Python Pandas 教程:DataFrame、日期范围、Pandas 的使用
什么是 Pandas Python?
Pandas 是一个开源库,允许您在 Python 中执行数据操作和分析。Pandas Python 库为数值表格和时间序列提供了数据操作和数据操作。Pandas 提供了一种创建、操作和整理数据的简便方法。它建立在 NumPy 之上,这意味着它需要 NumPy 来运行。
为什么使用 Pandas?
数据科学家在 Python 中使用 Pandas 是因为它具有以下优点:
- 轻松处理丢失的数据
- 它使用 Series 作为一维数据结构,使用 DataFrame 作为多维数据结构。
- 它提供了一种高效的数据切片方法。
- 它提供了一种灵活的数据合并、连接或重塑方法。
- 它包含一个强大的时间序列工具。
总而言之,Pandas 是一个在数据分析中非常有用的库。它可以用于执行数据操作和分析。Pandas 提供了强大且易于使用的数据结构,以及对这些结构快速执行操作的方法。
如何安装 Pandas?
现在,在本 Python Pandas 教程中,我们将学习如何在 Python 中安装 Pandas。
要安装 Pandas 库,请参阅我们的教程如何安装 TensorFlow。Pandas 默认已安装。在极少数情况下,如果 Pandas 未安装:
您可以使用以下命令安装 Pandas:
- Anaconda:conda install -c anaconda pandas
- 在 Jupyter Notebook 中
import sys
!conda install --yes --prefix {sys.prefix} pandas
什么是 Pandas DataFrame?
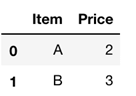
Pandas DataFrame 是一个具有不同列类型的二维带标签数据结构。DataFrame 是以表格格式存储数据的标准方法,其中行存储信息,列命名信息。例如,价格可以是一列的名称,2、3、4 可以是价格值。
DataFrame 为统计学家和其他数据从业者所熟知。
下方是 Pandas 数据帧的图片
什么是 Series?
Series 是一维数据结构。它可以包含任何数据结构,如整数、浮点数和字符串。当您想执行计算或返回一维数组时,它非常有用。根据定义,Series 不能有多列。后一种情况,请使用 DataFrame 结构。
Python Pandas Series 具有以下参数:
- 数据:可以是列表、字典或标量值。
pd.Series([1., 2., 3.])
0 1.0 1 2.0 2 3.0 dtype: float64
您可以通过 index 添加索引。它有助于命名行。长度应等于列的大小。
pd.Series([1., 2., 3.], index=['a', 'b', 'c'])
下面,您将创建一个带有第三行缺失值的 Pandas Series。请注意,Python 中的缺失值用“NaN”表示。您可以使用 numpy 人工创建缺失值:np.nan。
pd.Series([1,2,np.nan])
输出
0 1.0 1 2.0 2 NaN dtype: float64
创建 Pandas DataFrame
现在,在本 Pandas DataFrame 教程中,我们将学习如何创建 Python Pandas DataFrame。
您可以使用 pd.DataFrame() 将 numpy 数组转换为 pandas DataFrame。反之亦然。要将 pandas DataFrame 转换为数组,您可以使用 np.array()。
## Numpy to pandas
import numpy as np
h = [[1,2],[3,4]]
df_h = pd.DataFrame(h)
print('Data Frame:', df_h)
## Pandas to numpy
df_h_n = np.array(df_h)
print('Numpy array:', df_h_n)
Data Frame: 0 1
0 1 2
1 3 4
Numpy array: [[1 2]
[3 4]]
您还可以使用字典来创建 Pandas DataFrame。
dic = {'Name': ["John", "Smith"], 'Age': [30, 40]}
pd.DataFrame(data=dic)
| 年龄 | 名称 | |
|---|---|---|
| 0 | 30 | John |
| 1 | 40 | 史密斯 |
Pandas 范围数据
Pandas 提供了一个方便的 API 来创建日期范围。让我们通过 Python Pandas 示例来学习。
pd.data_range(date,period,frequency)
- 第一个参数是起始日期。
- 第二个参数是期间数(如果指定了结束日期,则可选)。
- 最后一个参数是频率:日:“D”,月:“M”,年:“Y”。
## Create date
# Days
dates_d = pd.date_range('20300101', periods=6, freq='D')
print('Day:', dates_d)
输出
Day: DatetimeIndex(['2030-01-01', '2030-01-02', '2030-01-03', '2030-01-04', '2030-01-05', '2030-01-06'], dtype='datetime64[ns]', freq='D')
# Months
dates_m = pd.date_range('20300101', periods=6, freq='M')
print('Month:', dates_m)
输出
Month: DatetimeIndex(['2030-01-31', '2030-02-28', '2030-03-31', '2030-04-30','2030-05-31', '2030-06-30'], dtype='datetime64[ns]', freq='M')
检查数据
您可以使用 head() 或 tail() 检查数据集的头部或尾部,前面加上 pandas DataFrame 的名称,如以下 Pandas 示例所示。
步骤 1) 使用 numpy 创建一个随机序列。该序列有 4 列和 6 行。
random = np.random.randn(6,4)
步骤 2) 然后您使用 pandas 创建一个 DataFrame。
使用 dates_m 作为 DataFrame 的索引。这意味着每一行都会被赋予一个“名称”或索引,对应一个日期。
最后,您使用 columns 参数为 4 列命名。
# Create data with date
df = pd.DataFrame(random,
index=dates_m,
columns=list('ABCD'))
步骤 3) 使用 head 函数。
df.head(3)
| A | B | C | D | |
|---|---|---|---|---|
| 2030-01-31 | 1.139433 | 1.318510 | -0.181334 | 1.615822 |
| 2030-02-28 | -0.081995 | -0.063582 | 0.857751 | -0.527374 |
| 2030-03-31 | -0.519179 | 0.080984 | -1.454334 | 1.314947 |
步骤 4)使用 tail 函数。
df.tail(3)
| A | B | C | D | |
|---|---|---|---|---|
| 2030-04-30 | -0.685448 | -0.011736 | 0.622172 | 0.104993 |
| 2030-05-31 | -0.935888 | -0.731787 | -0.558729 | 0.768774 |
| 2030-06-30 | 1.096981 | 0.949180 | -0.196901 | -0.471556 |
步骤 5)使用 describe() 获取数据线索是一个很好的实践。它提供了数据集的计数、平均值、标准差、最小值、最大值和百分位数。
df.describe()
| A | B | C | D | |
|---|---|---|---|---|
| 计数 | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| 平均值 | 0.002317 | 0.256928 | -0.151896 | 0.467601 |
| 标准差 | 0.908145 | 0.746939 | 0.834664 | 0.908910 |
| min | -0.935888 | -0.731787 | -1.454334 | -0.527374 |
| 25% | -0.643880 | -0.050621 | -0.468272 | -0.327419 |
| 50% | -0.300587 | 0.034624 | -0.189118 | 0.436883 |
| 75% | 0.802237 | 0.732131 | 0.421296 | 1.178404 |
| max | 1.139433 | 1.318510 | 0.857751 | 1.615822 |
切片数据
本 Python Pandas 教程的最后一点是关于如何对 pandas DataFrame 进行切片。
您可以使用列名来提取特定列中的数据,如以下 Pandas 示例所示。
## Slice ### Using name df['A'] 2030-01-31 -0.168655 2030-02-28 0.689585 2030-03-31 0.767534 2030-04-30 0.557299 2030-05-31 -1.547836 2030-06-30 0.511551 Freq: M, Name: A, dtype: float64
要选择多列,您需要使用两次方括号,[[..,..]]。
第一个方括号表示您要选择列,第二个方括号表示您要返回哪些列。
df[['A', 'B']].
| A | B | |
|---|---|---|
| 2030-01-31 | -0.168655 | 0.587590 |
| 2030-02-28 | 0.689585 | 0.998266 |
| 2030-03-31 | 0.767534 | -0.940617 |
| 2030-04-30 | 0.557299 | 0.507350 |
| 2030-05-31 | -1.547836 | 1.276558 |
| 2030-06-30 | 0.511551 | 1.572085 |
您可以使用以下方法切片行:
以下代码返回前三行:
### using a slice for row df[0:3]
| A | B | C | D | |
|---|---|---|---|---|
| 2030-01-31 | -0.168655 | 0.587590 | 0.572301 | -0.031827 |
| 2030-02-28 | 0.689585 | 0.998266 | 1.164690 | 0.475975 |
| 2030-03-31 | 0.767534 | -0.940617 | 0.227255 | -0.341532 |
loc 函数用于按名称选择列。通常,逗号前的值代表行,之后的值代表列。您需要使用方括号来选择多个列。
## Multi col df.loc[:,['A','B']]
| A | B | |
|---|---|---|
| 2030-01-31 | -0.168655 | 0.587590 |
| 2030-02-28 | 0.689585 | 0.998266 |
| 2030-03-31 | 0.767534 | -0.940617 |
| 2030-04-30 | 0.557299 | 0.507350 |
| 2030-05-31 | -1.547836 | 1.276558 |
| 2030-06-30 | 0.511551 | 1.572085 |
在 Pandas 中还有另一种选择多行和多列的方法。您可以使用 iloc[]。此方法使用索引而不是列名。以下代码返回与上面相同的数据帧:
df.iloc[:, :2]
| A | B | |
|---|---|---|
| 2030-01-31 | -0.168655 | 0.587590 |
| 2030-02-28 | 0.689585 | 0.998266 |
| 2030-03-31 | 0.767534 | -0.940617 |
| 2030-04-30 | 0.557299 | 0.507350 |
| 2030-05-31 | -1.547836 | 1.276558 |
| 2030-06-30 | 0.511551 | 1.572085 |
删除列
您可以使用 pd.drop() 删除列。
df.drop(columns=['A', 'C'])
| B | D | |
|---|---|---|
| 2030-01-31 | 0.587590 | -0.031827 |
| 2030-02-28 | 0.998266 | 0.475975 |
| 2030-03-31 | -0.940617 | -0.341532 |
| 2030-04-30 | 0.507350 | -0.296035 |
| 2030-05-31 | 1.276558 | 0.523017 |
| 2030-06-30 | 1.572085 | -0.594772 |
连接
您可以在 Pandas 中连接两个 DataFrame。您可以使用 pd.concat()。
首先,您需要创建两个 DataFrame。到目前为止,您已经熟悉了 DataFrame 的创建。
import numpy as np
df1 = pd.DataFrame({'name': ['John', 'Smith','Paul'],
'Age': ['25', '30', '50']},
index=[0, 1, 2])
df2 = pd.DataFrame({'name': ['Adam', 'Smith' ],
'Age': ['26', '11']},
index=[3, 4])
最后,您连接了这两个 DataFrame。
df_concat = pd.concat([df1,df2]) df_concat
| 年龄 | 姓名 | |
|---|---|---|
| 0 | 25 | John |
| 1 | 30 | 史密斯 |
| 2 | 50 | Paul |
| 3 | 26 | Adam |
| 4 | 11 | 史密斯 |
删除重复项
如果数据集可能包含重复信息,使用 `drop_duplicates` 可以轻松排除重复行。您可以看到 `df_concat` 有一个重复的观测值,“Smith”在 `name` 列中出现了两次。
df_concat.drop_duplicates('name')
| 年龄 | 姓名 | |
|---|---|---|
| 0 | 25 | John |
| 1 | 30 | 史密斯 |
| 2 | 50 | Paul |
| 3 | 26 | Adam |
对值进行排序
您可以使用 sort_values 对值进行排序。
df_concat.sort_values('Age')
| 年龄 | 姓名 | |
|---|---|---|
| 4 | 11 | 史密斯 |
| 0 | 25 | John |
| 3 | 26 | Adam |
| 1 | 30 | 史密斯 |
| 2 | 50 | Paul |
重命名:更改索引
您可以使用 rename 在 Pandas 中重命名列。第一个值是当前列名,第二个值是新的列名。
df_concat.rename(columns={"name": "Surname", "Age": "Age_ppl"})
| Age_ppl | 姓氏 | |
|---|---|---|
| 0 | 25 | John |
| 1 | 30 | 史密斯 |
| 2 | 50 | Paul |
| 3 | 26 | Adam |
| 4 | 11 | 史密斯 |
摘要
以下是数据科学中最有用的 Pandas 方法的摘要:
| 导入数据 | read_csv |
|---|---|
| 创建 series | Series |
| 创建 DataFrame | DataFrame |
| 创建日期范围 | date_range |
| 返回头部 | head |
| 返回尾部 | tail |
| 描述 | describe |
| 按名称切片 | dataname[‘columnname’] |
| 按行切片 | data_name[0:5] |