.6499,
'global_step': 2000}
为减少过拟合而选择的值并未提高模型准确性。您的第一个模型准确率为 96%,而带有 L2 正则化的模型的准确率为 95%。您可以尝试不同的值,看看它们对准确性的影响。
摘要
在本教程中,您学习了如何构建神经网络。神经网络需要
- 隐藏层数量
- 全连接节点数量
- 激活函数
- 优化器
- 类别数量
在 TensorFlow ANN 中,您可以训练一个用于分类问题的神经网络,使用
- tf.estimator.DNNClassifier
该 estimator 需要指定
- feature_columns=feature_columns,
- hidden_units=[300, 100]
- n_classes=10
- model_dir
您可以通过使用不同的优化器来改进模型。在本教程中,您学习了如何使用 Adam Grad 优化器并设置学习率以及添加控制以防止过拟合。