监督机器学习:是什么,以及带例子的算法
什么是监督机器学习?
监督机器学习是一种从带标签的训练数据中学习,以帮助您预测未知数据的输出的算法。在监督学习中,您使用“已标记”的数据来训练机器。这意味着一些数据已经用正确答案进行了标记。它可以类比于在有监督者或老师存在的情况下进行学习。
成功构建、扩展和部署准确的监督机器学习模型需要一支由技术精湛的数据科学家组成的团队花费时间和技术专业知识。此外,数据科学家必须重建模型,以确保其提供的见解在数据发生变化之前一直保持准确。
监督学习如何工作
监督机器学习使用训练数据集来实现期望的结果。这些数据集包含输入和正确的输出,有助于模型更快地学习。例如,您想训练一台机器来帮助您预测从工作场所开车回家需要多长时间。
在这里,您将从创建一组带标签的数据开始。这些数据包括
- 天气状况
- 一天中的时间
- 节假日
所有这些细节都是您在此监督学习示例中的输入。输出是该特定日期开车回家所花费的时间。

您凭直觉就知道,如果外面在下雨,开车回家会花更长的时间。但是机器需要数据和统计数据。
让我们来看一些监督学习的例子,说明如何开发此示例的监督学习模型,以帮助用户确定通勤时间。您需要做的第一件事是创建一个训练集。此训练集将包含总通勤时间和相应的因素,如天气、时间等。基于此训练集,您的机器可能会发现降雨量与您回家所需时间之间存在直接关系。
因此,它确定下雨越多,您回家开车的时间就越长。它还可能发现您离开工作的时间与您上路的时间之间的联系。
您越接近下午6点,回家所需的时间就越长。您的机器可能会根据您的带标签数据找到一些关系。
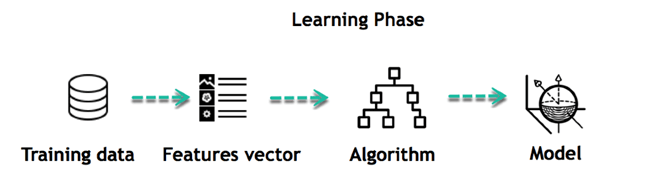
这是您的数据模型的开始。它开始影响雨水如何影响人们的驾驶方式。它还开始发现一天中特定时间段内出行的人数更多。
监督机器学习算法的类型
以下是监督机器学习算法的类型
回归测试
回归技术使用训练数据来预测单个输出值。
示例:您可以使用回归来根据训练数据预测房价。输入变量将是地段、房屋大小等。
优点:输出始终具有概率解释,并且可以对算法进行正则化以避免过拟合。
缺点:当存在多个或非线性决策边界时,逻辑回归的表现可能不佳。此方法不够灵活,因此无法捕捉更复杂的关系。
逻辑回归
逻辑回归方法用于根据给定的一组自变量来估计离散值。它通过将数据拟合到 Logit 函数来帮助您预测事件发生的概率。因此,它也称为逻辑回归。由于它预测概率,因此其输出值介于 0 和 1 之间。
以下是一些回归算法的类型
分类
分类是指将输出分组到类中。如果算法尝试将输入标记到两个不同的类中,则称为二元分类。选择两个以上的类称为多类分类。
示例:确定某人是否会成为贷款违约者。
优点:分类树在实践中表现非常好
缺点:不受约束的个体树容易过拟合。
以下是一些分类算法的类型
朴素贝叶斯分类器
朴素贝叶斯模型(NBN)易于构建,对于大型数据集非常有用。此方法由一个父节点和几个子节点的直接无环图组成。它假定与父节点分离的子节点之间是独立的。
决策树
决策树通过根据实例的特征值对其进行排序来进行分类。在此方法中,每个节点是实例的特征。应进行分类,并且每个分支代表节点可以假设的值。它是分类的一种广泛使用的技术。在此方法中,分类是称为决策树的树。
它有助于您估算实际值(购车成本、通话次数、月总销售额等)。
支持向量机
支持向量机(SVM)是一种于 1990 年开发的支持向量机(SVM)。此方法基于 Vap Nik 引入的统计学习理论的结果。
SVM 机也与核函数密切相关,核函数是大多数学习任务的核心概念。核框架和 SVM 用于各种领域。它包括多媒体信息检索、生物信息学和模式识别。
监督与无监督机器学习技术
| 基于 | 监督机器学习技术 | 无监督机器学习技术 |
|---|---|---|
| 输入数据 | 算法使用有标签数据进行训练。 | 算法用于对未标记数据 |
| 计算复杂度 | 监督学习是一种更简单的方法。 | 无监督学习计算复杂。 |
| 准确性 | 高度准确且可靠的方法。 | 准确性和可靠性较低的方法。 |
监督机器学习中的挑战
以下是监督机器学习中面临的挑战
- 训练数据中存在的无关输入特征可能导致不准确的结果
- 数据准备和预处理始终是一个挑战。
- 当将不可能、不太可能和不完整的值作为训练数据输入时,准确性会受到影响
- 如果相关专家不可用,则另一种方法是“蛮力”。这意味着您需要考虑用于训练机器的正确特征(输入变量)。这可能不准确。
监督学习的优点
以下是监督机器学习的优点
- 机器学习中的监督学习允许您从之前的经验中收集数据或生成数据输出
- 帮助您通过经验优化性能标准
- 监督机器学习可以帮助您解决各种现实世界的计算问题。
监督学习的缺点
以下是监督机器学习的缺点
- 如果您的训练集没有您想要包含在类别中的示例,则决策边界可能会过拟合
- 您需要在训练分类器时从每个类别中选择大量好的示例。
- 对大数据进行分类可能是一个真正的挑战。
- 监督学习的训练需要大量的计算时间。
监督学习的最佳实践
- 在做任何事情之前,您需要决定使用哪种类型的数据作为训练集
- 您需要决定学习函数和学习算法的结构。
- 从人类专家或测量中收集相应的输出
摘要
- 在监督学习算法中,您使用“已标记”的数据来训练机器。
- 您想训练一台机器,帮助您预测从工作场所开车回家需要多长时间,这是监督学习的一个例子。
- 回归和分类是监督机器学习算法的两个维度。
- 监督学习是一种更简单的方法,而无监督学习是一种更复杂的方法。
- 监督学习中最大的挑战是训练数据中存在的无关输入特征可能导致不准确的结果。
- 监督学习的主要优点是它允许您从先前的经验中收集数据或生成数据输出。
- 此模型的缺点是,如果您的训练集没有您想要在类别中的示例,则决策边界可能会过拟合。
- 作为监督学习的最佳实践,您首先需要决定应将哪种类型的数据用作训练集。