HDFS 教程:使用 Java API 的架构、读写操作
什么是 HDFS?
HDFS 是一个分布式文件系统,用于在商用硬件集群上存储非常大的数据文件。它具有容错性、可扩展性,并且易于扩展。Hadoop 捆绑了 HDFS(Hadoop 分布式文件系统)。
当数据量超过单个物理机的存储容量时,就需要将其分散到多个独立的机器上。管理跨机器网络存储特定操作的文件系统称为分布式文件系统。HDFS 就是这样一种软件。
HDFS 架构
HDFS 集群主要由管理文件系统 元数据 的 NameNode 和存储 实际数据 的 DataNodes 组成。
- NameNode: NameNode 可以被认为是系统的“主”。它维护着文件系统树以及系统中存在的所有文件和目录的元数据。通过两个文件 “命名空间镜像” 和 “编辑日志” 来存储元数据信息。NameNode 知道包含给定文件数据块的所有 DataNode,但它不会持久存储块的位置。这些信息在系统启动时会从 DataNode 重建。
- DataNode: DataNodes 是位于集群中每台机器上的“从节点”,提供实际的存储。它负责为客户端提供服务,处理读取和写入请求。
HDFS 中的读/写操作以块级别进行。HDFS 中的数据文件被分解成块大小的片段,这些片段被存储为独立单元。默认块大小为 64 MB。
HDFS 的工作原理是数据复制,即创建数据块的多个副本,并将它们分布在集群中的各个节点上,以便在节点发生故障时实现数据的高可用性。
您知道吗? HDFS 中小于单个块的文件不会占用块的全部存储空间。
HDFS 中的读取操作
数据读取请求由 HDFS、NameNode 和 DataNode 处理。我们称读取者为“客户端”。下面的图描绘了 Hadoop 中的文件读取操作。
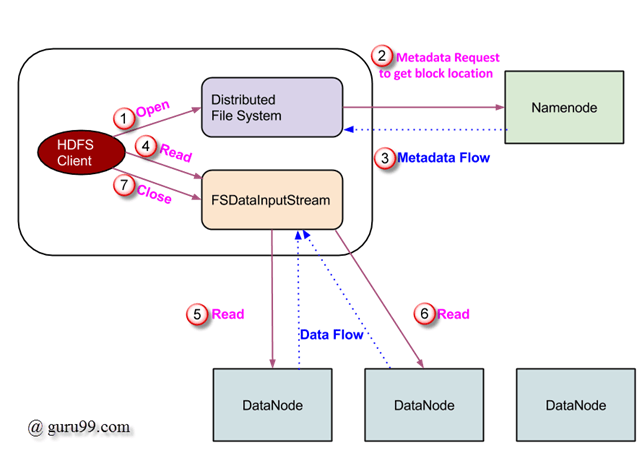
- 客户端通过调用 FileSystem 对象的 ‘open()’ 方法来发起读取请求;这是一个 DistributedFileSystem 类型的对象。
- 该对象使用 RPC 连接到 NameNode,并获取文件块位置等元数据信息。请注意,这些地址是文件前几个块的地址。
- 作为对该元数据请求的响应,将返回拥有该块副本的 DataNode 的地址。
-
收到 DataNode 地址后,将向客户端返回一个 FSDataInputStream 类型的对象。FSDataInputStream 包含 DFSInputStream,负责与 DataNode 和 NameNode 进行交互。在上面图中的第 4 步,客户端调用 ‘read()’ 方法,这会导致 DFSInputStream 与文件第一个块的第一个 DataNode 建立连接。
-
数据以流的形式读取,客户端重复调用 ‘read()’ 方法。此 read() 操作过程一直持续到块的末尾。
- 一旦到达块的末尾,DFSInputStream 会关闭连接,然后继续定位下一个 DataNode 来处理下一个块。
- 客户端完成读取后,会调用 close() 方法。
HDFS 中的写入操作
在本节中,我们将了解如何通过文件将数据写入 HDFS。
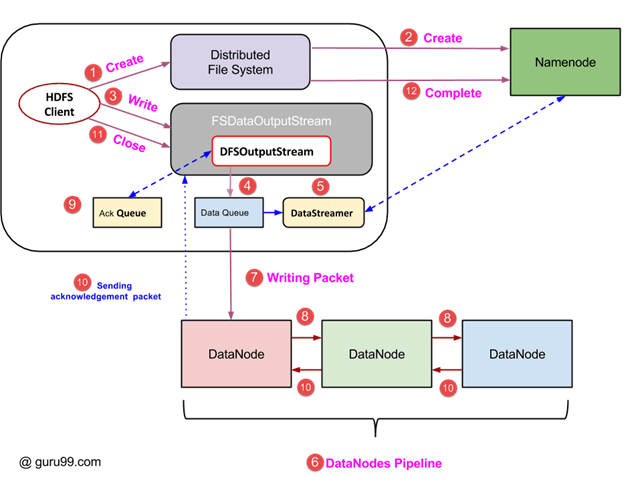
- 客户端通过调用 DistributedFileSystem 对象的 ‘create()’ 方法发起写入操作,该方法会创建一个新文件——如上图中的第 1 步。
- DistributedFileSystem 对象通过 RPC 调用连接到 NameNode 并启动新文件创建。但是,此文件创建操作不会为文件关联任何块。NameNode 负责验证正在创建的文件是否已存在,以及客户端是否具有创建新文件的正确权限。如果文件已存在或客户端没有足够的权限创建新文件,则会向客户端抛出 IOException。否则,操作成功,NameNode 会为该文件创建一个新记录。
- 一旦在 NameNode 中创建了新记录,就会向客户端返回一个 FSDataOutputStream 类型的对象。客户端使用它将数据写入 HDFS。调用数据写入方法(图中的第 3 步)。
- FSDataOutputStream 包含 DFSOutputStream 对象,该对象负责与 DataNodes 和 NameNode 的通信。当客户端继续写入数据时,DFSOutputStream 会使用这些数据继续创建数据包。这些数据包被排入一个名为 DataQueue 的队列。
- 还有一个名为 DataStreamer 的组件,它消耗这个 DataQueue。DataStreamer 还向 NameNode 请求分配新块,从而选择要用于复制的理想 DataNodes。
- 现在,复制过程开始,通过 DataNodes 创建一个管道。在本例中,我们选择的复制级别为 3,因此管道中有 3 个 DataNodes。
- DataStreamer 将数据包倒入管道中的第一个 DataNode。
- 管道中的每个 DataNode 都会存储接收到的数据包,并将其转发到管道中的第二个 DataNode。
- DFSOutputStream 维护另一个名为“Ack Queue”的队列,用于存储等待 DataNodes 确认的数据包。
- 一旦从管道中的所有 DataNodes 收到队列中某个数据包的确认,该数据包就会从“Ack Queue”中移除。如果发生任何 DataNode 故障,可以使用此队列中的数据重新启动操作。
- 客户端完成数据写入后,调用 close() 方法(图中的第 9 步)。调用 close() 会将剩余的数据包刷新到管道,然后等待确认。
- 收到最终确认后,会联系 NameNode 告知文件写入操作已完成。
使用 JAVA API 访问 HDFS
在本节中,我们尝试了解用于访问 Hadoop 文件系统的 Java 接口。
为了以编程方式与 Hadoop 的文件系统进行交互,Hadoop 提供了多个 JAVA 类。名为 org.apache.hadoop.fs 的包包含用于操作 Hadoop 文件系统的类。这些操作包括打开、读取、写入和关闭。实际上,Hadoop 的文件 API 是通用的,可以扩展以与 HDFS 以外的其他文件系统进行交互。
以编程方式从 HDFS 读取文件
使用 java.net.URL 对象来读取文件内容。首先,我们需要让 Java 识别 Hadoop 的 hdfs URL 方案。这是通过在 URL 对象上调用 setURLStreamHandlerFactory 方法并向其传递 FsUrlStreamHandlerFactory 的实例来完成的。此方法每个 JVM 只需执行一次,因此将其包含在静态块中。
示例如下:
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
此代码打开并读取文件内容。HDFS 上该文件的路径作为命令行参数传递给程序。
使用命令行界面访问 HDFS
这是与 HDFS 交互的最简单方法之一。命令行界面支持文件系统操作,如读取文件、创建目录、移动文件、删除数据和列出目录。
我们可以运行 ‘$HADOOP_HOME/bin/hdfs dfs -help’ 来获取每个命令的详细帮助。这里,‘dfs’ 是 HDFS 的一个 shell 命令,支持多个子命令。
下面列出了一些广泛使用的命令及其详细信息。
1. 将文件从本地文件系统复制到 HDFS
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /
![]()
此命令将本地文件系统中的文件 temp.txt 复制到 HDFS。
2. 我们可以使用 -ls 列出目录中的文件
$HADOOP_HOME/bin/hdfs dfs -ls /

我们可以看到文件 ‘temp.txt’(之前已复制)列在 ‘ / ‘ 目录中。
3. 将文件从 HDFS 复制到本地文件系统的命令
$HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt

我们可以看到 temp.txt 已复制到本地文件系统。
4. 创建新目录的命令
$HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory
![]()
检查目录是否已创建。现在,你应该知道怎么做了 😉