Hadoop Pig 教程:什么是 Apache Pig?架构、示例
我们将从 Pig 的介绍开始
什么是 Apache Pig?
Pig 是一种高级编程语言,可用于分析大型数据集。Pig 是 Yahoo! 开发的成果。
在 MapReduce 框架中,程序需要被翻译成一系列的 Map 和 Reduce 阶段。然而,这并不是数据分析师熟悉的编程模型。因此,为了弥合这一差距,一个名为 Pig 的抽象被构建在 Hadoop 之上。
Apache Pig 使人们能够更专注于分析大量数据集,而花费更少的时间编写 Map-Reduce 程序。 就像猪什么都吃一样,Apache Pig 编程语言被设计成可以处理任何类型的数据。这就是为什么叫 Pig!

在本入门级 Apache Pig 教程中,您将学到:
Pig 架构
Pig 的架构包含两个组件
-
Pig Latin,这是一种语言
-
运行时环境, 用于运行 PigLatin 程序。
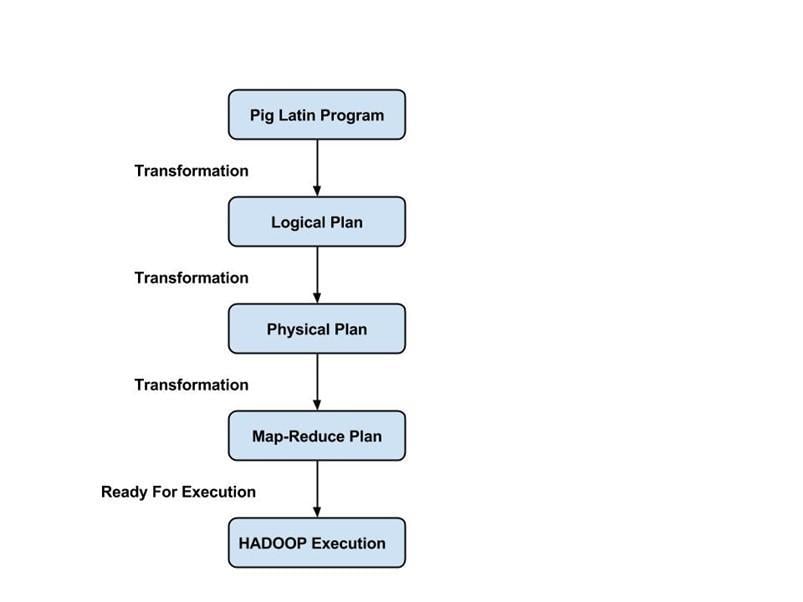
Pig Latin 程序由一系列应用于输入数据以产生输出的操作或转换组成。这些操作描述了一个数据流,该数据流通过 Hadoop Pig 执行环境被转换为可执行的表示形式。底层是这些转换的结果,它们是一系列 MapReduce 作业,程序员对此并不知晓。所以,从某种意义上说,Hadoop 中的 Pig 允许程序员专注于数据,而不是执行的性质。
PigLatin 是一种相对僵化的语言,它使用熟悉的数据处理关键字,例如 Join、Group 和 Filter。
执行模式
Hadoop 中的 Pig 有两种执行模式
-
本地模式:在此模式下,Hadoop Pig 语言在一个 JVM 中运行,并使用本地文件系统。此模式仅适用于使用 Hadoop 中的 Pig 分析小型数据集。
-
Map Reduce 模式:在此模式下,用 Pig Latin 编写的查询被翻译成 MapReduce 作业,并在 Hadoop 集群(集群可以是伪分布或完全分布)上运行。具有完全分布式集群的 MapReduce 模式可用于在大型数据集上运行 Pig。
如何下载和安装 Pig
现在,在本 Apache Pig 教程中,我们将学习如何下载和安装 Pig。
在我们开始实际操作之前,请确保您已安装 Hadoop。切换用户到 'hduser'(Hadoop 配置时使用的 ID,您可以切换到 Hadoop 配置期间使用的用户 ID)。

步骤 1) 从任意一个镜像站点下载 Pig Hadoop 的稳定最新版本,网址如下:
http://pig.apache.org/releases.html
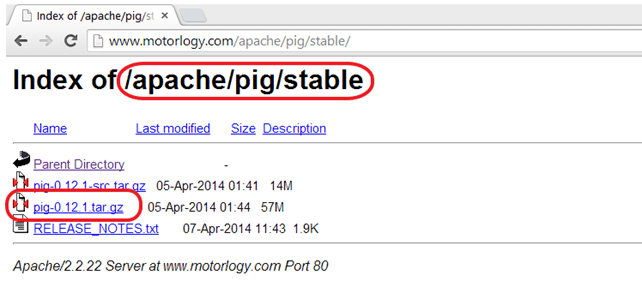
选择 tar.gz (而不是 src.tar.gz)文件下载。
步骤 2) 下载完成后,导航到包含下载的 tar 文件的目录,并将 tar 文件移动到您想要设置 Pig Hadoop 的位置。在这种情况下,我们将移动到 /usr/local。
![]()
移动到包含 Pig Hadoop 文件的目录
cd /usr/local
如下提取 tar 文件的内容
sudo tar -xvf pig-0.12.1.tar.gz
![]()
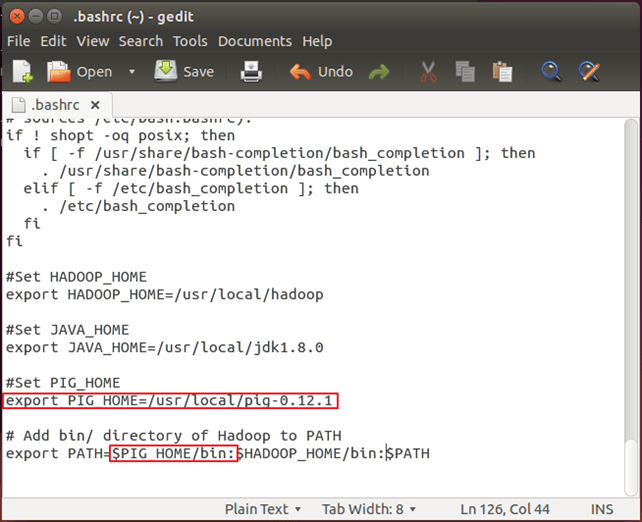
步骤 3) 修改 ~/.bashrc 以添加与 Pig 相关的环境变量。
使用您喜欢的任何文本编辑器打开 ~/.bashrc 文件,并进行以下修改:
export PIG_HOME=<Installation directory of Pig> export PATH=$PIG_HOME/bin:$HADOOP_HOME/bin:$PATH
步骤 4) 现在,使用以下命令源化此环境变量配置。
. ~/.bashrc
![]()
步骤 5)我们需要重新编译 PIG 以支持 Hadoop 2.2.0。
以下是执行此操作的步骤:
转到 PIG 主目录
cd $PIG_HOME
安装 Ant
sudo apt-get install ant

注意:下载将开始,并根据您的互联网速度消耗时间。
重新编译 PIG
sudo ant clean jar-all -Dhadoopversion=23

请注意,在此重新编译过程中会下载多个组件。因此,系统应连接到互联网。
另外,万一此过程卡住,并且您在命令提示符上看不到任何活动超过 20 分钟,则按 Ctrl + c 并重新运行相同的命令。
在本例中,耗时 20 分钟。
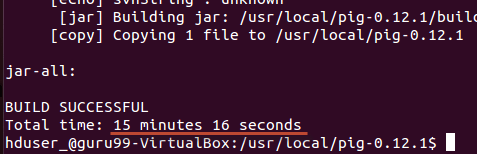
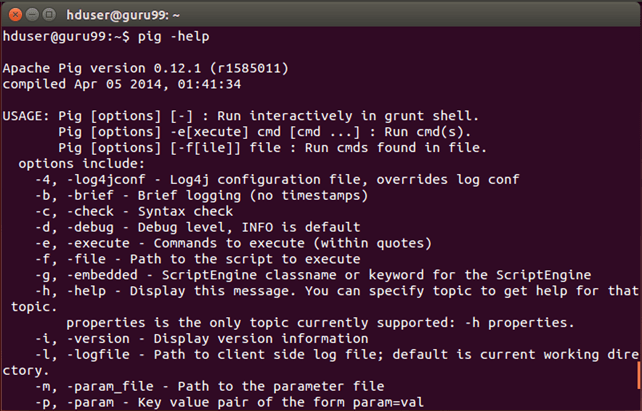
步骤 6) 使用以下命令测试 Pig 安装:
pig -help
Pig 脚本示例
我们将使用 Pig 脚本来查找每个国家销售的产品数量。
输入:我们的输入数据集是一个 CSV 文件,SalesJan2009.csv
步骤 1) 启动 Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
步骤 2) 大数据中的 Pig 在 MapReduce 模式下从 HDFS 获取文件,并将结果存储回 HDFS。
将文件 SalesJan2009.csv(存储在本地文件系统 ~/input/SalesJan2009.csv)复制到 HDFS(Hadoop 分布式文件系统)主目录。
在本 Apache Pig 示例中,文件位于 input 文件夹中。如果文件存储在其他位置,请提供该名称。
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/input/SalesJan2009.csv /

验证文件是否已实际复制。
$HADOOP_HOME/bin/hdfs dfs -ls /
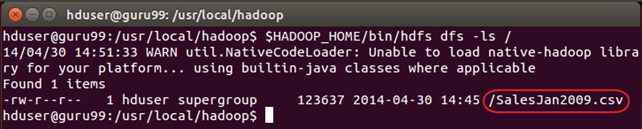
步骤 3) Pig 配置
首先,导航到 $PIG_HOME/conf。
cd $PIG_HOME/conf
sudo cp pig.properties pig.properties.original

使用您喜欢的文本编辑器打开 pig.properties,并使用 pig.logfile 指定日志文件路径。
sudo gedit pig.properties
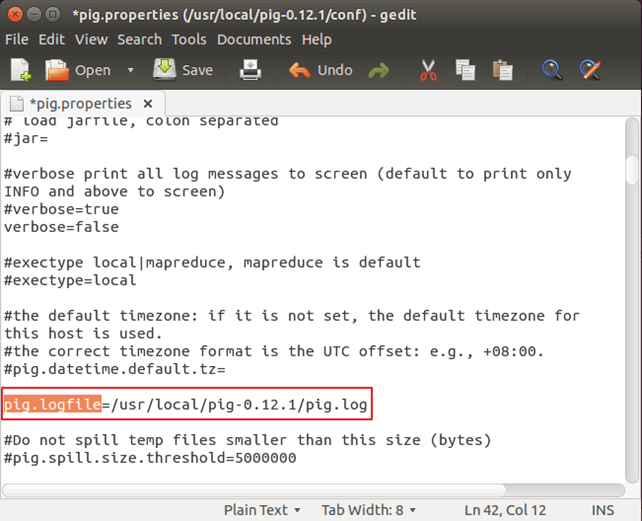
Logger 将使用此文件来记录错误。
步骤 4) 运行命令 'pig',这将启动 Pig 命令行提示符,这是一个交互式 shell,用于运行 Pig 查询。
pig
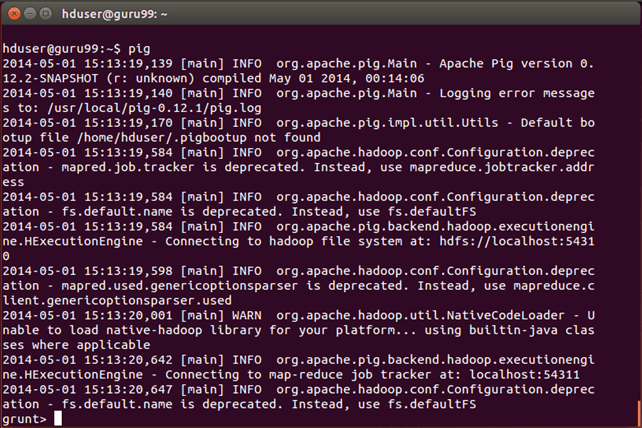
步骤 5)在 Grunt 命令行提示符下,按顺序执行以下 Pig 命令。
— A. 加载包含数据的文件。
salesTable = LOAD '/SalesJan2009.csv' USING PigStorage(',') AS (Transaction_date:chararray,Product:chararray,Price:chararray,Payment_Type:chararray,Name:chararray,City:chararray,State:chararray,Country:chararray,Account_Created:chararray,Last_Login:chararray,Latitude:chararray,Longitude:chararray);
在此命令后按 Enter 键。

— B. 按国家字段对数据进行分组。
GroupByCountry = GROUP salesTable BY Country;

— C. 对于 'GroupByCountry' 中的每个元组,生成如下格式的字符串:-> 国家名称:销售产品数量
CountByCountry = FOREACH GroupByCountry GENERATE CONCAT((chararray)$0,CONCAT(':',(chararray)COUNT($1)));
在此命令后按 Enter 键。

— D. 将数据流的结果存储在 HDFS 上的目录 'pig_output_sales' 中。
STORE CountByCountry INTO 'pig_output_sales' USING PigStorage('\t');

此命令需要一些时间来执行。完成后,您应该会看到以下屏幕。
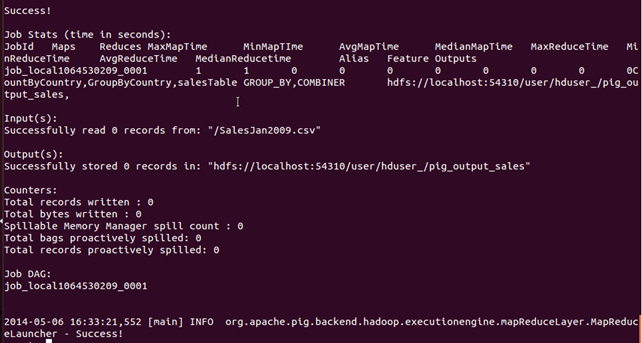
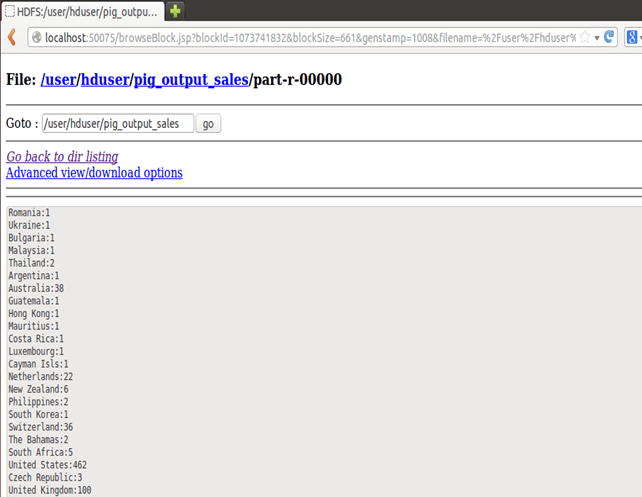
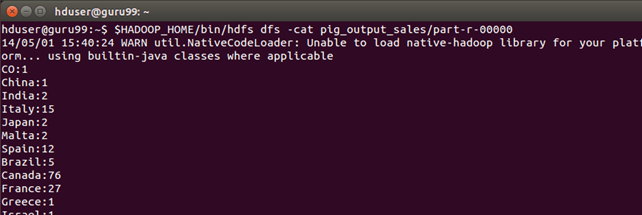
步骤 6) 可以通过命令界面看到结果,如下所示:
$HADOOP_HOME/bin/hdfs dfs -cat pig_output_sales/part-r-00000
也可以通过 Web 界面看到结果,如下所示:
通过 Web 界面显示结果:
在 Web 浏览器中打开 https://:50070/。
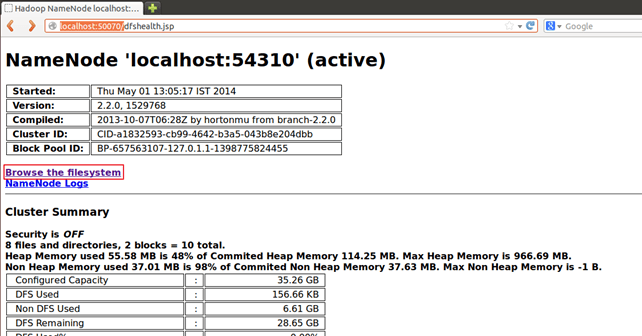
现在选择 “浏览文件系统” 并导航到 /user/hduser/pig_output_sales。
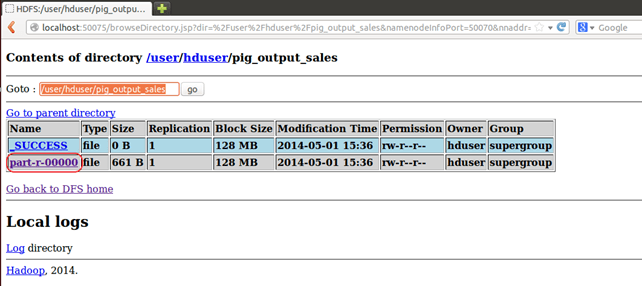
打开part-r-00000