TensorFlow 中的自动编码器及示例
什么是深度学习中的自编码器?
自编码器是一种以无监督方式高效学习数据编码的工具。它是一种人工神经网络,通过训练神经网络忽略信号噪声来帮助您学习数据集的表示以进行降维。它是重建输入的绝佳工具。
简而言之,机器可以接收,比如一张图片,并生成一张非常相似的图片。这种神经网络的输入是未标记的,意味着网络可以在没有监督的情况下进行学习。更准确地说,输入被网络编码以仅关注最关键的特征。这也是自编码器在降维方面受欢迎的原因之一。此外,自编码器可用于生成生成式学习模型。例如,神经网络可以与一组人脸进行训练,然后生成新的人脸。
TensorFlow自编码器如何工作?
自编码器的目的是通过仅关注基本特征来生成输入的近似值。您可能会想,为什么不直接学习复制粘贴输入来生成输出呢?事实上,自编码器是一系列约束,迫使网络学习新的数据表示方式,而不是简单地复制输出。
典型的自编码器由一个输入、一个内部表示和一个输出(输入近似值)定义。学习发生在附加到内部表示的层中。事实上,有两个主要的层块,它们看起来像传统的神经网络。细微的区别在于输出层必须等于输入层。在下图所示中,原始输入进入第一个块,称为编码器。这个内部表示会压缩(减小)输入的大小。在第二个块中,发生输入的重建。这是解码阶段。
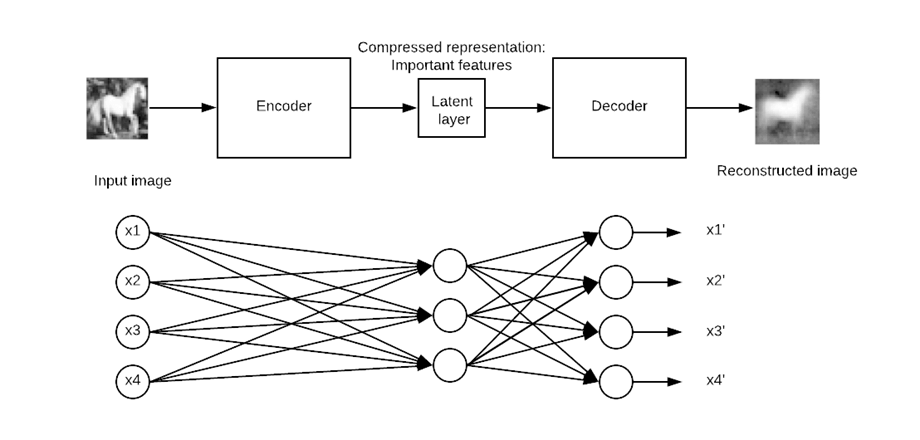
模型将通过最小化损失函数来更新权重。如果重建输出与输入不同,模型将受到惩罚。
具体来说,想象一个大小为 50×50(即 250 像素)的图片,和一个只有一个包含一百个神经元的隐藏层的神经网络。学习是在一个比输入小两倍的特征图上进行的。这意味着网络需要找到一种方法,仅通过一个等于 100 的神经元向量来重建 250 像素。
堆叠自编码器示例
在本自编码器教程中,您将学习如何使用堆叠自编码器。其架构类似于传统的神经网络。输入进入隐藏层以进行压缩,或减小其大小,然后到达重建层。目标是生成一个与原始图像尽可能接近的输出图像。模型必须学习一种方法来在给定一组约束(即较低的维度)下完成其任务。
如今,深度学习中的自编码器主要用于图像去噪。想象一张有划痕的图片;人仍然能够识别内容。去噪自编码器的想法是给图片添加噪声,以迫使网络学习数据背后的模式。
另一个有用的自编码器深度学习家族是变分自编码器。这类网络可以生成新图像。想象一下,您用一个男人的图像训练了一个网络;这样的网络可以生成新的人脸。
如何使用TensorFlow构建自编码器
在本教程中,您将学习如何构建一个堆叠自编码器来重建图像。
您将使用 CIFAR-10 数据集,该数据集包含 60000 张 32×32 的彩色图像。自编码器数据集已经分为 50000 张用于训练,10000 张用于测试。最多有十个类别
- 飞机
- 汽车
- 鸟
- 猫
- 鹿
- 狗
- 青蛙
- 马
- 船
- 卡车
您需要从此 URL https://www.cs.toronto.edu/~kriz/cifar.html 下载图像并解压缩。for-10-batches-py 文件夹包含五个数据批次,每个批次包含 10000 张以随机顺序排列的图像。
在构建和训练模型之前,您需要应用一些数据处理。您将按以下步骤进行
- 导入数据
- 将数据转换为黑白格式
- 追加所有批次
- 构建训练数据集
- 构建图像可视化器
图像预处理
步骤 1) 导入数据
根据官方网站,您可以使用以下代码上传数据。自编码器代码会将数据加载到一个字典中,其中包含data和label。请注意,代码是一个函数。
import numpy as np
import tensorflow as tf
import pickle
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='latin1')
return dict
步骤 2)将数据转换为黑白格式
为了简单起见,您将把数据转换为灰度。也就是说,只有一个维度,而不是彩色图像的三个维度。大多数神经网络仅处理一个维度输入。
def grayscale(im):
return im.reshape(im.shape[0], 3, 32, 32).mean(1).reshape(im.shape[0], -1)
步骤 3)追加所有批次
现在两个函数都已创建并且数据集已加载,您可以编写一个循环将数据追加到内存中。如果您仔细检查,带有数据的解压缩文件名为 data_batch_,后面跟着一个从 1 到 5 的数字。您可以循环遍历文件并将其追加到 data 中。
完成此步骤后,您将彩色数据转换为灰度格式。如您所见,数据的形状是 50000 和 1024。32*32 像素现在被展平为 2014。
# Load the data into memory
data, labels = [], []
## Loop over the b
for i in range(1, 6):
filename = './cifar-10-batches-py/data_batch_' + str(i)
open_data = unpickle(filename)
if len(data) > 0:
data = np.vstack((data, open_data['data']))
labels = np.hstack((labels, open_data['labels']))
else:
data = open_data['data']
labels = open_data['labels']
data = grayscale(data)
x = np.matrix(data)
y = np.array(labels)
print(x.shape)
(50000, 1024)
注意:将 './cifar-10-batches-py/data_batch_' 更改为文件的实际位置。例如,对于 Windows 机器,路径可能是 filename = ‘E:\cifar-10-batches-py\data_batch_’ + str(i)
步骤 4)构建训练数据集
为了使训练更快更容易,您将仅在马图像上训练模型。马是标签数据中的第七类。如 CIFAR-10 数据集文档中所述,每个类别包含 5000 张图像。您可以打印数据的形状以确认有 5000 张图像,其中包含 1024 列,如下面的 TensorFlow 自编码器示例步骤所示。
horse_i = np.where(y == 7)[0] horse_x = x[horse_i] print(np.shape(horse_x)) (5000, 1024)
步骤 5)构建图像可视化器
最后,您构建一个函数来绘制图像。您将需要此函数来打印自编码器生成的重建图像。
打印图像的一种简单方法是使用 matplotlib 库的 imshow 对象。请注意,您需要将数据的形状从 1024 转换为 32*32(即图像的格式)。
# To plot pretty figures
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
def plot_image(image, shape=[32, 32], cmap = "Greys_r"):
plt.imshow(image.reshape(shape), cmap=cmap,interpolation="nearest")
plt.axis("off")
该函数接受 3 个参数
- Image:输入
- Shape:列表,图像的尺寸
- Cmap:选择颜色映射。默认为灰色
您可以尝试绘制数据集中的第一张图像。您应该会看到一个骑马的人。
plot_image(horse_x[1], shape=[32, 32], cmap = "Greys_r")

设置数据集估算器
好的,现在数据集已准备就绪,您可以开始使用 TensorFlow。在构建模型之前,让我们使用 TensorFlow 的 Dataset 估算器来馈送网络。
您将使用 TensorFlow 估算器构建一个 Dataset。为了帮助您回忆,您需要使用
- from_tensor_slices
- repeat
- batch
构建数据集的完整代码是
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
注意,x 是一个占位符,其形状如下
- [None,n_inputs]:设置为 None,因为输入到网络的图像数量等于批次大小。
有关详细信息,请参阅关于线性回归的教程。
之后,您需要创建迭代器。没有这一行代码,将没有数据通过管道。
iter = dataset.make_initializable_iterator() # create the iteratorfeatures = iter.get_next()
现在管道已准备就绪,您可以检查第一张图像是否与之前相同(即,一个骑马的人)。
您将批次大小设置为 1,因为您只想将数据集输入一个图像。您可以使用 print(sess.run(features).shape) 查看数据的维度。它等于 (1, 1024)。1 表示每次只输入一个 1024 图像。如果批次大小设置为 2,则会有两个图像通过管道。(不要更改批次大小。否则会报错。只有一张图像可以一次通过 plot_image() 函数。
## Parameters
n_inputs = 32 * 32
BATCH_SIZE = 1
batch_size = tf.placeholder(tf.int64)
# using a placeholder
x = tf.placeholder(tf.float32, shape=[None,n_inputs])
## Dataset
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
iter = dataset.make_initializable_iterator() # create the iterator
features = iter.get_next()
## Print the image
with tf.Session() as sess:
# feed the placeholder with data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print(sess.run(features).shape)
plot_image(sess.run(features), shape=[32, 32], cmap = "Greys_r")
(1, 1024)

构建网络
是时候构建网络了。您将训练一个堆叠自编码器,即一个具有多个隐藏层的网络。
您的网络将有一个输入层,包含 1024 个点,即 32×32,图像的形状。
编码器块将有一个顶层隐藏层(300 个神经元),一个中间层(150 个神经元)。解码器块与编码器对称。您可以在下图所示中可视化网络。请注意,您可以更改隐藏层和中间层的值。
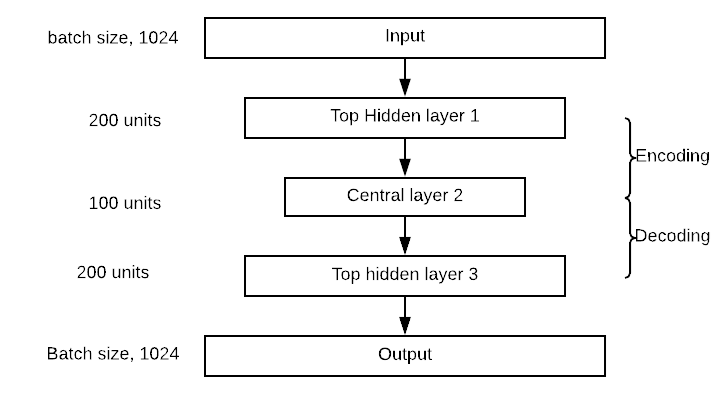
构建自编码器与构建其他任何深度学习模型非常相似。
您将按照以下步骤构建模型
- 定义参数
- 定义层
- 定义架构
- 定义优化
- 运行模型
- 评估模型
在上一节中,您学习了如何创建一个数据管道来馈送模型,因此无需再次创建数据集。您将构建一个具有四个层的自编码器。您使用 Xavier 初始化。这是一种将初始权重设置为等于输入和输出方差的技术。最后,您使用 elu 激活函数。您使用 L2 正则化来正则化损失函数。
步骤 1) 定义参数
第一步涉及定义每层神经元的数量、学习率和正则化器的超参数。
在此之前,您将部分导入函数。这是定义密集层参数的更好方法。以下代码定义了自编码器架构的值。如前所述,自编码器有两层,第一层有 300 个神经元,第二层有 150 个神经元。它们的值存储在 n_hidden_1 和 n_hidden_2 中。
您需要定义学习率和 L2 正则化器。这些值存储在 learning_rate 和 l2_reg 中
from functools import partial ## Encoder n_hidden_1 = 300 n_hidden_2 = 150 # codings ## Decoder n_hidden_3 = n_hidden_1 n_outputs = n_inputs learning_rate = 0.01 l2_reg = 0.0001
Xavier 初始化技术通过估算器 contrib 中的 xavier_initializer 对象进行调用。在同一个估算器中,您可以使用 l2_regularizer 添加正则化器
## Define the Xavier initialization xav_init = tf.contrib.layers.xavier_initializer() ## Define the L2 regularizer l2_regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
步骤 2) 定义层
所有密集层的参数都已设置好,您可以使用 partial 对象将所有内容打包到 dense_layer 变量中。dense_layer 使用 ELU 激活、Xavier 初始化和 L2 正则化。
## Create the dense layer
dense_layer = partial(tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=xav_init,
kernel_regularizer=l2_regularizer)
步骤 3) 定义架构
如果您查看架构图,您会注意到网络堆叠了三层和一个输出层。在下面的代码中,您连接了适当的层。例如,第一层计算输入矩阵特征与包含 300 个权重的矩阵之间的点积。计算点积后,输出会传递到 Elu 激活函数。输出成为下一层的输入,这就是为什么您使用它来计算 hidden_2 等等。由于您使用相同的激活函数,因此矩阵乘法对于每一层都是相同的。请注意,最后一层,即输出层,不应用激活函数。这是有意义的,因为这是重建的输入。
## Make the mat mul hidden_1 = dense_layer(features, n_hidden_1) hidden_2 = dense_layer(hidden_1, n_hidden_2) hidden_3 = dense_layer(hidden_2, n_hidden_3) outputs = dense_layer(hidden_3, n_outputs, activation=None)
步骤 4) 定义优化
最后一步是构建优化器。您使用均方误差作为损失函数。如果您还记得线性回归教程,您会知道 MSE 是通过预测输出与实际标签之间的差异来计算的。在这里,标签是特征,因为模型试图重建输入。因此,您希望得到预测输出与输入之间平方差之和的平均值。在 TensorFlow 中,您可以如下编写损失函数
loss = tf.reduce_mean(tf.square(outputs - features))
然后,您需要优化损失函数。您使用 Adam 优化器来计算梯度。目标函数是最小化损失。
## Optimize loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)
在训练模型之前还需要一个设置。您想使用批次大小为 150,也就是说,每次迭代将 150 张图像输入到管道中。您需要手动计算迭代次数。这很简单
如果您想每次传入 150 张图像,并且您知道数据集中有 5000 张图像,那么迭代次数等于。在 Python 中,您可以运行以下代码并确保输出为 33
BATCH_SIZE = 150 ### Number of batches : length dataset / batch size n_batches = horse_x.shape[0] // BATCH_SIZE print(n_batches) 33
步骤 5) 运行模型
最后但同样重要的一点是训练模型。您正在使用 100 个 epoch 来训练模型。也就是说,模型将看到 100 次图像以优化权重。
您已经熟悉了 TensorFlow 中训练模型的代码。细微的区别在于在运行训练之前将数据管道化。这样,模型训练得更快。
您有兴趣在十个 epoch 后打印损失,以查看模型是否正在学习(即,损失是否在下降)。训练需要 2 到 5 分钟,具体取决于您的机器硬件。
## Set params
n_epochs = 100
## Call Saver to save the model and re-use it later during evaluation
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# initialise iterator with train data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print('Training...')
print(sess.run(features).shape)
for epoch in range(n_epochs):
for iteration in range(n_batches):
sess.run(train)
if epoch % 10 == 0:
loss_train = loss.eval() # not shown
print("\r{}".format(epoch), "Train MSE:", loss_train)
#saver.save(sess, "./my_model_all_layers.ckpt")
save_path = saver.save(sess, "./model.ckpt")
print("Model saved in path: %s" % save_path)
Training...
(150, 1024)
0 Train MSE: 2934.455
10 Train MSE: 1672.676
20 Train MSE: 1514.709
30 Train MSE: 1404.3118
40 Train MSE: 1425.058
50 Train MSE: 1479.0631
60 Train MSE: 1609.5259
70 Train MSE: 1482.3223
80 Train MSE: 1445.7035
90 Train MSE: 1453.8597
Model saved in path: ./model.ckpt
步骤 6) 评估模型
现在您的模型已训练完毕,是时候评估它了。您需要从文件 /cifar-10-batches-py/ 导入测试集。
test_data = unpickle('./cifar-10-batches-py/test_batch')
test_x = grayscale(test_data['data'])
#test_labels = np.array(test_data['labels'])
注意:对于 Windows 机器,代码变为 test_data = unpickle(r”E:\cifar-10-batches-py\test_batch”)
您可以尝试打印图像 13,这是一匹马
plot_image(test_x[13], shape=[32, 32], cmap = "Greys_r")

为了评估模型,您将使用此图像的像素值,并查看编码器在缩小 1024 像素后是否可以重建相同的图像。请注意,您定义了一个函数来评估模型在不同图像上的表现。模型应该只在马图像上表现更好。
该函数接受两个参数
- df:导入测试数据
- image_number:指示要导入哪个图像
该函数分为三个部分
- 将图像重塑为正确的尺寸,即 1, 1024
- 使用未见过的图像馈送模型,编码/解码图像
- 打印真实图像和重建图像
def reconstruct_image(df, image_number = 1):
## Part 1: Reshape the image to the correct dimension i.e 1, 1024
x_test = df[image_number]
x_test_1 = x_test.reshape((1, 32*32))
## Part 2: Feed the model with the unseen image, encode/decode the image
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(iter.initializer, feed_dict={x: x_test_1,
batch_size: 1})
## Part 3: Print the real and reconstructed image
# Restore variables from disk.
saver.restore(sess, "./model.ckpt")
print("Model restored.")
# Reconstruct image
outputs_val = outputs.eval()
print(outputs_val.shape)
fig = plt.figure()
# Plot real
ax1 = fig.add_subplot(121)
plot_image(x_test_1, shape=[32, 32], cmap = "Greys_r")
# Plot estimated
ax2 = fig.add_subplot(122)
plot_image(outputs_val, shape=[32, 32], cmap = "Greys_r")
plt.tight_layout()
fig = plt.gcf()
现在评估函数已定义,您可以查看第十三张重建的图像
reconstruct_image(df =test_x, image_number = 13)
INFO:tensorflow:Restoring parameters from ./model.ckpt Model restored. (1, 1024)

摘要
- 自编码器的主要目的是压缩输入数据,然后将其解压缩为与原始数据非常相似的输出。
- 自编码器的架构是对称的,其中有一个称为中心层的枢轴层。
- 您可以使用以下方式创建自编码器
Partial:使用典型设置创建密集层
tf.layers.dense, activation=tf.nn.elu, kernel_initializer=xav_init, kernel_regularizer=l2_regularizer
dense_layer():进行矩阵乘法
loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)