Hadoop MapReduce Join & Counter 示例
Mapreduce 中的 Join 是什么?
Mapreduce Join 操作用于合并两个大型数据集。然而,此过程涉及编写大量代码来执行实际的 Join 操作。加入两个数据集首先从比较每个数据集的大小开始。如果一个数据集比另一个数据集小,那么较小的数据集将被分发到集群中的每个数据节点。
一旦 MapReduce 中的 Join 被分发,Mapper 或 Reducer 将使用较小的数据集来查找大型数据集中的匹配记录,然后合并这些记录以形成输出记录。
Join 的类型
根据实际 Join 的执行位置,Hadoop 中的 Join 分为:
1. Map 端 Join – 当 Join 由 Mapper 执行时,它被称为 Map 端 Join。在这种类型中,Join 在 Map 函数实际消耗数据之前执行。每个 Map 的输入必须是分区形式,并且必须按 Join 键排序。此外,分区数量必须相等,并且必须按 Join 键排序。
2. Reduce 端 Join – 当 Join 由 Reducer 执行时,它被称为 Reduce 端 Join。在这种 Join 中,不需要数据集是结构化的(或分区的)。
在这里,Map 端处理发出 Join 键和两个表的相应元组。作为此处理的结果,具有相同 Join 键的所有元组将落入同一个 Reducer,然后该 Reducer 将具有相同 Join 键的记录进行 Join。
Hadoop 中 Join 的总体处理流程如下图所示。
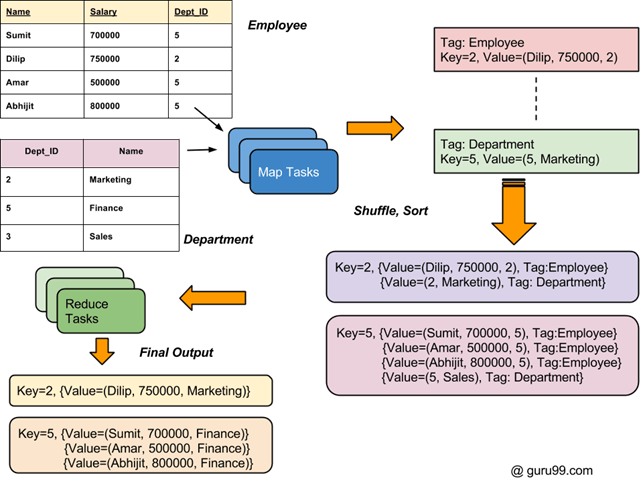
如何连接两个数据集:MapReduce 示例
两个不同文件中有两组数据(如下所示)。键 Dept_ID 在两个文件中都通用。目标是使用 MapReduce Join 合并这些文件
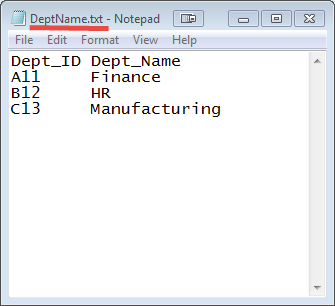
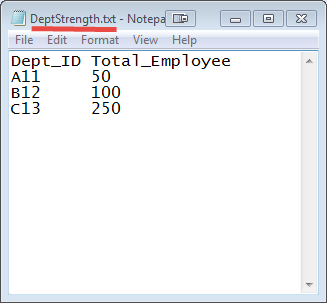
输入:输入数据集是一个 txt 文件,DeptName.txt & DepStrength.txt
确保已安装 Hadoop。在开始实际的 MapReduce Join 示例过程之前,请将用户更改为“hduser”(在 Hadoop 配置过程中使用的 ID,您可以切换到 Hadoop 配置期间使用的用户 ID)。
su - hduser_

步骤 1) 将 zip 文件复制到您选择的位置

步骤 2) 解压 Zip 文件
sudo tar -xvf MapReduceJoin.tar.gz
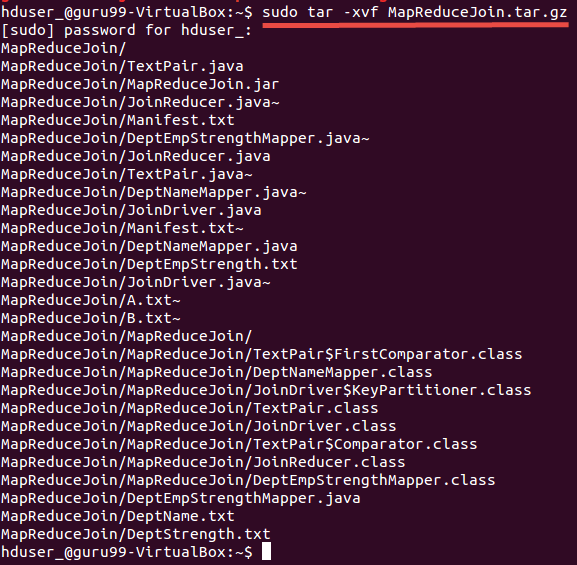
步骤 3) 进入目录 MapReduceJoin/
cd MapReduceJoin/
![]()
步骤 4) 启动 Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
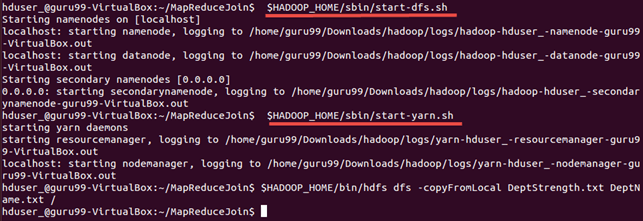
步骤 5) DeptStrength.txt 和 DeptName.txt 是此 MapReduce Join 示例程序使用的输入文件。
需要使用以下命令将这些文件复制到 HDFS:
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /

步骤 6) 使用以下命令运行程序:
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar MapReduceJoin/JoinDriver/DeptStrength.txt /DeptName.txt /output_mapreducejoin
![]()
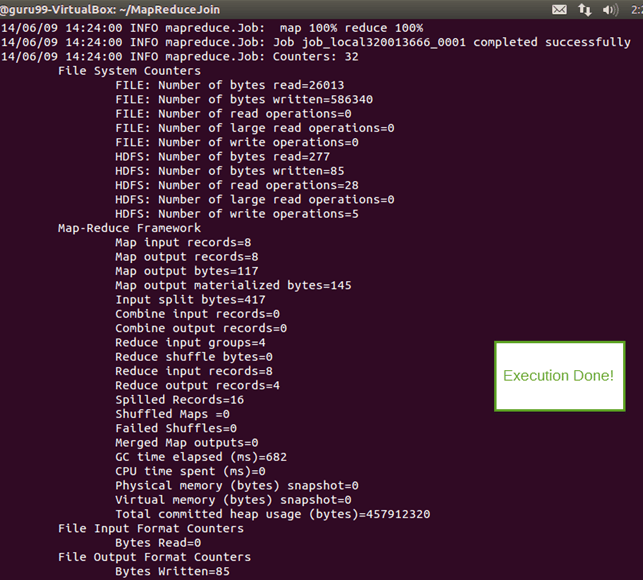
步骤 7) 执行后,输出文件(名为“part-00000”)将存储在 HDFS 中的 /output_mapreducejoin 目录中
可以使用命令行界面查看结果
$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

也可以通过 Web 界面看到结果,如下所示:
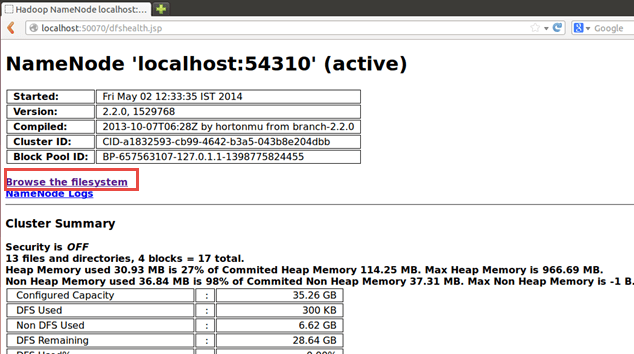
现在选择“浏览文件系统”并导航到/output_mapreducejoin
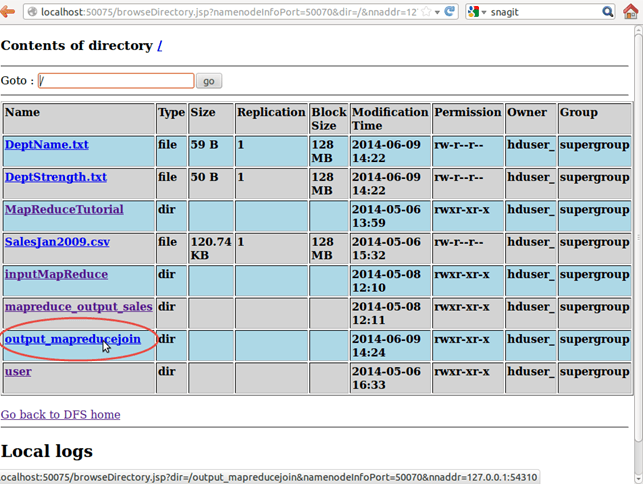
打开part-r-00000
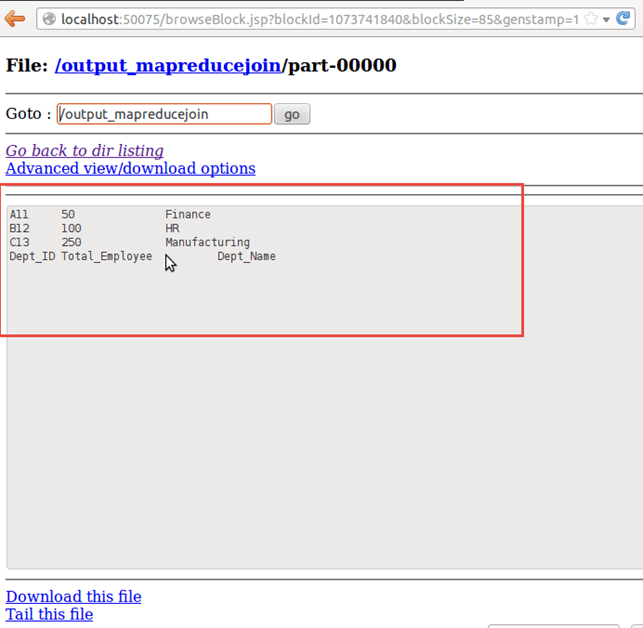
结果显示
注意:请注意,在下次运行此程序之前,您需要删除输出目录 /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
另一种选择是为输出目录使用不同的名称。
MapReduce 中的 Counter 是什么?
MapReduce 中的 Counter 是一种用于收集和度量 MapReduce 作业和事件统计信息的机制。Counter 跟踪 MapReduce 中各种作业统计信息,例如发生的事件数量和事件的进度。Counter 用于 MapReduce 中的问题诊断。
Hadoop Counter 类似于在代码中为 Map 或 Reduce 放置日志消息。这些信息可能有助于诊断 MapReduce 作业处理中的问题。
通常,Hadoop 中的这些 Counter 在程序(Map 或 Reduce)中定义,并在执行期间当发生特定事件或条件(特定于该 Counter)时进行递增。Hadoop Counter 的一个很好的应用是跟踪输入数据集中的有效记录和无效记录。
MapReduce Counter 的类型
基本上有两种类型的 MapReduce Counter
- Hadoop 内置 Counter:每个作业都存在一些内置的 Hadoop Counter。以下是内置 Counter 组:
- MapReduce Task Counters – 在执行期间收集任务特定的信息(例如,输入记录数)。
- FileSystem Counters – 收集任务读取或写入的字节数等信息。
- FileInputFormat Counters – 通过 FileInputFormat 收集读取的字节数信息。
- FileOutputFormat Counters – 通过 FileOutputFormat 收集写入的字节数信息。
- Job Counters – 这些 Counter 由 JobTracker 使用。它们收集的统计信息包括,例如,为作业启动的任务数量。
- 用户定义的 Counter
除了内置 Counter 之外,用户还可以使用 编程语言 提供的类似功能来定义自己的 Counter。例如,在 Java 中,‘enum’ 用于定义用户定义的 Counter。
Counter 示例
一个包含 Counter 以计算缺失值和无效值的 MapClass 示例。本教程中使用的输入数据文件 我们的输入数据集是 CSV 文件,SalesJan2009.csv
public static class MapClass
extends MapReduceBase
implements Mapper<LongWritable, Text, Text, Text>
{
static enum SalesCounters { MISSING, INVALID };
public void map ( LongWritable key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Input string is split using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//Value at 4th index is country. It is stored in 'country' variable
String country = fields[4];
//Value at 8th index is sales data. It is stored in 'sales' variable
String sales = fields[8];
if (country.length() == 0) {
reporter.incrCounter(SalesCounters.MISSING, 1);
} else if (sales.startsWith("\"")) {
reporter.incrCounter(SalesCounters.INVALID, 1);
} else {
output.collect(new Text(country), new Text(sales + ",1"));
}
}
}
上面的代码片段显示了 Hadoop Map Reduce 中 Counter 的示例实现。
在这里,SalesCounters 是使用‘enum’定义的 Counter。它用于计算MISSING和INVALID输入记录。
在代码片段中,如果‘country’字段的长度为零,则表示其值丢失,因此会递增相应的 Counter SalesCounters.MISSING。
接下来,如果‘sales’字段以“开头,则该记录被视为无效。这通过递增 Counter SalesCounters.INVALID来表示。