HBase Shell 命令示例
在HBase成功安装在Hadoop之上后,我们可以获得一个交互式shell来执行各种命令并执行多项操作。使用这些命令,我们可以对数据表执行多项操作,这些操作可以提供更好的数据存储效率和灵活的客户端交互。
我们可以通过两种方式与HBase进行交互:
- HBase交互式shell模式和
- 通过Java API
在HBase中,交互式shell模式用于与HBase进行表操作、表管理和数据建模。通过使用 Java API模型,我们可以执行HBase中的所有类型表和数据操作。我们可以通过这两种方式与HBase进行交互。
这两种方式的唯一区别在于Java API使用java代码连接HBase,而shell模式使用shell命令连接HBase。
在我们继续之前,快速回顾一下HBase:
- HBase使用 Hadoop 文件作为存储系统来存储大量数据。HBase由Master服务器和Region服务器组成。
- 将要存储在HBase中的数据将以区域(regions)的形式存在。此外,这些区域将被分割并存储在多个区域服务器中。
- 这个shell命令允许程序员通过完整的shell模式交互来定义表模式和数据操作。
- 我们使用的任何命令都将在HBase数据模型中得到反映。
- 我们在操作系统脚本解释器(如Bash shell)中使用HBase shell命令。
- Bash shell是大多数 Linux 和 Unix 操作系统发行版的默认命令解释器。
- HBase的高级版本提供了类似jruby的面向对象的引用表的shell命令。
- 表引用变量可用于在HBase shell模式下执行数据操作。
例如,
- 在本教程中,我们创建了一个表,其中“education”代表表名,对应于列名“guru99”。
- 在某些命令中,“guru99”本身代表表名。
通用命令
在Hbase中,通用命令分为以下几类:
- 状态
- 版本
- Table_help(scan, drop, get, put, disable等)
- Whoami
要进入HBase shell命令,首先,我们需要执行如下代码:

hbase Shell
一旦我们进入HBase shell,我们就可以执行下面提到的所有shell命令。借助这些命令,我们可以在HBase shell模式下执行所有类型的表操作。
让我们逐一通过示例查看所有这些命令及其用法。
状态
Syntax:status
此命令将提供有关系统状态的详细信息,例如集群中的服务器数量、活动服务器数量和平均负载值。您还可以根据您想了解的系统详细程度传递任何特定的参数。参数可以是“summary”、“simple”或“detailed”,默认参数是“summary”。
下面我们展示了如何为status命令传递不同的参数。
如果我们观察下面的屏幕截图,我们将获得更好的理解。
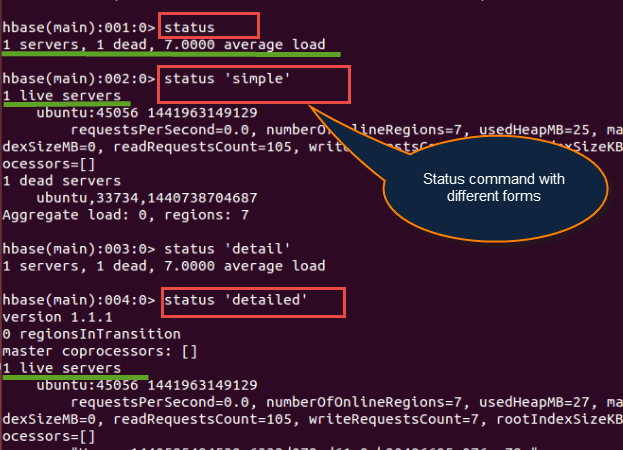
hbase(main):001:0>status hbase(main):002:0>status 'simple' hbase(main):003:0>status 'summary' hbase(main):004:0> status 'detailed'
当我们执行status命令时,它会提供有关服务器数量、死服务器和服务器平均负载的信息。此处的屏幕截图显示了信息,例如:1个活动服务器,1个死服务器,和7.0000平均负载。
版本
Syntax: version
![]()
- 此命令将在命令模式下显示当前使用的HBase版本。
- 如果您运行version命令,它将如上所示给出输出。
表帮助
Syntax:table_help
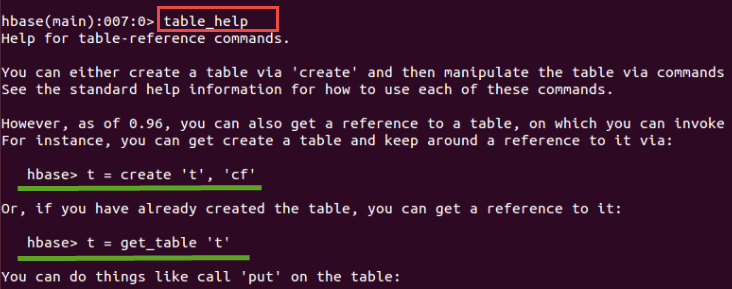
此命令提供指导
- 如何使用表引用命令
- 它将提供不同的HBase shell命令用法及其语法。
- 上面的屏幕截图显示了“create”和“get_table”命令的语法及其用法。一旦在HBase中创建了表,我们就可以通过这些命令来操作它。
- 它将提供put、get等表操作命令和其他命令的信息。
whoami
语法
Syntax: Whoami

此“whoami”命令用于从HBase集群返回当前HBase用户信息。
它将提供以下信息:
- HBase中的组
- 用户信息,例如在此案例中“hduser”代表用户名,如屏幕截图所示。
TTL(生存时间)–属性
在HBase中,列族可以设置为以秒为单位的时间值,使用TTL。HBase将在过期时间到达后自动删除行。此属性适用于行的所有版本,甚至包括当前版本。
HBase中为行编码的TTL时间以UTC指定。此属性与表管理命令一起使用。
TTL处理和列族TTL之间的重要区别如下:
- 单元格TTL以毫秒为单位,而不是秒。
- 单元格TTL不能将单元格的有效生命周期延长到列族级别TTL设置之外。
表管理命令
这些命令将允许程序员创建带有行和列族的表及表模式。
以下是表管理命令:
- 创建
- 列表
- 描述
- 禁用
- 全部禁用
- 启用
- 全部启用
- 删除
- 全部删除
- 显示过滤器
- 修改
- 修改状态
让我们通过示例查看HBase中的各种命令用法。
创建
Syntax: create <tablename>, <columnfamilyname>
![]()
示例:-
hbase(main):001:0> create 'education' ,'guru99' 0 rows(s) in 0.312 seconds =>Hbase::Table – education
上面的示例解释了如何在HBase中创建一个具有指定名称的表,该名称根据字典或列族的规范给出。除此之外,我们还可以传递一些表范围的属性。
为了检查“education”表是否已创建,我们需要使用下面提到的“list”命令。
列表
Syntax:list
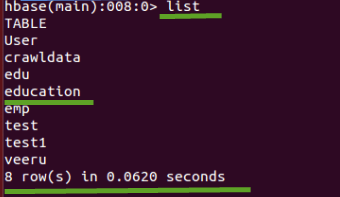
- “List”命令将显示HBase中存在或已创建的所有表。
- 上面屏幕截图所示的输出目前显示了HBase中存在的表。
- 此屏幕截图显示HBase中总共有8个表。
- 我们可以通过传递可选的正则表达式参数来过滤表的输出值。
描述
Syntax:describe <table name>

hbase(main):010:0>describe 'education'
此命令描述了命名表。
- 它将提供有关表中存在的列族的更多信息。
- 在我们的例子中,它提供了关于表“education”的描述。
- 它将提供关于表名、列族、关联过滤器、版本等更多信息。
禁用
Syntax: disable <tablename>
![]()
hbase(main):011:0>disable 'education'
- 此命令将开始禁用指定表。
- 如果需要删除或丢弃表,必须先禁用它。
在上面的屏幕截图中,我们正在禁用education表。
全部禁用
Syntax: disable_all<"matching regex"
- 此命令将禁用与给定正则表达式匹配的所有表。
- 实现与delete命令相同(除了添加用于匹配的正则表达式)。
- 一旦表被禁用,用户就可以从HBase中删除表。
- 在删除或丢弃表之前,必须先禁用它。
启用
Syntax: enable <tablename>

hbase(main):012:0>enable 'education'
- 此命令将开始启用指定表。
- 对于任何已禁用的表,要恢复到其先前的状态,我们使用此命令。
- 如果表最初被禁用但未被删除或丢弃,并且我们想重新使用已禁用的表,那么我们必须使用此命令启用它。
- 在上面的屏幕截图中,我们正在启用“education”表。
显示过滤器
Syntax: show_filters

此命令显示HBase中存在的所有过滤器,例如ColumnPrefix Filter、TimestampsFilter、PageFilter、FamilyFilter等。
删除
Syntax:drop <table name>

hbase(main):017:0>drop 'education'
我们必须注意以下关于drop命令的要点:
- 要删除HBase中存在的表,我们必须先禁用它。
- 要删除HBase中存在的表,我们必须先禁用它。
- 因此,无论是要删除还是丢弃表,首先都应该使用disable命令禁用该表。
- 在上面的屏幕截图中,我们正在删除“education”表。
- 在执行此命令之前,必须禁用“education”表。
全部删除
Syntax: drop_all<"regex">
- 此命令将删除与给定正则表达式匹配的所有表。
- 在执行此命令之前,必须使用disable_all禁用表。
- 与正则表达式匹配的表将从HBase中删除。
是否已启用
Syntax: is_enabled 'education'
此命令将验证指定表是否已启用。通常,“enable”和“is_enabled”命令的操作之间存在一些混淆,我们在此澄清。
- 假设一个表被禁用,要使用该表,我们必须使用enable命令启用它。
- is_enabled命令将检查表是否已启用。
修改
Syntax: alter <tablename>, NAME=><column familyname>, VERSIONS=>5
此命令修改列族模式。为了理解它确切的作用,我们在这里用一个例子进行了解释。
示例
在这些示例中,我们将对表及其列执行alter命令操作。我们将执行以下操作:
- 修改单个、多个列族名称
- 从表中删除列族名称
- 使用表范围属性执行其他一些操作。
- 要更改或添加表“education”中的“guru99_1”列族,将其最大单元格版本数设置为5,
- “education”是之前创建的表名,列名为“guru99”。
- 在这里,借助alter命令,我们正试图将列族模式从guru99更改为guru99_1。
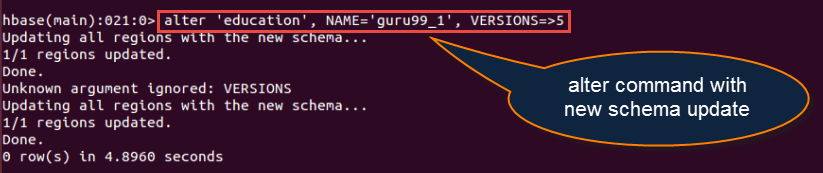
hbase> alter 'education', NAME='guru99_1', VERSIONS=>5
- 您也可以在多个列族上操作alter命令。例如,我们将为现有表“education”定义两个新列。
hbase> alter 'edu', 'guru99_1', {NAME => 'guru99_2', IN_MEMORY => true}, {NAME => 'guru99_3', VERSIONS => 5}
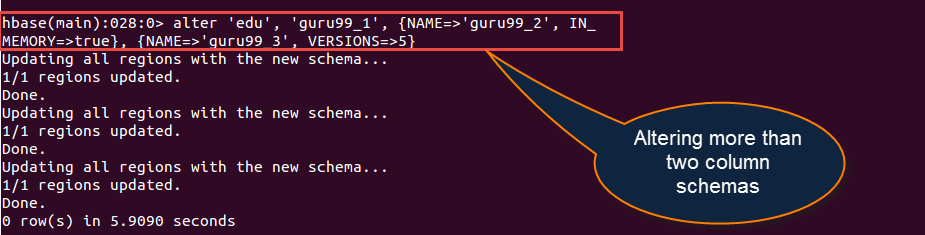
- 我们可以使用此命令一次更改多个列模式。
- 如上面屏幕截图所示,guru99_2和guru99_3是为education表定义的两个新列名。
- 我们可以在上一个屏幕截图中看到使用此命令的方式。
- 在此步骤中,我们将看到如何从表中删除列族。要删除表“education”中的“f1”列族。
使用以下命令之一:
hbase> alter 'education', NAME => 'f1', METHOD => 'delete'
hbase> alter 'education', 'delete' =>' guru99_1'
- 在此命令中,我们试图删除在第一步中创建的列空间名guru99_1。

- 如下面的屏幕截图所示,它显示了两个步骤——如何更改表范围属性以及如何删除表范围属性。
Syntax: alter <'tablename'>, MAX_FILESIZE=>'132545224'

步骤1) 您可以更改表范围属性,如MAX_FILESIZE、READONLY、MEMSTORE_FLUSHSIZE、DEFERRED_LOG_FLUSH等。这些可以放在最后;例如,要将区域的最大大小更改为128MB或任何其他内存值,我们使用此命令。
用途
- 我们可以使用MAX_FILESIZE作为表范围属性,如上所示。
- MAX_FILESIZE中代表的数字是以字节为单位的内存。
注意:MAX_FILESIZE属性表范围由HBase中的一些属性决定。MAX_FILESIZE也属于表范围属性。
步骤2) 您也可以使用table_att_unset方法删除表范围属性。如果您看到命令
alter 'education', METHOD => 'table_att_unset', NAME => 'MAX_FILESIZE'
- 上面的屏幕截图显示了带有范围属性的修改后的表名。
- table_att_unset方法用于取消设置表中存在的属性。
- 第二个实例是取消设置MAX_FILESIZE属性。
- 执行命令后,它将从“education”表中取消设置MAX_FILESIZE属性。
修改状态
Syntax: alter_status 'education'

- 通过此命令,您可以获取alter命令的状态。
- 它指示表中已更新了模式的区域数量,通过传递表名。
- 上面的屏幕截图显示1/1个区域已更新。这意味着它已更新一个区域。之后,如果成功,它将显示“完成”消息。
数据操作命令
这些命令用于表相关的数据操作,例如将数据放入表、从表中检索数据以及删除模式等。
这些命令包括:
- Count (计数)
- Put
- Get
- 删除
- 全部删除
- 截断
- Scan
让我们通过示例了解这些命令的用法。
Count (计数)
Syntax: count <'tablename'>, CACHE =>1000
- 该命令将检索表中行数的计数。此命令返回的值是行数。
- 默认情况下,当前计数每1000行显示一次。
- 计数间隔可以可选指定。
- 默认缓存大小为10行。
- 如果配置了正确的缓存,Count命令将运行得更快。
示例

hbase> count 'guru99', CACHE=>1000
此示例count命令一次从“Guru99”表中获取1000行。
如果表包含更多行,我们可以将缓存设置为较低的值。
但默认情况下,它一次获取一行。
hbase>count 'guru99', INTERVAL => 100000 hbase> count 'guru99', INTERVAL =>10, CACHE=> 1000
假设“Guru99”表有一些表引用,例如g。
我们也可以在表引用上运行count命令,如下所示:
hbase>g.count INTERVAL=>100000 hbase>g.count INTERVAL=>10, CACHE=>1000
Put
Syntax: put <'tablename'>,<'rowname'>,<'columnvalue'>,<'value'>
此命令用于以下事项:
- 它将在指定或定义的表、行或列处放置一个单元格‘value’。
- 它将可选地协调时间戳。
示例
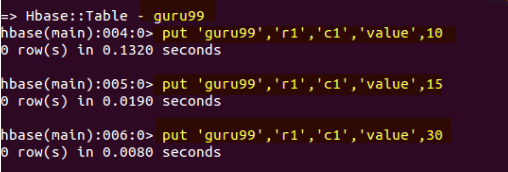
- 我们正在将值放入“guru99”表中的行r1和列c1。
hbase> put 'guru99', 'r1', 'c1', 'value', 10
- 我们已将三个值10、15和30放入“guru99”表中,如下面的屏幕截图所示。
- 假设“Guru99”表具有某些表引用,例如g。我们也可以在表引用上运行命令,例如
hbase> g.put 'guru99', 'r1', 'c1', 'value', 10
- 插入值到“guru99”后,输出将如上屏幕截图所示。
为了检查输入值是否已正确插入到表中,我们使用“scan”命令。在下面的屏幕截图中,我们可以看到值已正确插入。

代码片段:供练习
create 'guru99', {NAME=>'Edu', VERSIONS=>213423443}
put 'guru99', 'r1', 'Edu:c1', 'value', 10
put 'guru99', 'r1', 'Edu:c1', 'value', 15
put 'guru99', 'r1', 'Edu:c1', 'value', 30
从代码片段中,我们正在做以下事情:
- 我们在这里创建了一个名为“guru99”的表,列名为“Edu”。
- 使用“put”命令,我们将值放入“guru99”表中的行r1、列“Edu”。
Get
Syntax: get <'tablename'>, <'rowname'>, {< Additional parameters>}
这里<附加参数>包括TIMERANGE、TIMESTAMP、VERSIONS和FILTERS。
使用此命令,您将获得表中存在的行或单元格内容。此外,您还可以添加其他参数,如TIMESTAMP、TIMERANGE、VERSIONS、FILTERS等,以获取特定的行或单元格内容。

例子:-
hbase> get 'guru99', 'r1', {COLUMN => 'c1'}
对于表“guru99”,行r1和列c1的值将使用此命令显示,如上面屏幕截图所示。
hbase> get 'guru99', 'r1'
对于表“guru99”,行r1的值将使用此命令显示。
hbase> get 'guru99', 'r1', {TIMERANGE => [ts1, ts2]}
对于表“guru99”,行1在时间范围ts1和ts2之间将使用此命令显示。
hbase> get 'guru99', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
对于表“guru99”,行r1和列族c1、c2、c3的值将使用此命令显示。
删除
Syntax:delete <'tablename'>,<'row name'>,<'column name'>
- 此命令将删除指定表中的行或列的单元格值。
- 删除必须精确匹配已删除单元格的坐标。
- 扫描时,delete cell会抑制旧版本的值。

示例
hbase(main):)020:0> delete 'guru99', 'r1', 'c1''.
- 上面的执行将删除表“guru99”中列c1的行r1。
- 假设“guru99”表具有某些表引用,例如g。
- 我们也可以在表引用上运行命令,例如hbase> g.delete ‘guru99’, ‘r1’, ‘c1′”。
deleteall
Syntax: deleteall <'tablename'>, <'rowname'>
![]()
- 此命令将删除给定行中的所有单元格。
- 我们可以选择性地将列名和时间戳添加到语法中。
示例:-
hbase>deleteall 'guru99', 'r1', 'c1'
这将删除表中存在的所有行和列。我们可以选择性地在此处指定列名。
截断
Syntax: truncate <tablename>

截断hbase表后,模式仍然存在,但记录不存在。此命令执行3项功能,如下所述:
- 如果表已存在,则禁用表。
- 如果表已存在,则删除表。
- 重新创建指定的表。
Scan
Syntax: scan <'tablename'>, {Optional parameters}
此命令扫描整个表并显示表内容。
- 我们可以向scan命令传递多个可选的规范,以获取有关系统中存在的表的更多信息。
- Scanner规范可能包含以下一个或多个属性。
- 它们是TIMERANGE、FILTER、TIMESTAMP、LIMIT、MAXLENGTH、COLUMNS、CACHE、STARTROW和STOPROW。
scan 'guru99'
输出如下所示的屏幕截图。

在上面的屏幕截图中:
- 它显示了“guru99”表及其列名和值。
- 它包含单个列值c1的三个行值r1、r2、r3。
- 它显示与行关联的值。
例子:-
scan命令的不同用法。
| 命令 | 用途 |
|---|---|
| scan ‘.META.’, {COLUMNS => ‘info:regioninfo’} | 它显示HBase中表中存在的与列相关的所有元数据信息。 |
| scan ‘guru99’, {COLUMNS => [‘c1’, ‘c2’], LIMIT => 10, STARTROW => ‘xyz’} | 它显示guru99表的内容及其列族c1和c2,将值限制为10。 |
| scan ‘guru99’, {COLUMNS => ‘c1’, TIMERANGE => [1303668804, 1303668904]} | 它显示guru99的内容及其列名c1,以及位于指定时间范围属性值之间显示的值。 |
| scan ‘guru99’, {RAW => true, VERSIONS =>10} | 在此命令中,RAW=>true提供了高级功能,例如显示guru99表中存在的所有单元格值。 |
代码示例
首先创建表并将值放入表中。
create 'guru99', {NAME=>'e', VERSIONS=>2147483647}
put 'guru99', 'r1', 'e:c1', 'value', 10
put 'guru99', 'r1', 'e:c1', 'value', 12
put 'guru99', 'r1', 'e:c1', 'value', 14
delete 'guru99', 'r1', 'e:c1', 11
输入截图
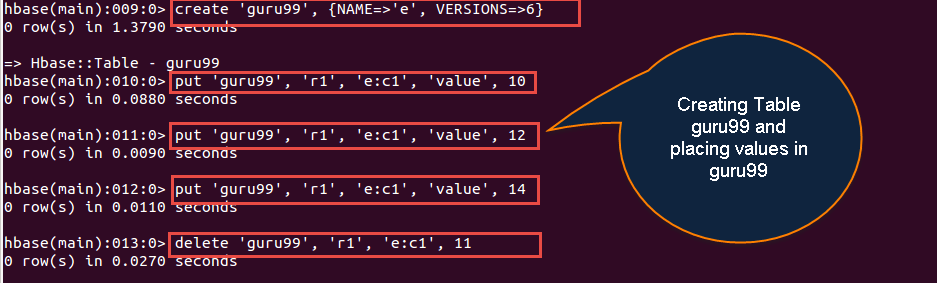
如果我们运行scan命令。
Query: scan 'guru99', {RAW=>true, VERSIONS=>1000}
它将显示如下面的输出。
输出截图
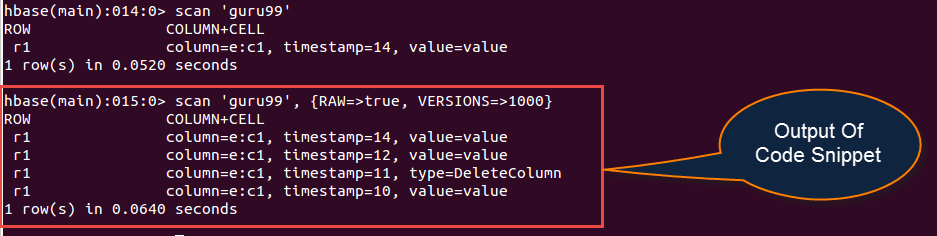
上面屏幕截图所示的输出提供了以下信息:
- 扫描guru99表,属性为RAW=>true, VERSIONS=>1000。
- 显示带有列族和值的行。
- 在第三行,显示的值显示了列中存在的已删除值。
- 它显示的输出是随机的;它不能与我们插入表中的值顺序相同。
集群复制命令
- 这些命令作用于HBase的集群设置模式。
- 通常使用这些命令来添加和删除集群对等节点以及启动和停止复制。
| 命令 | 功能性 |
|---|---|
| add_peer | 添加对等节点到集群进行复制。
hbase> add_peer ‘3’, zk1,zk2,zk3:2182:/hbase-prod |
| remove_peer | 停止定义的复制流。
删除关于对等节点的所有元数据信息。 hbase> remove_peer ‘1’ |
| start_replication | 重新启动所有复制功能。
hbase> start_replication |
| stop_replication | 停止所有复制功能。
hbase>stop_replication |
摘要
HBase shell和通用命令提供了关于不同类型数据操作、表管理和集群复制命令的完整信息。我们可以使用这些命令对HBase中存在的表执行各种功能。