HBase 架构:用例、组件和数据模型
HBase 架构及其重要组件
HBase 架构主要由四个组件构成
- HMaster
- HRegionserver
- HRegions
- Zookeeper
- HDFS
下面是 HBase 的详细架构及其组件
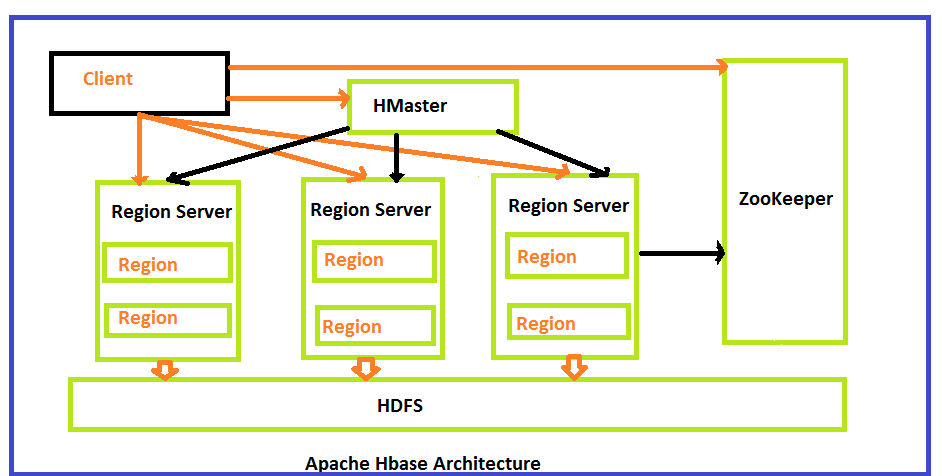
HMaster
HBase 中的 **HMaster** 是 HBase 架构中 Master 服务器的实现。它充当监控代理,监控集群中存在的所有 Region Server 实例,并充当所有元数据更改的接口。在分布式集群环境中,Master 运行在 NameNode 上。Master 运行多个后台线程。
以下是 HMaster 在 HBase 中执行的重要角色。
- 在性能和维护集群节点方面发挥着至关重要的作用。
- HMaster 提供管理员性能,并将服务分发给不同的 region servers。
- HMaster 为 region servers 分配 regions。
- HMaster 具有控制负载均衡和故障转移的功能,以处理集群中节点的负载。
- 当客户端想要更改任何 schema 和进行任何元数据操作时,HMaster 负责这些操作。
HMaster 接口暴露的某些方法主要是面向元数据的。
- 表(创建表、删除表、启用、禁用)
- 列族(添加列、修改列)
- Region(移动、分配)
客户端与 HMaster 和 ZooKeeper 进行双向通信。对于读写操作,它直接联系 HRegion servers。HMaster 为 region servers 分配 regions,并检查 region servers 的健康状况。
在整个架构中,我们有多个 region servers。Region servers 中的 Hlog 将存储所有日志文件。
HBase Region Servers
当 HBase Region Server 接收到来自客户端的写入和读取请求时,它会将请求分配给一个特定的 region,该 region 实际存储了列族。然而,客户端可以直接与 HRegion servers 联系,客户端不需要 HMaster 的强制许可来与 HRegion servers 进行通信。当需要进行与元数据和 schema 相关的操作时,客户端需要 HMaster 的帮助。
HRegionServer 是 Region Server 的实现。它负责服务和管理分布式集群中存在的 regions 或数据。Region servers 运行在 Hadoop 集群的 Data Nodes 上。
HMaster 可以与多个 HRegion servers 联系并执行以下功能。
- 托管和管理 regions
- 自动拆分 regions
- 处理读写请求
- 直接与客户端通信
HBase Regions
HRegions 是 HBase 集群的基本构建单元,它们包含表的分布,并由 Column families 组成。它包含多个 stores,每个 Column family 一个。它主要由两个组件组成:Memstore 和 Hfile。
ZooKeeper
HBase Zookeeper 是一个集中式监控服务器,负责维护配置信息并提供分布式同步。分布式同步是为了访问跨集群运行的分布式应用程序,并负责在节点之间提供协调服务。如果客户端想要与 regions 通信,服务器的客户端必须首先联系 ZooKeeper。
它是一个开源项目,提供了许多重要的服务。
ZooKeeper 提供的服务
- 维护配置信息
- 提供分布式同步
- 建立客户端与 region servers 的通信
- 提供表示不同 region servers 的临时节点
- Master 服务器使用临时节点来发现集群中可用的服务器
- 跟踪服务器故障和网络分区
Master 和 HBase slave 节点(region servers)向 ZooKeeper 注册。客户端需要访问 ZK(zookeeper)仲裁配置才能连接 master 和 region servers。
在 HBase 集群中存在的节点发生故障时,ZK quorum 会触发错误消息,并开始修复故障节点。
HDFS
HDFS 是一个 Hadoop 分布式文件系统,顾名思义,它为存储提供了分布式环境,并且是一个设计为在普通硬件上运行的文件系统。它将每个文件存储在多个块中,为了保持容错能力,这些块会在 Hadoop 集群中复制。
HDFS 提供了高度的容错能力,并在廉价的普通硬件上运行。通过向集群添加节点并利用廉价的普通硬件进行处理和存储,与现有系统相比,它能为客户带来更好的结果。
在这里,每个块中存储的数据会复制到 3 个节点,任何一个节点发生故障都不会丢失数据,它将具有适当的备份恢复机制。
**HDFS** 与 HBase 组件联系,并以分布式方式存储大量数据。
HBase 数据模型
**HBase 数据模型** 是一组组件,包括表、行、列族、单元格、列和版本。HBase 表包含列族和行,其中元素由主键定义。HBase 数据模型表中的列代表对象的属性。
HBase 数据模型包含以下元素,
- 一组表
- 每个表都包含列族和行
- 每个表都必须有一个定义为主键的元素。
- Row key 在 HBase 中充当主键。
- 对 HBase 表的任何访问都使用此主键
- HBase 中的每个列都表示对象对应的属性
HBase 用例
以下是 HBase 用例的示例,其中详细解释了它为各种技术问题提供的解决方案
| 问题陈述 | 解决方案 |
|---|---|
电信行业面临以下技术挑战
|
HBase 用于存储数十亿条详细通话记录。如果每个月向现有 RDBMS 数据库添加 20TB 数据,性能将会下降。为了处理此用例中的大量数据,HBase 是最佳解决方案。HBase 执行快速查询并显示记录。 |
| 银行业每天生成数百万条记录。此外,银行业还需要一个可以检测欺诈性金钱交易的分析解决方案 | 为了存储、处理和更新海量数据并执行分析,理想的解决方案是 – HBase 与多个 Hadoop 生态系统组件集成。 |
此外,HBase 还可以用于
- 当需要编写大量应用程序时。
- 执行在线日志分析并生成合规性报告。
HBase 中的存储机制
HBase 是一个面向列的数据库,数据存储在表中。表按 RowId 排序。如下所示,HBase 具有 RowId,它是表中存在的多个列族的集合。
模式中存在的列族是键值对。如果我们仔细观察,每个列族都有多个列。列值存储在磁盘内存中。表中的每个单元格都有自己的元数据,如时间戳和其他信息。

关于 HBase,以下是代表表模式的关键术语
- 表:行的集合。
- 行:列族的集合。
- 列族:列的集合。
- 列:键值对的集合。
- 命名空间:表的逻辑分组。
- 单元格:{行、列、版本}元组精确指定了 HBase 中的一个单元格定义。
面向列与面向行的存储
面向列和面向行的存储在存储机制上有所不同。众所周知,传统的关系模型以基于行的格式存储数据,即以数据行的形式存储。面向列的存储以列和列族的形式存储数据表。
下表给出了一些这两种存储之间的关键差异
| 面向列的数据库 | 面向行的数据库 |
|---|---|
| 当需要进行处理和分析时,我们使用此方法。例如,联机分析处理 (Online Analytical Processing) 及其应用程序。 | 联机事务处理 (Online Transactional process),例如银行和金融领域使用此方法。 |
| 此模型可以存储海量数据,达到 PB 级别 | 它设计用于少量行和列。 |
HBase 读写数据详解
客户端到 Hfile 的读写操作可以通过下图显示。
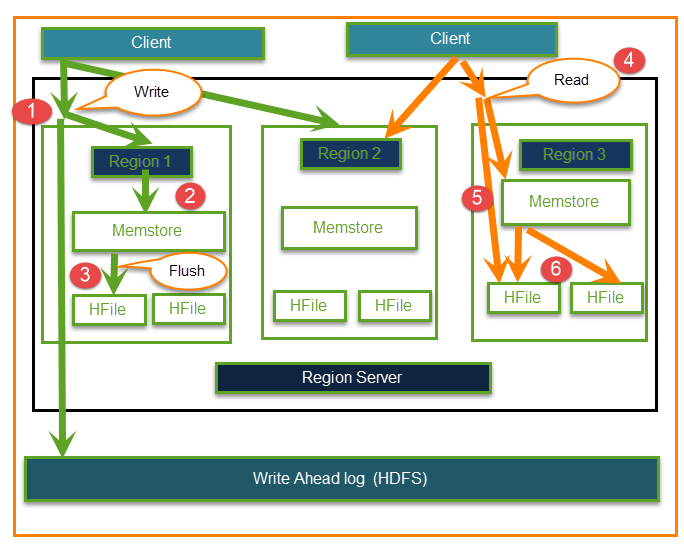
步骤 1) 客户端要写入数据,首先与 Regions server 通信,然后与 regions 通信
步骤 2) Regions 联系 memstore 以存储与 column family 相关的项
步骤 3) 数据首先存储在 Memstore 中,数据被排序,然后刷新到 HFile。使用 Memstore 的主要原因是基于 Row Key 将数据存储在分布式文件系统中。Memstore 位于 Region server 的主内存中,而 HFiles 则写入 HDFS。
步骤 4) 客户端要从 Regions 读取数据
步骤 5) 反过来,客户端可以直接访问 Memstore,并可以请求数据。
步骤 6) 客户端联系 HFiles 以获取数据。数据由客户端提取。
Memstore 包含对 store 的内存修改。HBase Regions 中的对象层次结构如下表所示,从上到下。
| 表 | HBase 集群中存在的 HBase 表 |
| Region | 表中存在的 HRegions |
| 存储 | 它为表中的每个 region 存储每个 ColumnFamily 的数据 |
| Memstore |
|
| StoreFile | 表中每个 region 的每个 store 的 StoreFiles |
| Block | StoreFiles 中的 Blocks |
HBase 与 HDFS 对比
HBase 运行在 HDFS 和 Hadoop 之上。HDFS 和 HBase 之间的一些关键区别在于数据操作和处理方面。
| HBASE | HDFS |
|---|---|
| 低延迟操作 | 高延迟操作 |
| 随机读写 | 一次写入,多次读取 |
| 通过 shell 命令、Java 客户端 API、REST、Avro 或 Thrift 访问 | 主要通过 MR (Map Reduce) 作业访问 |
| 可以执行存储和处理 | 仅用于存储区域 |
一些典型的 IT 行业应用将 HBase 操作与 Hadoop 一起使用。例如,股票交易所数据、网上银行数据操作和处理,HBase 是最适合的解决方案方法。
摘要
- HBase 架构组件:HMaster、HRegion Server、HRegions、ZooKeeper、HDFS
- HBase 中的 HMaster 是 HBase 架构中 Master 服务器的实现。
- 当 HBase Region Server 接收到来自客户端的写入和读取请求时,它会将请求分配给一个特定的 region,该 region 实际存储了列族
- HRegions 是 HBase 集群的基本构建元素,它们包含表的分布,并由 Column families 组成。
- HBase Zookeeper 是一个集中式监控服务器,负责维护配置信息并提供分布式同步。
- HDFS 提供了高度的容错能力,并在廉价的普通硬件上运行。
- HBase 数据模型是一组组件,包括表、行、列族、单元格、列和版本。
- 面向列和面向行的存储在存储机制上有所不同。