机器学习中的混淆矩阵(附示例)
什么是混淆矩阵?
混淆矩阵是一种用于机器学习分类的性能测量技术。它是一种表格,可以帮助您了解分类模型在已知真实值的一组测试数据上的性能。混淆矩阵这个术语本身很简单,但其相关的术语可能有点令人困惑。这里对这种技术进行了一些简单的解释。
混淆矩阵的四种结果
混淆矩阵通过比较实际类别和预测类别来可视化分类器的准确性。二元混淆矩阵由方格组成
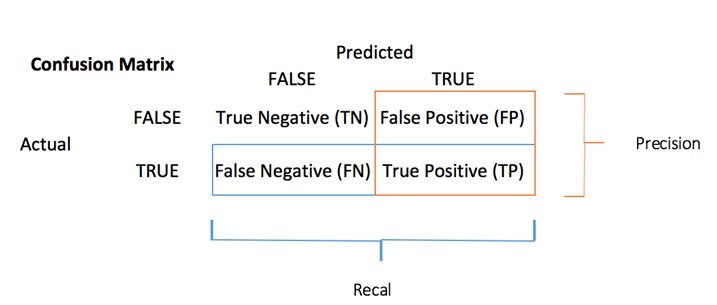
- TP:真正例:预测值为实际正例,且预测正确
- FP:假正例:预测值为实际负例,但被错误地预测为正例。即,负例被预测为正例
- FN:假反例:实际正例,但被错误地预测为负例
- TN:真反例:预测值为实际负例,且预测正确
您可以从混淆矩阵计算准确率测试
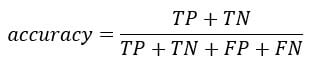
混淆矩阵示例
混淆矩阵是一种有用的机器学习方法,可以测量召回率、精确率、准确率和 AUC-ROC 曲线。下面是一个例子,用于了解真例、真反例、假反例和真反例的术语。
真正例
您预测为正,结果确实是正。例如,您预测法国将赢得世界杯,并且它确实赢了。
真反例
您预测为负,结果确实是负。您预测英格兰不会赢,而它确实输了。
假正例
您的预测为正,但实际上是负。
您预测英格兰会赢,但它输了。
假反例
您的预测为负,但结果实际上是正。
您预测法国不会赢,但它赢了。
您应该记住,我们用“真”或“假”以及“正”或“负”来描述预测值。
如何计算混淆矩阵
以下是使用 数据挖掘 计算混淆矩阵的分步过程
- 步骤 1)首先,您需要使用其预期结果值来测试数据集。
- 步骤 2)预测测试数据集中的所有行。
- 步骤 3)计算预期预测和结果
- 每个类别的正确预测总数。
- 每个类别的错误预测总数。
然后,将这些数字按照以下方法进行组织
- 矩阵的每一行都链接到一个预测的类别。
- 矩阵的每一列都对应一个实际的类别。
- 将正确和错误分类的总计数输入表格。
- 一个类别的正确预测总数计入该类别的预测列和实际行。
- 一个类别的错误预测总数计入该类别的实际行和预测列。
使用混淆矩阵的其他重要术语
- 阳性预测值 (PVV):这非常接近精确率。两者之间的一个重要区别是 PVV 考虑了患病率。在类别完全平衡的情况下,阳性预测值与精确率相同。
- 零错误率:这个术语用于定义如果您预测多数类,您的预测会错多少次。您可以将其视为比较分类器的基线指标。
- F 分数:F1 分数是真阳性(召回率)和精确率的加权平均分数。
- ROC 曲线:ROC 曲线显示了在各种截止点上的真阳性率与假阳性率。它还展示了灵敏度(召回率)和特异性(真反例率)之间的权衡。
- 精确率:精确率指标显示了阳性类的准确性。它衡量阳性类预测正确的可能性。
![]()
当分类器完美地对所有阳性值进行分类时,最高得分为 1。精确率本身不是很有用,因为它忽略了负类。该指标通常与召回率指标配对。召回率也称为灵敏度或真阳性率。
- 灵敏度:灵敏度计算正确检测到的阳性类的比例。此指标显示了模型识别阳性类的好坏程度。
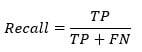
为什么你需要混淆矩阵?
使用混淆矩阵的优点/好处如下。
- 它显示了分类器在进行预测时会感到困惑。
- 混淆矩阵不仅可以让您了解分类器正在犯的错误,还可以了解正在犯的错误的类型。
- 这种细分有助于您克服仅使用分类准确性的局限性。
- 混淆矩阵的每一列代表该预测类别的实例。
- 混淆矩阵的每一行代表实际类别的实例。
- 它不仅提供了对分类器所犯错误的洞察,还提供了所犯错误的类型。