机器学习中的高斯核:Python核方法
本教程的目的是使数据集线性可分。本教程分为两个部分
- 特征转换
- 使用Tensorflow训练核分类器
在第一部分中,您将了解机器学习中核方法的思想,而在第二部分中,您将看到如何使用Tensorflow训练核分类器。您将使用成人数据集。该数据集的目标是根据每个家庭的行为,将收入分为50k以上和50k以下进行分类。
为什么需要核方法?
每个分类器的目标都是正确预测类别。为此,数据集应该是可分的。看下面的图;很容易看出黑线以上的所有点都属于第一类,其他点属于第二类。然而,拥有如此简单的数据集是极其罕见的。在大多数情况下,数据是不可分的。机器学习中的核方法对逻辑回归等朴素分类器来说很困难。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D
x_lin = np.array([1,2,3,4,5,6,7,8,9,10]) y_lin = np.array([2,2,3,2,2,9,6,8,8,9]) label_lin = np.array([0,0,0,0,0,1,1,1,1,1]) fig = plt.figure() ax=fig.add_subplot(111) plt.scatter(x_lin, y_lin, c=label_lin, s=60) plt.plot([-2.5, 10], [12.5, -2.5], 'k-', lw=2) ax.set_xlim([-5,15]) ax.set_ylim([-5,15])plt.show()
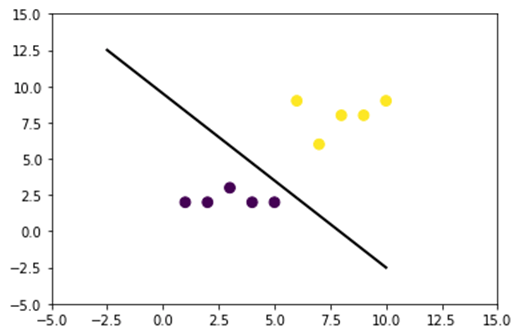
下图展示了一个非线性可分的数据集。如果我们画一条直线,大多数点都不能被正确分类。
解决此问题的一种方法是获取数据集并将其转换为另一个特征图。这意味着您将使用一个函数将数据转换为另一个平面,该平面应该是线性可分的。
x = np.array([1,1,2,3,3,6,6,6,9,9,10,11,12,13,16,18]) y = np.array([18,13,9,6,15,11,6,3,5,2,10,5,6,1,3,1]) label = np.array([1,1,1,1,0,0,0,1,0,1,0,0,0,1,0,1])
fig = plt.figure() plt.scatter(x, y, c=label, s=60) plt.show()
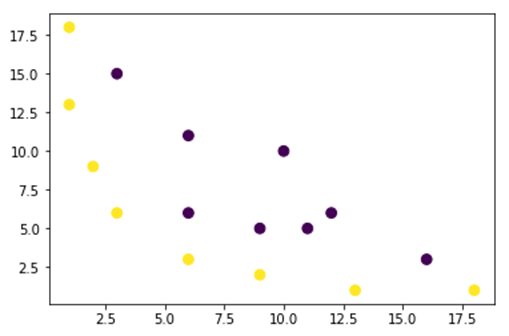
上面的图中的数据位于一个2D高斯核平面中,该平面是不可分的。您可以尝试将这些数据转换为三维,这意味着您将创建一个具有3个轴的图形。
在高斯核示例中,我们将应用多项式映射将我们的数据转换为三维。转换数据的公式如下。
![]()
您定义一个高斯核Python函数来创建新的特征图
您可以使用numpy来编写上述公式
| 公式 | 等效的Numpy代码 |
|---|---|
| x | x[:,0]** |
| ÿ | x[:,1] |
| x2 | x[:,0]**2 |
| np.sqrt(2)* | |
| xy | x[:,0]*x[:,1] |
| y2 | x[:,1]**2 |
### illustration purpose
def mapping(x, y):
x = np.c_[(x, y)]
if len(x) > 2:
x_1 = x[:,0]**2
x_2 = np.sqrt(2)*x[:,0]*x[:,1]
x_3 = x[:,1]**2
else:
x_1 = x[0]**2
x_2 = np.sqrt(2)*x[0]*x[1]
x_3 = x[1]**2
trans_x = np.array([x_1, x_2, x_3])
return trans_x
新的映射应该是3维的,包含16个点
x_1 = mapping(x, y) x_1.shape
(3, 16)
让我们用3个轴(分别为x、y和z)绘制一个新图。
# plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x_1[0], x_1[1], x_1[2], c=label, s=60)
ax.view_init(30, 185)ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.show()
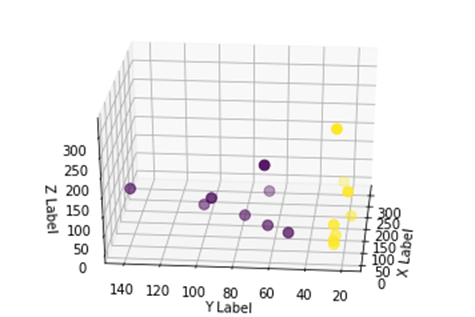
我们看到了改进,但是如果我们改变绘图的视角,就会清楚地发现数据集现在是可分的。
# plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x_1[0], x_1[1], x_1[1], c=label, s=60)
ax.view_init(0, -180)ax.set_ylim([150,-50])
ax.set_zlim([-10000,10000])
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')plt.show()
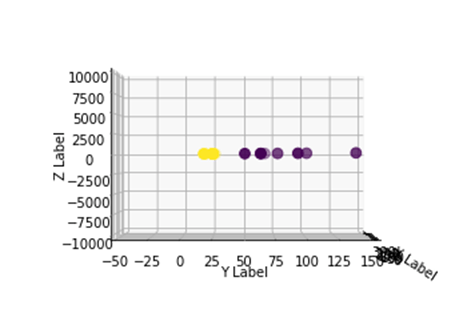
要处理大型数据集,您可能需要创建超过2个维度,使用上述方法将面临一个大问题。事实上,您需要转换所有数据点,这显然是不可持续的。这会花费您很长时间,而且您的计算机可能会耗尽内存。
克服此问题的最常见方法是使用**核**。
机器学习中的核是什么?
其思想是使用更高维度的特征空间使数据几乎线性可分,如上图所示。
有许多高维空间可以使数据点可分。例如,我们已经证明了多项式映射是一个很好的起点。
我们还证明了,对于大量数据,这些转换效率不高。相反,您可以使用机器学习中的核函数来修改数据,而无需转换为新的特征平面。
核的魔力在于找到一个函数,可以避免高维计算带来的所有麻烦。核的结果是一个标量,或者换句话说,我们回到了一个一维空间。
找到这个函数后,您可以将其插入标准的线性分类器。
让我们看一个例子来理解核机器学习的概念。您有两个向量x1和x2。目标是通过多项式映射创建更高维度。输出等于新特征图的点积。根据上述方法,您需要
- 将x1和x2转换为新维度
- 计算点积:所有核的通用方法
- 将x1和x2转换为新维度
您可以使用上面创建的函数来计算更高维度。
## Kernel x1 = np.array([3,6]) x2 = np.array([10,10]) x_1 = mapping(x1, x2) print(x_1)
输出
[[ 9. 100. ]
[ 25.45584412 141.42135624]
[ 36. 100. ]]
计算点积
您可以使用numpy的点积对象来计算存储在x_1中的第一个和第二个向量之间的点积。
print(np.dot(x_1[:,0], x_1[:,1])) 8100.0
输出是8100。您看到了问题,您需要将新的特征图存储在内存中才能计算点积。如果您有一个包含数百万条记录的数据集,那么计算效率低下。
相反,您可以使用**多项式核**来计算点积,而无需转换向量。此函数计算x1和x2的点积,就好像这两个向量已被转换为更高维度一样。换句话说,核函数从另一个特征空间计算点积的结果。
您可以用Python编写多项式核函数如下。
def polynomial_kernel(x, y, p=2): return (np.dot(x, y)) ** p
这是两个向量点积的幂。下面,您返回多项式核的二阶。输出与另一种方法相同。这就是核的魔力。
polynomial_kernel(x1, x2, p=2) 8100
核方法的类型
有许多不同的核技术可用。最简单的是线性核。此函数在文本分类中效果很好。另一个核是
- 多项式核
- 高斯核
在TensorFlow的示例中,我们将使用随机傅里叶变换。TensorFlow有一个内置的估计器来计算新的特征空间。高斯滤波器函数是高斯核函数的近似。
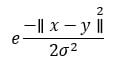
高斯滤波函数计算数据点在更高维度空间中的相似度。
使用TensorFlow训练高斯核分类器
该算法的目标是区分收入高于或低于50k的家庭。
您将评估一个逻辑回归核机器学习模型以获得基准模型。之后,您将训练一个核分类器,看看是否能获得更好的结果。
您使用成人数据集中的以下变量
- age
- 工作类别
- fnlwgt
- 教育
- 教育年限
- 婚姻状况
- 职业
- 关系
- 种族
- 性别
- 资本收益
- 资本损失
- 每周工时
- 国籍
- 标签
在训练和评估模型之前,您将按以下步骤进行
- 步骤1)导入库
- 步骤2)导入数据
- 步骤3)准备数据
- 步骤4)构建input_fn
- 步骤5)构建逻辑模型:基准模型
- 步骤6)评估模型
- 步骤7)构建核分类器
- 步骤8)评估核分类器
步骤1)导入库
要导入和训练人工智能中的核模型,您需要导入tensorflow、pandas和numpy
#import numpy as np from sklearn.model_selection import train_test_split import tensorflow as tf import pandas as pd import numpy as np
步骤2)导入数据
您从此网站下载数据,并将其导入为pandas数据框。
## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" PATH_test ="https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test "## Import df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_test = pd.read_csv(PATH_test,skiprows = 1, skipinitialspace=True, names = COLUMNS, index_col=False)
现在定义了训练集和测试集,您可以将列标签从字符串更改为整数。tensorflow不接受字符串作为标签值。
label = {'<=50K': 0,'>50K': 1}
df_train.label = [label[item] for item in df_train.label]
label_t = {'<=50K.': 0,'>50K.': 1}
df_test.label = [label_t[item] for item in df_test.label]
df_train.shape
(32561, 15)
步骤3)准备数据
该数据集包含连续和分类特征。一个好的做法是标准化连续变量的值。您可以使用sci-kit learn的StandardScaler函数。您还可以创建一个用户定义的函数,以便更轻松地转换训练集和测试集。请注意,您将连续变量和分类变量连接到一个公共数据集,并且数组的类型应为:float32
COLUMNS_INT = ['age','fnlwgt','education_num','capital_gain', 'capital_loss', 'hours_week']
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
from sklearn.preprocessing import StandardScaler
from sklearn import preprocessing
def prep_data_str(df):
scaler = StandardScaler()
le = preprocessing.LabelEncoder()
df_toscale = df[COLUMNS_INT]
df_scaled = scaler.fit_transform(df_toscale.astype(np.float64))
X_1 = df[CATE_FEATURES].apply(le.fit_transform)
y = df['label'].astype(np.int32)
X_conc = np.c_[df_scaled, X_1].astype(np.float32)
return X_conc, y
转换器函数已准备就绪,您可以转换数据集并创建input_fn函数。
X_train, y_train = prep_data_str(df_train) X_test, y_test = prep_data_str(df_test) print(X_train.shape) (32561, 14)
在下一步中,您将训练逻辑回归。这将为您提供基准准确率。目标是使用不同的算法,即核分类器来击败基准。
步骤4)构建逻辑模型:基准模型
您使用real_valued_column对象构建特征列。它将确保所有变量都是稠密的数值数据。
feat_column = tf.contrib.layers.real_valued_column('features', dimension=14)
使用TensorFlow Estimator定义估计器,指示特征列和保存图的位置。
estimator = tf.estimator.LinearClassifier(feature_columns=[feat_column],
n_classes=2,
model_dir = "kernel_log"
)
INFO:tensorflow:Using default config.INFO:tensorflow:Using config: {'_model_dir': 'kernel_log', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a2003f780>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
您将使用批量大小为200的微批量来训练逻辑回归。
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"features": X_train},
y=y_train,
batch_size=200,
num_epochs=None,
shuffle=True)
您可以训练模型1000次迭代
estimator.train(input_fn=train_input_fn, steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into kernel_log/model.ckpt. INFO:tensorflow:loss = 138.62949, step = 1 INFO:tensorflow:global_step/sec: 324.16 INFO:tensorflow:loss = 87.16762, step = 101 (0.310 sec) INFO:tensorflow:global_step/sec: 267.092 INFO:tensorflow:loss = 71.53657, step = 201 (0.376 sec) INFO:tensorflow:global_step/sec: 292.679 INFO:tensorflow:loss = 69.56703, step = 301 (0.340 sec) INFO:tensorflow:global_step/sec: 225.582 INFO:tensorflow:loss = 74.615875, step = 401 (0.445 sec) INFO:tensorflow:global_step/sec: 209.975 INFO:tensorflow:loss = 76.49044, step = 501 (0.475 sec) INFO:tensorflow:global_step/sec: 241.648 INFO:tensorflow:loss = 66.38373, step = 601 (0.419 sec) INFO:tensorflow:global_step/sec: 305.193 INFO:tensorflow:loss = 87.93341, step = 701 (0.327 sec) INFO:tensorflow:global_step/sec: 396.295 INFO:tensorflow:loss = 76.61518, step = 801 (0.249 sec) INFO:tensorflow:global_step/sec: 359.857 INFO:tensorflow:loss = 78.54885, step = 901 (0.277 sec) INFO:tensorflow:Saving checkpoints for 1000 into kernel_log/model.ckpt. INFO:tensorflow:Loss for final step: 67.79706. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x1a1fa3cbe0>
步骤6)评估模型
您定义numpy估计器来评估模型。您使用整个数据集进行评估
# Evaluation
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"features": X_test},
y=y_test,
batch_size=16281,
num_epochs=1,
shuffle=False)
estimator.evaluate(input_fn=test_input_fn, steps=1)
INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2018-07-12-15:58:22 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from kernel_log/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Evaluation [1/1] INFO:tensorflow:Finished evaluation at 2018-07-12-15:58:23 INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.82353663, accuracy_baseline = 0.76377374, auc = 0.84898686, auc_precision_recall = 0.67214864, average_loss = 0.3877216, global_step = 1000, label/mean = 0.23622628, loss = 6312.495, precision = 0.7362797, prediction/mean = 0.21208474, recall = 0.39417577
{'accuracy': 0.82353663,
'accuracy_baseline': 0.76377374,
'auc': 0.84898686,
'auc_precision_recall': 0.67214864,
'average_loss': 0.3877216,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 6312.495,
'precision': 0.7362797,
'prediction/mean': 0.21208474,
'recall': 0.39417577}
您的准确率为82%。在下一节中,您将尝试使用核分类器来改进逻辑回归。
步骤7)构建核分类器
核估计器与传统线性分类器在构造上差别不大。其思想是利用显式核的强大功能来配合线性分类器。
您需要TensorFlow中两个预定义的估计器来训练核分类器
- RandomFourierFeatureMapper
- KernelLinearClassifier
您在第一部分中了解到,需要使用核函数将低维转换为高维。更具体地说,您将使用随机傅里叶变换,这是高斯函数的近似。幸运的是,TensorFlow在其库中提供了该函数:RandomFourierFeatureMapper。可以使用KernelLinearClassifier估计器来训练模型。
要构建模型,您将遵循以下步骤
- 设置高维核函数
- 设置L2超参数
- 构建模型
- 训练模型
- 评估模型
步骤A)设置高维核函数
当前数据集包含14个特征,您将将其转换为一个5000维向量的新高维空间。您使用随机傅里叶特征来实现转换。如果您还记得高斯核公式,您会注意到有一个标准差参数需要定义。此参数控制分类期间使用的相似度度量。
您可以使用以下方法调整RandomFourierFeatureMapper中的所有参数
- input_dim = 14
- output_dim= 5000
- stddev=4
### Prep Kernel kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper(input_dim=14, output_dim=5000, stddev=4, name='rffm')
您需要使用之前创建的特征列:feat_column来构建核映射器。
### Map Kernel
kernel_mappers = {feat_column: [kernel_mapper]}
步骤B)设置L2超参数
为了防止过拟合,您使用L2正则化器来惩罚损失函数。您将L2超参数设置为0.1,学习率设置为5。
optimizer = tf.train.FtrlOptimizer(learning_rate=5, l2_regularization_strength=0.1)
步骤C)构建模型
下一步与线性分类类似。您使用内置估计器KernelLinearClassifier。请注意,您添加了前面定义的核映射器,并更改了模型目录。
### Prep estimator
estimator_kernel = tf.contrib.kernel_methods.KernelLinearClassifier(
n_classes=2,
optimizer=optimizer,
kernel_mappers=kernel_mappers,
model_dir="kernel_train")
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/kernel_methods/python/kernel_estimators.py:305: multi_class_head (from tensorflow.contrib.learn.python.learn.estimators.head) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.contrib.estimator.*_head.
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py:1179: BaseEstimator.__init__ (from tensorflow.contrib.learn.python.learn.estimators.estimator) is deprecated and will be removed in a future version.
Instructions for updating:
Please replace uses of any Estimator from tf.contrib.learn with an Estimator from tf.estimator.*
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py:427: RunConfig.__init__ (from tensorflow.contrib.learn.python.learn.estimators.run_config) is deprecated and will be removed in a future version.
Instructions for updating:
When switching to tf.estimator.Estimator, use tf.estimator.RunConfig instead.
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_task_type': None, '_task_id': 0, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a200ae550>, '_master': '', '_num_ps_replicas': 0, '_num_worker_replicas': 0, '_environment': 'local', '_is_chief': True, '_evaluation_master': '', '_train_distribute': None, '_tf_config': gpu_options {
per_process_gpu_memory_fraction: 1.0
}
, '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_secs': 600, '_log_step_count_steps': 100, '_session_config': None, '_save_checkpoints_steps': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_model_dir': 'kernel_train'}
步骤D)训练模型
现在核分类器已构建完成,您可以开始训练了。您选择迭代模型2000次。
### estimate estimator_kernel.fit(input_fn=train_input_fn, steps=2000)
WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool.
WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/estimators/head.py:678: ModelFnOps.__new__ (from tensorflow.contrib.learn.python.learn.estimators.model_fn) is deprecated and will be removed in a future version.
Instructions for updating:
When switching to tf.estimator.Estimator, use tf.estimator.EstimatorSpec. You can use the `estimator_spec` method to create an equivalent one.
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 1 into kernel_train/model.ckpt.
INFO:tensorflow:loss = 0.6931474, step = 1
INFO:tensorflow:global_step/sec: 86.6365
INFO:tensorflow:loss = 0.39374447, step = 101 (1.155 sec)
INFO:tensorflow:global_step/sec: 80.1986
INFO:tensorflow:loss = 0.3797774, step = 201 (1.247 sec)
INFO:tensorflow:global_step/sec: 79.6376
INFO:tensorflow:loss = 0.3908726, step = 301 (1.256 sec)
INFO:tensorflow:global_step/sec: 95.8442
INFO:tensorflow:loss = 0.41890752, step = 401 (1.043 sec)
INFO:tensorflow:global_step/sec: 93.7799
INFO:tensorflow:loss = 0.35700393, step = 501 (1.066 sec)
INFO:tensorflow:global_step/sec: 94.7071
INFO:tensorflow:loss = 0.35535482, step = 601 (1.056 sec)
INFO:tensorflow:global_step/sec: 90.7402
INFO:tensorflow:loss = 0.3692882, step = 701 (1.102 sec)
INFO:tensorflow:global_step/sec: 94.4924
INFO:tensorflow:loss = 0.34746957, step = 801 (1.058 sec)
INFO:tensorflow:global_step/sec: 95.3472
INFO:tensorflow:loss = 0.33655524, step = 901 (1.049 sec)
INFO:tensorflow:global_step/sec: 97.2928
INFO:tensorflow:loss = 0.35966292, step = 1001 (1.028 sec)
INFO:tensorflow:global_step/sec: 85.6761
INFO:tensorflow:loss = 0.31254214, step = 1101 (1.167 sec)
INFO:tensorflow:global_step/sec: 91.4194
INFO:tensorflow:loss = 0.33247527, step = 1201 (1.094 sec)
INFO:tensorflow:global_step/sec: 82.5954
INFO:tensorflow:loss = 0.29305756, step = 1301 (1.211 sec)
INFO:tensorflow:global_step/sec: 89.8748
INFO:tensorflow:loss = 0.37943482, step = 1401 (1.113 sec)
INFO:tensorflow:global_step/sec: 76.9761
INFO:tensorflow:loss = 0.34204718, step = 1501 (1.300 sec)
INFO:tensorflow:global_step/sec: 73.7192
INFO:tensorflow:loss = 0.34614792, step = 1601 (1.356 sec)
INFO:tensorflow:global_step/sec: 83.0573
INFO:tensorflow:loss = 0.38911164, step = 1701 (1.204 sec)
INFO:tensorflow:global_step/sec: 71.7029
INFO:tensorflow:loss = 0.35255936, step = 1801 (1.394 sec)
INFO:tensorflow:global_step/sec: 73.2663
INFO:tensorflow:loss = 0.31130585, step = 1901 (1.365 sec)
INFO:tensorflow:Saving checkpoints for 2000 into kernel_train/model.ckpt.
INFO:tensorflow:Loss for final step: 0.37795097.
KernelLinearClassifier(params={'head': <tensorflow.contrib.learn.python.learn.estimators.head._BinaryLogisticHead object at 0x1a2054cd30>, 'feature_columns': {_RealValuedColumn(column_name='features_MAPPED', dimension=5000, default_value=None, dtype=tf.float32, normalizer=None)}, 'optimizer': <tensorflow.python.training.ftrl.FtrlOptimizer object at 0x1a200aec18>, 'kernel_mappers': {_RealValuedColumn(column_name='features', dimension=14, default_value=None, dtype=tf.float32, normalizer=None): [<tensorflow.contrib.kernel_methods.python.mappers.random_fourier_features.RandomFourierFeatureMapper object at 0x1a200ae400>]}})
步骤E)评估模型
最后但同样重要的是,您要评估模型的性能。您应该能够超越逻辑回归。
# Evaluate and report metrics. eval_metrics = estimator_kernel.evaluate(input_fn=test_input_fn, steps=1)
WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool. WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Starting evaluation at 2018-07-12-15:58:50 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from kernel_train/model.ckpt-2000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Evaluation [1/1] INFO:tensorflow:Finished evaluation at 2018-07-12-15:58:51 INFO:tensorflow:Saving dict for global step 2000: accuracy = 0.83975184, accuracy/baseline_label_mean = 0.23622628, accuracy/threshold_0.500000_mean = 0.83975184, auc = 0.8904007, auc_precision_recall = 0.72722375, global_step = 2000, labels/actual_label_mean = 0.23622628, labels/prediction_mean = 0.23786618, loss = 0.34277728, precision/positive_threshold_0.500000_mean = 0.73001117, recall/positive_threshold_0.500000_mean = 0.5104004
最终准确率为84%,比逻辑回归提高了2%。准确率提高与计算成本之间存在权衡。您需要考虑2%的改进是否值得分类器花费的时间,以及它是否对您的业务有显著影响。
摘要
核是一种将非线性数据转换为(近似)线性的强大工具。这种方法的缺点是计算耗时且成本高昂。
下面是训练核分类器最重要的代码
设置高维核函数
- input_dim = 14
- output_dim= 5000
- stddev=4
### Prep Kernelkernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper(input_dim=14, output_dim=5000, stddev=4, name='rffm')
设置L2超参数
optimizer = tf.train.FtrlOptimizer(learning_rate=5, l2_regularization_strength=0.1)
构建模型
estimator_kernel = tf.contrib.kernel_methods.KernelLinearClassifier( n_classes=2,
optimizer=optimizer,
kernel_mappers=kernel_mappers,
model_dir="kernel_train")
训练模型
estimator_kernel.fit(input_fn=train_input_fn, steps=2000)
评估模型
eval_metrics = estimator_kernel.evaluate(input_fn=test_input_fn, steps=1)