什么是 Hadoop?介绍、架构、生态系统、组件
什么是Hadoop?
Apache Hadoop 是一个开源软件框架,用于开发在分布式计算环境中执行的数据处理应用程序。
使用HADOOP构建的应用程序运行在分布在商用计算机集群上的大型数据集上。商用计算机价格便宜且易于获得。这些主要有助于以低成本实现更高的计算能力。
与存储在个人计算机系统本地文件系统中的数据类似,在Hadoop中,数据存储在称为Hadoop分布式文件系统的分布式文件系统中。处理模型基于“数据本地化”概念,即将计算逻辑发送到包含数据的集群节点(服务器)。这种计算逻辑不过是使用Java等高级语言编写的程序的一个已编译版本。这样的程序会处理存储在Hadoop HDFS中的数据。
你知道吗?计算机集群由一组多个处理单元(存储磁盘+处理器)组成,这些处理单元相互连接并充当一个系统。
Hadoop生态系统和组件
下图显示了Hadoop生态系统中的各种组件-
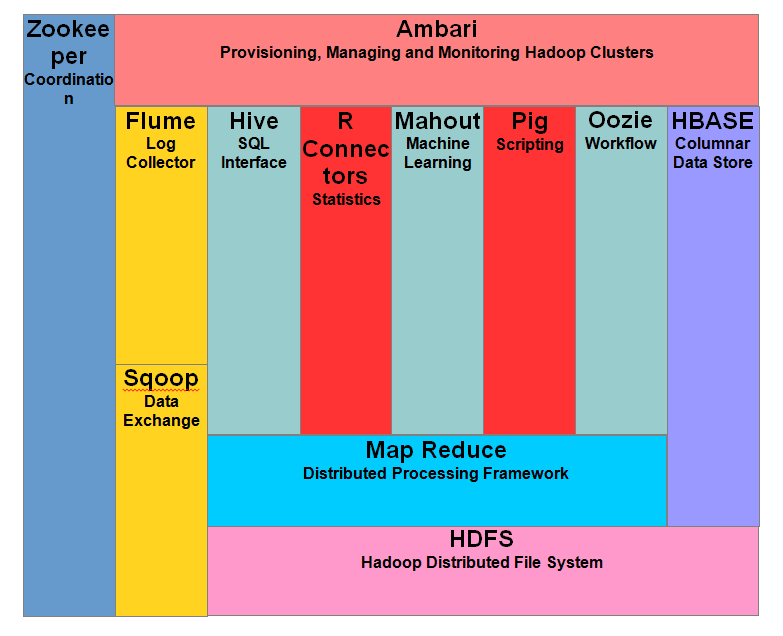
Apache Hadoop包含两个子项目–
- Hadoop MapReduce: MapReduce是一种计算模型和软件框架,用于编写在Hadoop上运行的应用程序。这些MapReduce程序能够在大规模计算节点集群上并行处理海量数据。
- HDFS(Hadoop分布式文件系统):HDFS负责Hadoop应用程序的存储部分。MapReduce应用程序从HDFS消耗数据。HDFS会创建数据块的多个副本,并将它们分发到集群中的计算节点上。这种分发使得可靠且极快的计算成为可能。
尽管Hadoop最出名的是MapReduce及其分布式文件系统HDFS,但该术语也用于一系列相关的项目,这些项目属于分布式计算和大规模数据处理的范畴。Apache的其他Hadoop相关项目包括Hive、HBase、Mahout、Sqoop、Flume和ZooKeeper。
Hadoop架构
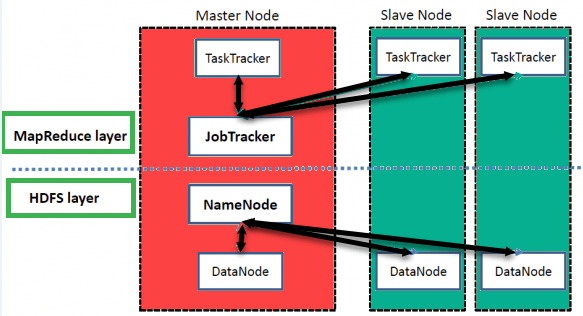
Hadoop采用主从架构进行数据存储和使用MapReduce和HDFS方法进行分布式数据处理。
NameNode
NameNode表示命名空间中使用的每个文件和目录
DataNode
DataNode帮助您管理HDFS节点的状态,并允许您与块进行交互
MasterNode
Master节点允许您使用Hadoop MapReduce进行并行数据处理。
Slave node
Slave节点是Hadoop集群中的附加机器,允许您存储数据以进行复杂的计算。此外,所有slave节点都附带Task Tracker和DataNode。这允许您分别与NameNode和Job Tracker同步进程。
在Hadoop中,主节点或从节点系统可以部署在云端或本地。
“Hadoop”的功能
• 适用于大数据分析
由于大数据倾向于分布式和非结构化性质,HADOOP集群最适合用于大数据分析。由于流向计算节点的是处理逻辑(而不是实际数据),因此网络带宽消耗较少。这个概念称为数据本地化概念,有助于提高基于Hadoop的应用程序的效率。
• 可扩展性
HADOOP集群可以通过添加额外的集群节点轻松扩展到任何程度,从而允许大数据增长。此外,扩展不需要修改应用程序逻辑。
• 容错性
HADOOP生态系统提供了将输入数据复制到其他集群节点的机制。这样,在集群节点发生故障时,仍然可以通过使用存储在另一个集群节点上的数据来继续数据处理。
Hadoop中的网络拓扑
网络拓扑(排列)会影响Hadoop集群的性能,当Hadoop集群的规模增长时。除了性能之外,还需要关注高可用性和故障处理。为了实现这一点,Hadoop集群的形成利用了网络拓扑。

通常,网络带宽是形成任何网络时要考虑的重要因素。但是,由于测量带宽可能很困难,在Hadoop中,网络被表示为一棵树,树节点之间的距离(跳数)被认为是形成Hadoop集群的重要因素。这里,两个节点之间的距离等于它们到最近公共祖先的距离之和。
Hadoop集群由数据中心、机架和实际执行作业的节点组成。这里,数据中心包含机架,机架包含节点。可用于进程的网络带宽因进程位置而异。也就是说,离得越远,可用的带宽就越少-
- 同一节点上的进程
- 同一机架上的不同节点
- 同一数据中心不同机架上的节点
- 不同数据中心中的节点