Hadoop & Mapreduce 示例:用 Java 创建第一个程序
在本教程中,您将学习如何使用 Hadoop 和 MapReduce 示例。使用的输入数据是 SalesJan2009.csv。它包含销售相关信息,如产品名称、价格、支付方式、客户所在城市、国家等。目标是**找出每个国家售出的产品数量**。
第一个 Hadoop MapReduce 程序
现在,在这个 MapReduce 教程中,我们将创建第一个 Java MapReduce 程序
确保您已安装 Hadoop。在开始实际过程之前,请将用户更改为“hduser”(Hadoop 配置时使用的 ID,您可以切换到 Hadoop 编程配置期间使用的用户 ID)。
su - hduser_

步骤 1)
创建一个名为MapReduceTutorial的新目录,如下面的 MapReduce 示例所示
sudo mkdir MapReduceTutorial
![]()
设置权限
sudo chmod -R 777 MapReduceTutorial
![]()
SalesMapper.java
package SalesCountry;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesMapper extends MapReduceBase implements Mapper <LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, OutputCollector <Text, IntWritable> output, Reporter reporter) throws IOException {
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
output.collect(new Text(SingleCountryData[7]), one);
}
}
SalesCountryReducer.java
package SalesCountry;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text t_key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
Text key = t_key;
int frequencyForCountry = 0;
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
output.collect(key, new IntWritable(frequencyForCountry));
}
}
SalesCountryDriver.java
package SalesCountry;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class SalesCountryDriver {
public static void main(String[] args) {
JobClient my_client = new JobClient();
// Create a configuration object for the job
JobConf job_conf = new JobConf(SalesCountryDriver.class);
// Set a name of the Job
job_conf.setJobName("SalePerCountry");
// Specify data type of output key and value
job_conf.setOutputKeyClass(Text.class);
job_conf.setOutputValueClass(IntWritable.class);
// Specify names of Mapper and Reducer Class
job_conf.setMapperClass(SalesCountry.SalesMapper.class);
job_conf.setReducerClass(SalesCountry.SalesCountryReducer.class);
// Specify formats of the data type of Input and output
job_conf.setInputFormat(TextInputFormat.class);
job_conf.setOutputFormat(TextOutputFormat.class);
// Set input and output directories using command line arguments,
//arg[0] = name of input directory on HDFS, and arg[1] = name of output directory to be created to store the output file.
FileInputFormat.setInputPaths(job_conf, new Path(args[0]));
FileOutputFormat.setOutputPath(job_conf, new Path(args[1]));
my_client.setConf(job_conf);
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
检查所有这些文件的文件权限
如果缺少“读取”权限,请授予它们 -
![]()
步骤 2)
如以下 Hadoop 示例所示,导出类路径
export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.2.0.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"

步骤 3)
编译 Java 文件(这些文件位于Final-MapReduceHandsOn目录中)。其类文件将被放入包目录
javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java

此警告可以安全地忽略。
此编译将在当前目录中创建一个名为 Java 源文件中指定的包名的目录(在我们的例子中是SalesCountry),并将所有编译后的类文件放入其中。
步骤 4)
创建一个新文件Manifest.txt
sudo gedit Manifest.txt
在其中添加以下行:
Main-Class: SalesCountry.SalesCountryDriver
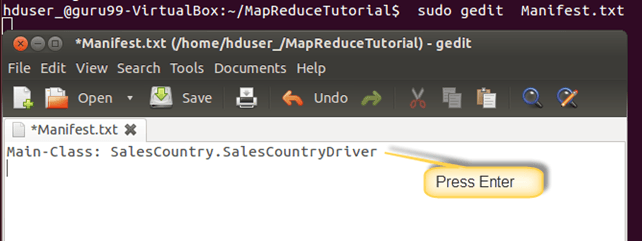
SalesCountry.SalesCountryDriver 是主类的名称。请注意,您必须在此行末尾按 Enter 键。
步骤 5)
创建 Jar 文件
jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class
![]()
检查 jar 文件是否已创建

步骤 6)
启动 Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
步骤7)
将文件SalesJan2009.csv复制到~/inputMapReduce
现在使用以下命令将~/inputMapReduce复制到 HDFS。
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /

此警告可以安全地忽略。
验证文件是否已实际复制。
$HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce

步骤8)
运行 MapReduce 作业
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

这将在 HDFS 上创建一个名为 mapreduce_output_sales 的输出目录。此目录的内容将是一个包含每个国家产品销售情况的文件。
第九步:
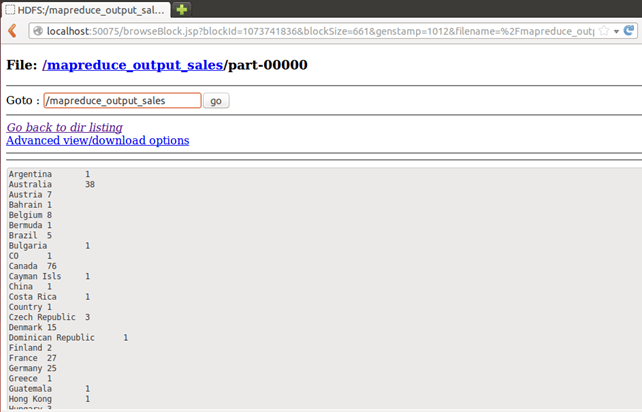
结果可以通过命令行界面看到,如下所示:
$HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
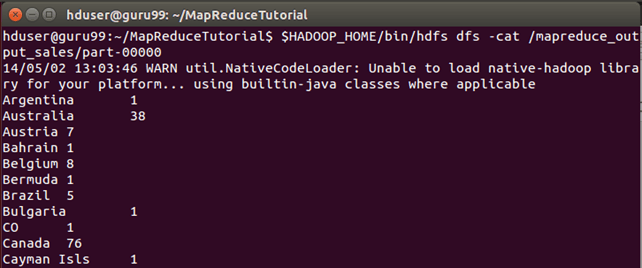
也可以通过 Web 界面看到结果,如下所示:
在浏览器中打开 r。
现在选择“浏览文件系统”并导航到/mapreduce_output_sales
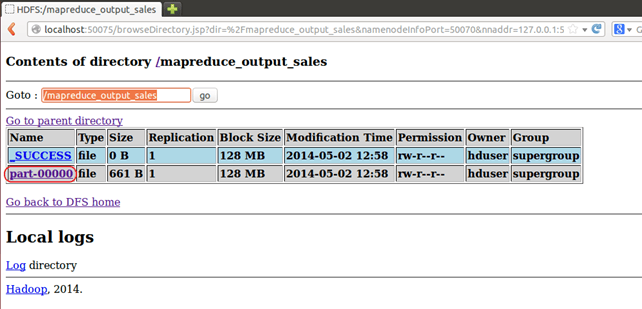
打开part-r-00000
SalesMapper 类解释
在本节中,我们将理解SalesMapper类的实现。
1. 我们首先为我们的类指定一个包名。SalesCountry是我们包的名称。请注意,编译输出SalesMapper.class将进入由此包名命名的目录:SalesCountry。
之后,我们导入库包。
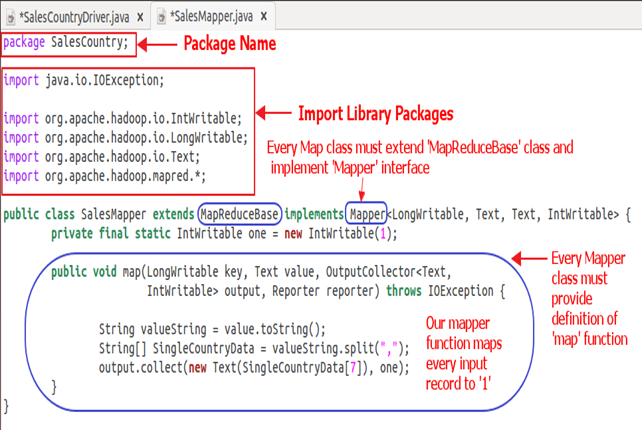
以下快照显示了SalesMapper类的实现 -
示例代码解释
1. SalesMapper 类定义 -
public class SalesMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
每个 mapper 类都必须从MapReduceBase类扩展,并且必须实现Mapper接口。
2. 定义‘map’函数 -
public void map(LongWritable key,
Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
Mapper 类的主要部分是‘map()’方法,它接受四个参数。
每次调用‘map()’方法时,都会传递一个键值对(此代码中的‘key’和‘value’)。
‘map()’方法首先拆分作为参数接收的输入文本。它使用分词器将这些行拆分为单词。
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
这里,‘,’用作分隔符。
之后,使用数组‘SingleCountryData’的第 7 个索引处的记录和值‘1’形成一个对。
output.collect(new Text(SingleCountryData[7]), one);
我们选择第 7 个索引处的记录,因为我们需要国家数据,它位于‘SingleCountryData’数组的第 7 个索引处。
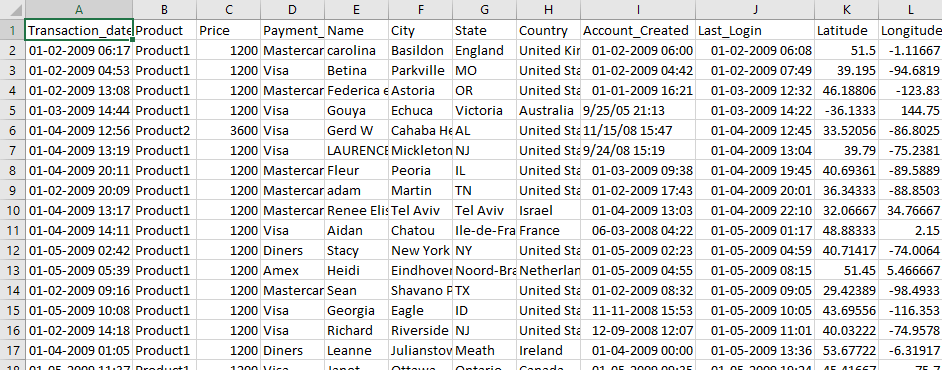
请注意,我们的输入数据格式如下(其中国家位于第 7 位索引,从 0 开始索引) -
交易日期,产品,价格,支付类型,姓名,城市,州,国家,账户创建日期,上次登录,纬度,经度
mapper 的输出再次是键值对,它通过‘OutputCollector’的‘collect()’方法输出。
SalesCountryReducer 类解释
在本节中,我们将理解SalesCountryReducer类的实现。
1. 我们首先为我们的类指定一个包名。SalesCountry是我们包的名称。请注意,编译输出SalesCountryReducer.class将进入由此包名命名的目录:SalesCountry。
之后,我们导入库包。
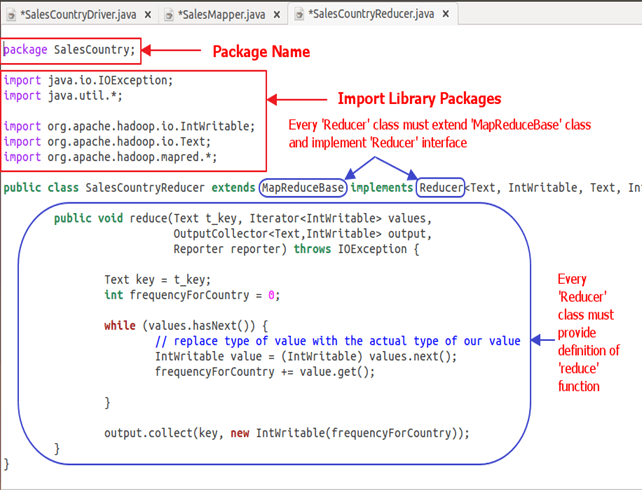
以下快照显示了SalesCountryReducer类的实现 -
代码解释
1. SalesCountryReducer 类定义 -
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
这里,前两个数据类型‘Text’和‘IntWritable’是 reducer 的输入键值的数据类型。
mapper 的输出形式为 <CountryName1, 1>, <CountryName2, 1>。此 mapper 的输出成为 reducer 的输入。因此,为了使其数据类型与此对齐,此处使用Text和IntWritable作为数据类型。
最后两个数据类型‘Text’和‘IntWritable’是 reducer 生成的键值对形式的输出的数据类型。
每个 reducer 类都必须从MapReduceBase类扩展,并且必须实现Reducer接口。
2. 定义‘reduce’函数 -
public void reduce( Text t_key,
Iterator<IntWritable> values,
OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException {
reduce()方法的输入是带有多个值列表的键。
例如,在我们的例子中,它将是 -
<阿拉伯联合酋长国, 1>, <阿拉伯联合酋长国, 1>, <阿拉伯联合酋长国, 1>,<阿拉伯联合酋长国, 1>, <阿拉伯联合酋长国, 1>, <阿拉伯联合酋长国, 1>。
这被提供给 reducer 为<阿拉伯联合酋长国, {1,1,1,1,1,1}>
因此,为了接受这种形式的参数,使用了前两个数据类型,即Text和Iterator<IntWritable>。Text是键的数据类型,Iterator<IntWritable>是该键值的列表的数据类型。
下一个参数是OutputCollector<Text,IntWritable>类型,它收集 reducer 阶段的输出。
reduce()方法首先复制键值并将频率计数初始化为 0。
Text key = t_key;
int frequencyForCountry = 0;
然后,使用‘while’循环,我们遍历与键关联的值列表,并通过对所有值求和来计算最终频率。
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
现在,我们将结果以键和获得的频率计数的形式推送到输出收集器。
以下代码执行此操作 -
output.collect(key, new IntWritable(frequencyForCountry));
SalesCountryDriver 类解释
在本节中,我们将理解SalesCountryDriver类的实现
1. 我们首先为我们的类指定一个包名。SalesCountry是我们包的名称。请注意,编译输出SalesCountryDriver.class将进入由此包名命名的目录:SalesCountry。
这是指定包名的行,后面是导入库包的代码。
2. 定义一个驱动程序类,它将创建一个新的客户端作业、配置对象并声明 Mapper 和 Reducer 类。
驱动程序类负责设置我们的 MapReduce 作业在 Hadoop 中运行。在此类中,我们指定作业名称、输入/输出数据类型以及 mapper 和 reducer 类的名称。
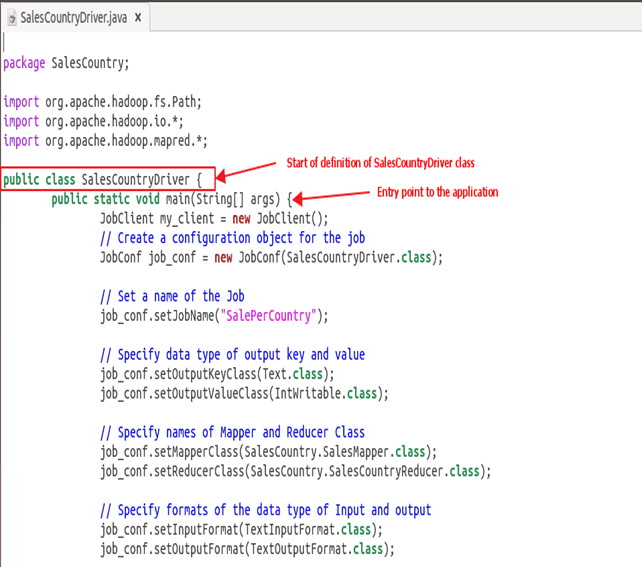
3. 在下面的代码片段中,我们设置了用于消耗输入数据集和生成输出的输入和输出目录。
arg[0] 和 arg[1] 是在 MapReduce 实战中给出的命令行的命令行参数,即:
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

4. 触发我们的作业
以下代码开始执行 MapReduce 作业 -
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}