Apache Flume 教程:什么是 Flume、架构及 Hadoop 示例
Hadoop 中的 Apache Flume 是什么?
Apache Flume 是一个可靠的分布式系统,用于收集、聚合和移动海量日志数据。它具有基于流数据流的简单而灵活的架构。Apache Flume 用于收集 Web 服务器日志文件中存在的日志数据,并将其聚合到 HDFS 中进行分析。
Hadoop 中的 Flume 支持多种源,例如:
- “tail”(将数据从本地文件管道传输并通过 Flume 写入 HDFS,类似于 Unix 命令 ‘tail’)
- 系统日志
- Apache log4j(启用 Java 应用程序通过 Flume 将事件写入 HDFS 中的文件)。
Flume 架构
一个 Flume 代理是一个 JVM 进程,它包含 3 个组件——Flume Source、Flume Channel 和 Flume Sink——事件在从外部源启动后通过这些组件传播。
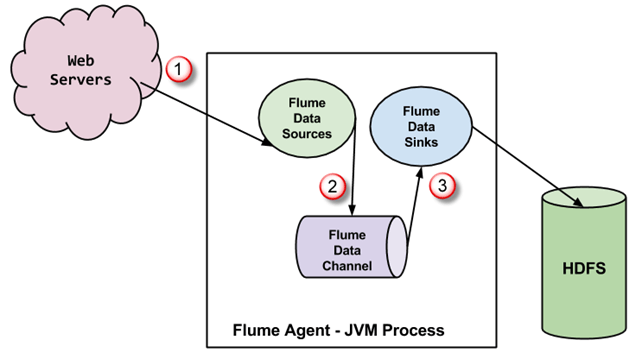
- 在上图中,外部源(WebServer)生成的事件由 Flume Data Source 消费。外部源以目标源能够识别的格式将事件发送到 Flume 源。
- Flume Source 接收事件并将其存储到一个或多个 Channel 中。Channel 作为存储,直到被 Flume Sink 消费。此 Channel 可能使用本地文件系统来存储这些事件。
- Flume Sink 从 Channel 中移除事件,并将其存储到外部存储库(例如 HDFS)中。可能存在多个 Flume 代理,在这种情况下,Flume Sink 会将事件转发到流中下一个 Flume 代理的 Flume 源。
FLUME 的一些重要特性
- Flume 具有基于流数据流的灵活设计。它具有容错性并且健壮,具有多种故障转移和恢复机制。Flume Big Data 提供不同级别的可靠性,包括“尽力而为交付”和“端到端交付”。尽力而为交付不能容忍任何 Flume 节点故障,而“端到端交付”模式可确保即使在多个节点发生故障时也能交付。
- Flume 在源和宿之间传输数据。这些数据的收集可以是计划性的,也可以是事件驱动的。Flume 拥有自己的查询处理引擎,可以轻松地在将每批新数据移动到目标宿之前对其进行转换。
- 可能的 Flume 宿包括 HDFS 和 HBase。Flume Hadoop 还可用于传输事件数据,包括但不限于网络流量数据、社交媒体网站生成的数据以及电子邮件消息。
Flume 库和源代码设置
在开始实际过程之前,请确保已安装 Hadoop。将用户更改为“hduser”(Hadoop 配置期间使用的 ID,您可以切换到 Hadoop 配置期间使用的用户 ID)

步骤 1)创建一个名为“FlumeTutorial”的新目录
sudo mkdir FlumeTutorial
- 赋予读、写和执行权限
sudo chmod -R 777 FlumeTutorial
- 将文件 **MyTwitterSource.java** 和 **MyTwitterSourceForFlume.java** 复制到此目录。
检查所有这些文件的文件权限,如果缺少“读取”权限,则授予该权限 —

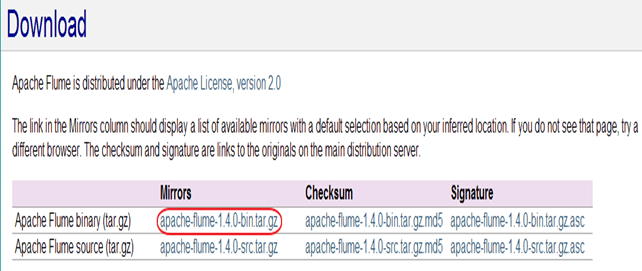
步骤 2)从网站下载“Apache Flume” — https://flume.apache.org/download.html
本 Flume 教程中使用了 Apache Flume 1.4.0。
下一步
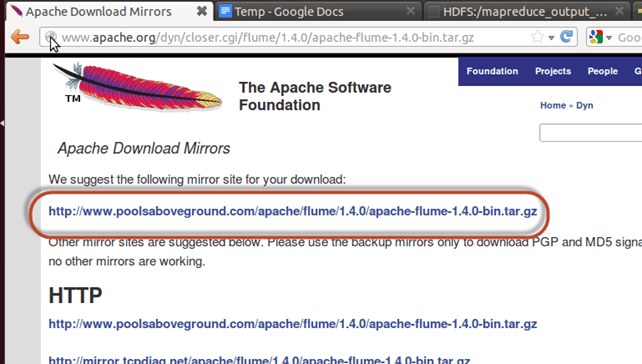
步骤 3)将下载的 tarball 复制到您选择的目录,并使用以下命令解压内容
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

此命令将创建一个名为 **apache-flume-1.4.0-bin** 的新目录并将文件解压到其中。在本文的其余部分,此目录将被称为“
步骤 4)Flume 库设置
将 **twitter4j-core-4.0.1.jar、flume-ng-configuration-1.4.0.jar、flume-ng-core-1.4.0.jar、flume-ng-sdk-1.4.0.jar** 复制到
<Flume 安装目录>/lib/
复制的 JAR 文件可能需要或不需要执行权限。这可能会导致代码编译出现问题。因此,撤销此类 JAR 的执行权限。
在我的例子中,**twitter4j-core-4.0.1.jar** 具有执行权限。我按如下方式撤销了它 —
sudo chmod -x twitter4j-core-4.0.1.jar
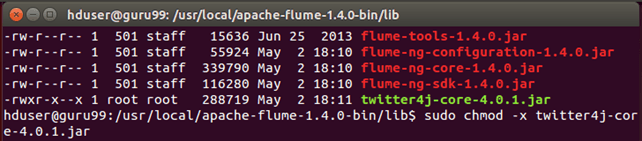
在此命令之后,将“读取”权限授予 **twitter4j-core-4.0.1.jar** 中的所有人。
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
请注意,我已下载 —
– twitter4j-core-4.0.1.jar 来自 https://mvnrepository.com/artifact/org.twitter4j/twitter4j-core
–所有 Flume JAR,即 **flume-ng-*-1.4.0.jar** 来自 http://mvnrepository.com/artifact/org.apache.flume
使用 Flume 从 Twitter 加载数据
步骤 1)转到包含源代码文件的目录。
步骤 2)将 **CLASSPATH** 设置为包含 **<Flume 安装目录>/lib/*** 和 **~/FlumeTutorial/flume/mytwittersource/***
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

步骤 3)使用命令编译源代码 —
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

步骤 4)创建一个 jar
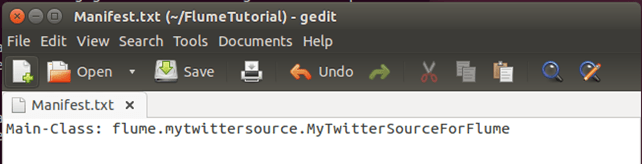
首先,使用您选择的文本编辑器创建一个 **Manifest.txt** 文件,并在其中添加以下行 —
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
... 这里 **flume.mytwittersource.MyTwitterSourceForFlume** 是主类的名称。请注意,您必须在该行末尾按 Enter 键。
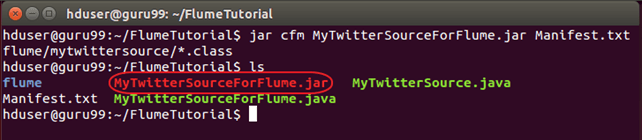
现在,按如下方式创建 JAR‘**MyTwitterSourceForFlume.jar**’ —
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class
步骤 5)将此 jar 复制到 **<Flume 安装目录>/lib/**
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

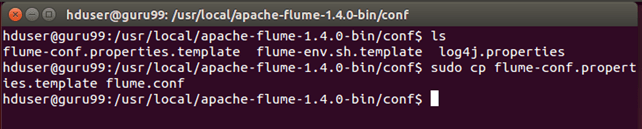
步骤 6)转到 Flume 的配置目录 **<Flume 安装目录>/conf**
如果 flume.conf 不存在,则复制 flume-conf.properties.template 并将其重命名为 flume.conf
sudo cp flume-conf.properties.template flume.conf
如果 **flume-env.sh** 不存在,则复制 **flume-env.sh.template** 并将其重命名为 **flume-env.sh**
sudo cp flume-env.sh.template flume-env.sh

创建 Twitter 应用程序
步骤 1)通过登录 https://developer.twitter.com/ 创建 Twitter 应用程序
步骤 2)转到“我的应用程序”(当单击右上角的“Egg”按钮时,此选项会下拉)
步骤 3)通过单击“创建新应用程序”来创建新应用程序
步骤 4)通过指定应用程序名称、描述和网站来填写应用程序详细信息。您可以参考每个输入框下方的说明。
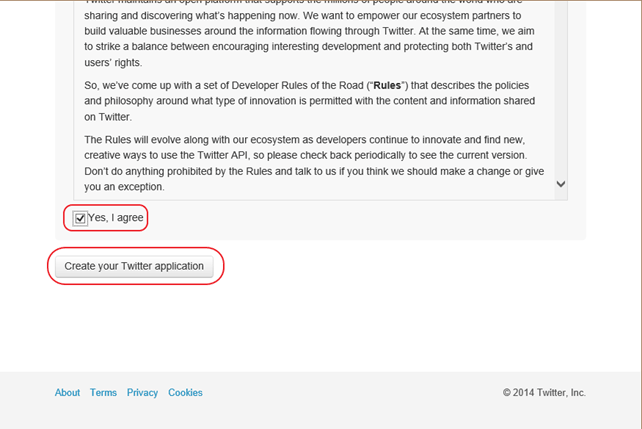
步骤 5)向下滚动页面,通过勾选“是的,我同意”来接受条款,然后单击“创建您的 Twitter 应用程序”按钮
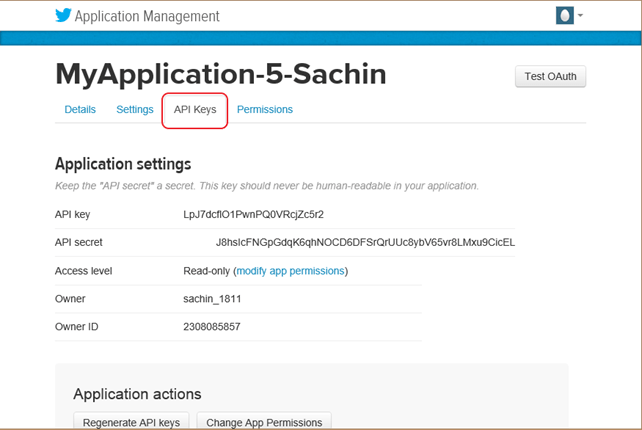
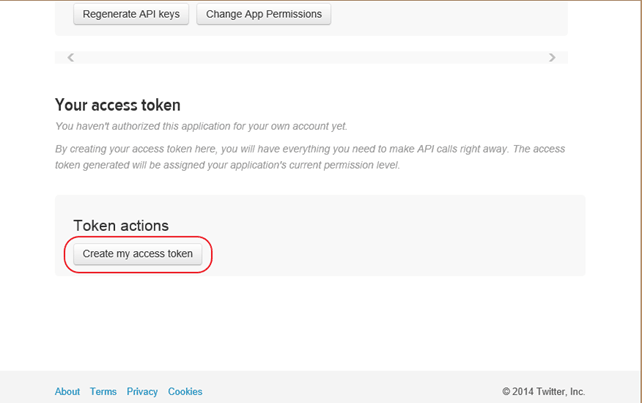
步骤 6)在新创建的应用程序窗口中,转到“API 密钥”选项卡,向下滚动页面,然后单击“创建我的访问令牌”按钮
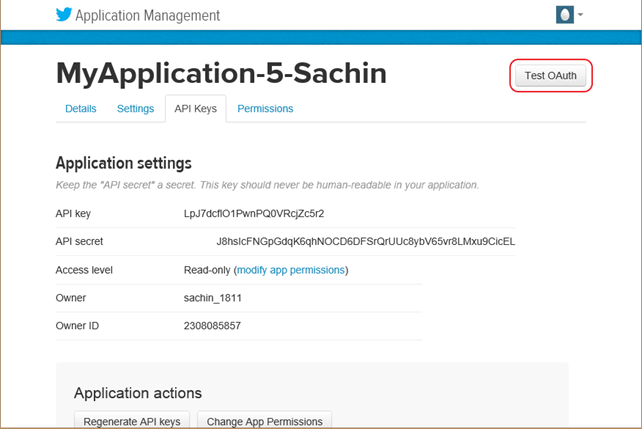
步骤 7)刷新页面。
步骤 8)单击“测试 OAuth”。这将显示应用程序的“OAuth”设置。
步骤 9)修改“flume.conf”,使用这些 OAuth 设置。修改“flume.conf”的步骤如下。
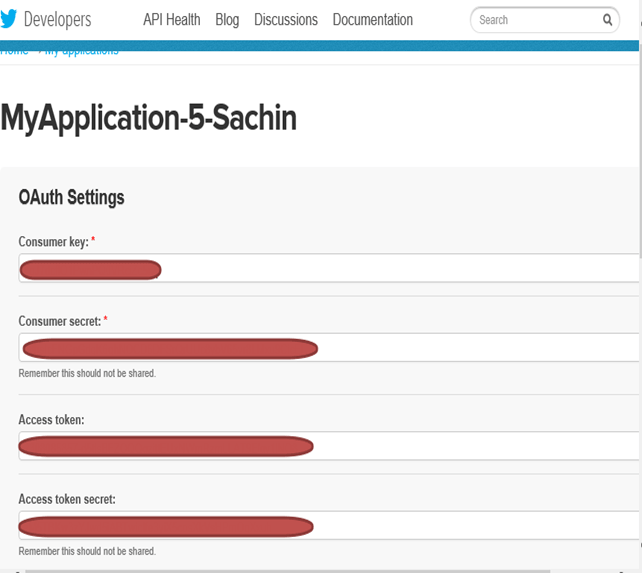
我们需要复制 Consumer key、Consumer secret、Access token 和 Access token secret 来更新 ‘flume.conf’。
注意:这些值属于用户,因此是机密的,不应共享。
修改 ‘flume.conf’ 文件
步骤 1)以写入模式打开‘flume.conf’并为以下参数设置值 —
sudo gedit flume.conf
复制以下内容 —
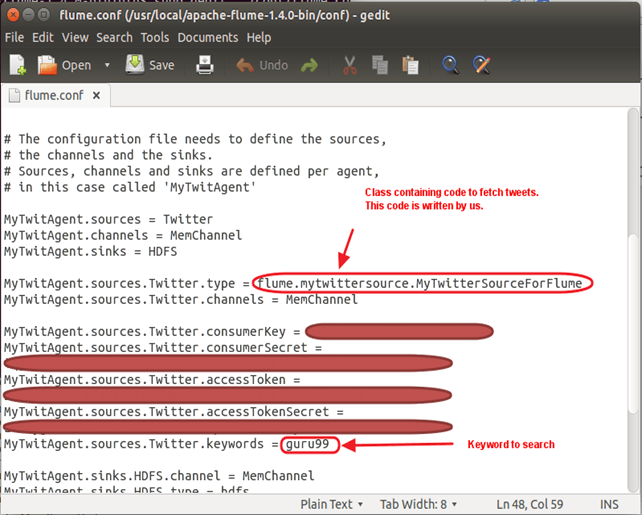
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000
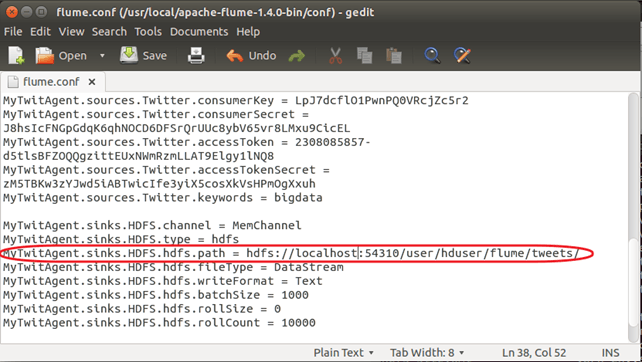
步骤 2)另外,将 **TwitterAgent.sinks.HDFS.hdfs.path** 设置为如下所示:
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://<主机名>:<端口号>/<HDFS 主目录>/flume/tweets/
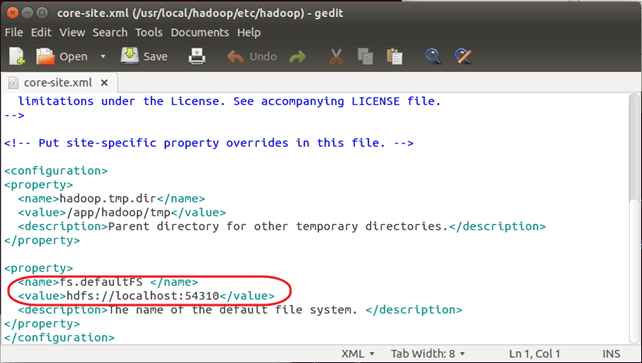
要了解<主机名>、<端口号>和<HDFS 主目录>,请查看 $HADOOP_HOME/etc/hadoop/core-site.xml 中设置的‘fs.defaultFS’参数值。
步骤 3)为了在数据到达时将其刷新到 HDFS,请删除以下条目(如果存在):
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
示例:使用 Flume 流式传输 Twitter 数据
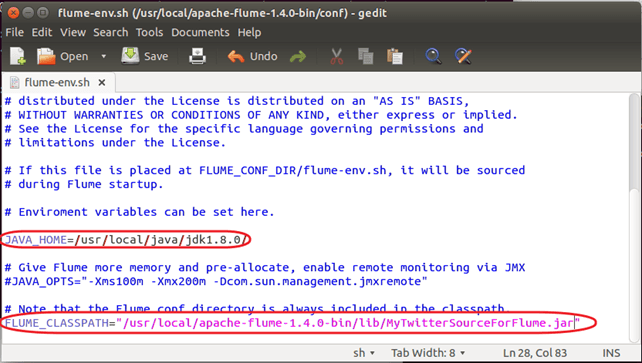
步骤 1)以写入模式打开‘flume-env.sh’并为以下参数设置值 —
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"
步骤 2)启动 Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
步骤 3)Flume tarball 中的两个 JAR 文件与 Hadoop 2.2.0 不兼容。因此,在此 Apache Flume 示例中,我们需要遵循以下步骤使 Flume 与 Hadoop 2.2.0 兼容。
a.将 **protobuf-java-2.4.1.jar** 移出‘<Flume 安装目录>/lib’。
转到‘<Flume 安装目录>/lib’
cd <Flume 安装目录>/lib
sudo mv protobuf-java-2.4.1.jar ~/

b.查找 JAR 文件 ‘guava’ 如下 —
find . -name "guava*"

将 **guava-10.0.1.jar** 移出‘<Flume 安装目录>/lib’。
sudo mv guava-10.0.1.jar ~/

c.从 http://mvnrepository.com/artifact/com.google.guava/guava/17.0 下载 **guava-17.0.jar**
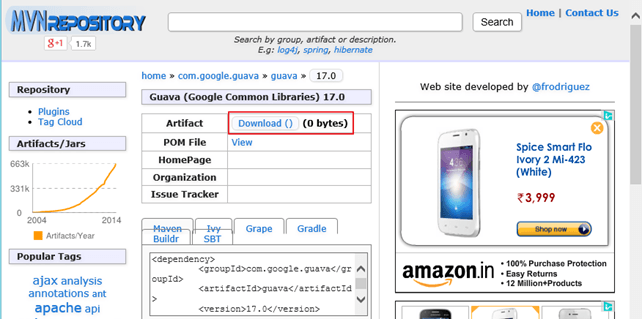
现在,将此下载的 jar 文件复制到‘<Flume 安装目录>/lib’
步骤 4)转到‘<Flume 安装目录>/bin’并按如下方式启动 Flume —
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

Flume 正在获取 Tweets 的命令提示窗口 —
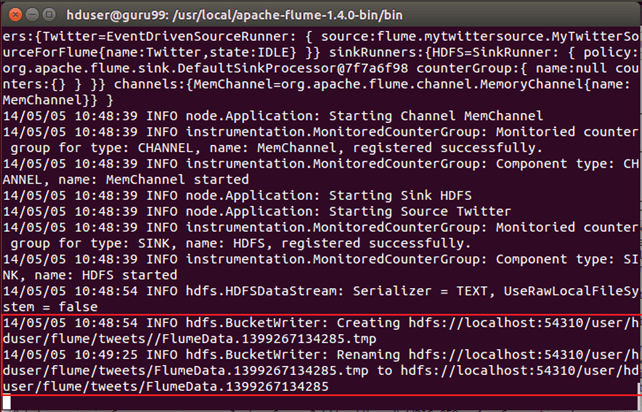
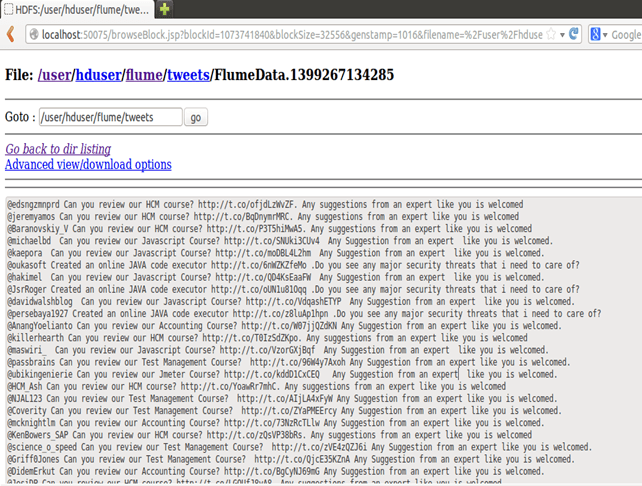
从命令行消息中,我们可以看到输出已写入 **/user/hduser/flume/tweets/ **目录。
现在,使用 Web 浏览器打开此目录。
步骤 5)要通过浏览器查看数据加载结果,请打开 **https://:50070/** 并浏览文件系统,然后转到数据已加载的目录,即 —
<HDFS 主目录>/flume/tweets/