Hadoop 中的 MapReduce 是什么?大数据架构
Hadoop中的MapReduce是什么?
MapReduce是一个软件框架和编程模型,用于处理海量数据。MapReduce程序分为两个阶段:Map和Reduce。Map任务负责拆分和映射数据,而Reduce任务负责混洗和缩减数据。
Hadoop能够运行用多种语言编写的MapReduce程序:Java、Ruby、Python和C++。云计算中的Map Reduce程序具有并行性,因此非常适合使用集群中的多台机器执行大规模数据分析。
每个阶段的输入都是键值对。此外,每个程序员都需要指定两个函数:map函数和reduce函数。
大数据中MapReduce架构(附示例说明)
整个过程经过四个执行阶段:拆分、映射、混洗和缩减。
在本MapReduce教程中,让我们通过一个MapReduce示例来理解——
假设您的MapReduce在大数据程序中有以下输入数据:
Welcome to Hadoop Class Hadoop is good Hadoop is bad
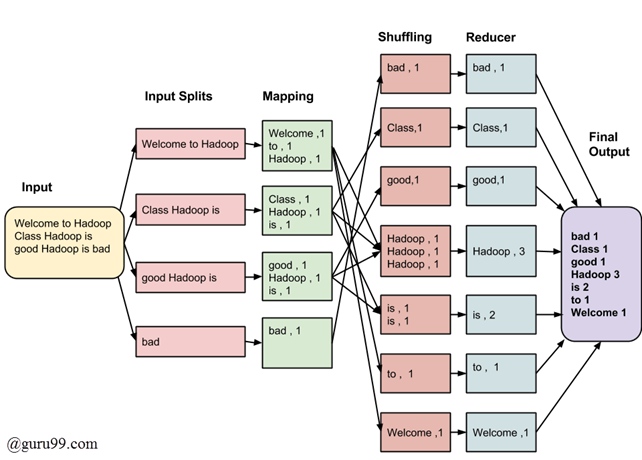
MapReduce任务的最终输出是
| bad | 1 |
| 类 | 1 |
| good | 1 |
| Hadoop | 3 |
| 是 | 2 |
| to | 1 |
| Welcome | 1 |
数据将通过以下MapReduce在大数据中的阶段:
输入拆分
MapReduce在大数据作业中的输入被划分为固定大小的块,称为输入拆分。输入拆分是由单个Map消耗的输入块。输入拆分是MapReduce中用于处理大数据的输入块。
映射
这是Map-Reduce程序执行的第一个阶段。在此阶段,每个拆分中的数据将传递给映射函数以生成输出值。在我们的示例中,映射阶段的任务是计算输入拆分中每个单词的出现次数(下面将提供输入拆分的更多详细信息),并以<单词,频率>的形式准备列表。
混洗
此阶段消耗Map阶段的输出。其任务是从Map阶段的输出中整合相关记录。在我们的示例中,相同的单词及其各自的频率被分组。
缩减
在此阶段,对混洗阶段的输出值进行聚合。此阶段合并来自混洗阶段的值并返回单个输出值。简而言之,此阶段对整个数据集进行摘要。
在我们的示例中,此阶段聚合了来自混洗阶段的值,即计算每个单词的总出现次数。
MapReduce架构详解
- 为每个拆分创建一个Map任务,然后该任务为拆中的每个记录执行map函数。
- 拥有多个拆分总是很有益的,因为处理拆分所需的时间与处理整个输入所需的时间相比很短。当拆分较小时,由于我们并行处理拆分,因此加载平衡的处理效果更好。
- 然而,拆分过小也是不可取的。当拆分过小时,管理拆分和创建Map任务的开销开始主导整个作业执行时间。
- 对于大多数作业,最好将拆分大小设置为与HDFS块大小(默认为64 MB)相同。
- Map任务的执行会将输出写入相应节点上的本地磁盘,而不是HDFS。
- 选择本地磁盘而不是HDFS的原因是避免HDFS存储操作中发生的复制。
- Map输出是中间输出,由Reduce任务处理以生成最终输出。
- 作业完成后,Map输出可以被丢弃。因此,将其存储在带有复制的HDFS中就显得多余了。
- 在节点发生故障时,在Map输出被Reduce任务消耗之前,Hadoop会在另一个节点上重新运行Map任务并重新创建Map输出。
- Reduce任务不遵循数据局部性的概念。每个Map任务的输出都馈送到Reduce任务。Map输出被传输到运行Reduce任务的机器上。
- 在这台机器上,输出被合并,然后传递给用户定义的reduce函数。
- 与Map输出不同,Reduce输出存储在HDFS中(第一个副本存储在本地节点上,其他副本存储在机架外的节点上)。因此,写入Reduce输出
MapReduce如何组织工作?
现在,在本MapReduce教程中,我们将学习MapReduce的工作原理。
Hadoop将作业划分为任务。有两种类型的任务:
- Map任务(拆分和映射)
- Reduce任务(混洗、缩减)
如上所述。
完整的执行过程(Map和Reduce任务的执行)由两种类型的实体控制,称为
- Jobtracker:充当主节点(负责提交作业的完整执行)
- 多个Task Trackers:充当从属节点,每个节点执行作业
对于提交到系统执行的每个作业,都有一个位于Namenode上的Jobtracker,以及位于Datanode上的多个tasktrackers。
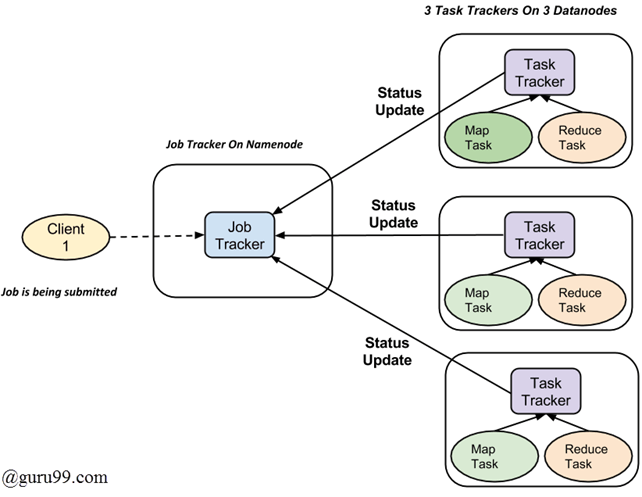
- 一个作业被划分为多个任务,然后这些任务在集群中的多个数据节点上运行。
- Job tracker负责通过调度任务在不同数据节点上运行来协调活动。
- 各个任务的执行由位于每个数据节点上的Task tracker负责,该节点执行作业的一部分。
- Task tracker的职责是向Job tracker发送进度报告。
- 此外,Task tracker会定期向Jobtracker发送“心跳”信号,以通知其系统的当前状态。
- 因此,Job tracker会跟踪每个作业的整体进度。在任务失败的情况下,Job tracker可以在另一个Task tracker上重新调度它。