如何在R中替换缺失值(NA):na.omit & na.rm
数据科学中的缺失值是指在数据框的列中缺少观测值,或者包含非数字值而不是数字值。为了从数据中得出正确的结论,必须删除或替换缺失值。
在本教程中,我们将学习如何使用 dplyr 库来处理缺失值。dplyr 库是实现数据分析生态系统的一部分。
在本教程中,您将学习
mutate()
dplyr 库中的第四个动词有助于创建新变量或更改现有变量的值。
我们将分两个部分进行。我们将学习如何
- 从数据框中排除缺失值
- 用均值和中位数填充缺失值
mutate() 动词非常易于使用。我们可以按照以下语法创建一个新变量
mutate(df, name_variable_1 = condition, ...) arguments: -df: Data frame used to create a new variable -name_variable_1: Name and the formula to create the new variable -...: No limit constraint. Possibility to create more than one variable inside mutate()
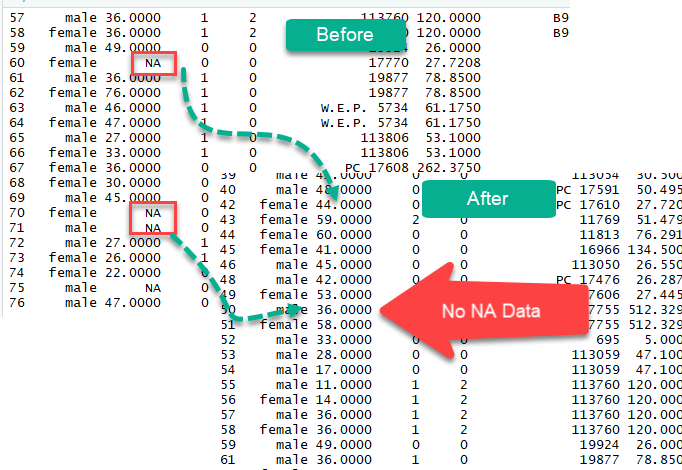
排除缺失值(NA)
dplyr 库中的 na.omit() 方法是排除缺失观测的简单方法。删除数据中的所有 NA 值很容易,但这并不意味着它是最优雅的解决方案。在分析过程中,最好使用多种方法来处理缺失值。
为了解决缺失观测值的问题,我们将使用泰坦尼克号数据集。在这个数据集中,我们可以获取悲剧发生期间船上乘客的信息。此数据集中有很多 NA 值需要处理。
我们将从互联网上载 csv 文件,然后检查哪些列包含 NA。要返回包含缺失数据的列,我们可以使用以下代码
让我们上传数据并验证缺失数据。
PATH <- "https://raw.githubusercontent.com/guru99-edu/R-Programming/master/test.csv" df_titanic <- read.csv(PATH, sep = ",") # Return the column names containing missing observations list_na <- colnames(df_titanic)[ apply(df_titanic, 2, anyNA) ] list_na
输出
## [1] "age" "fare"
此处,
colnames(df_titanic)[apply(df_titanic, 2, anyNA)]
给出没有数据的列名。
age 和 fare 列存在缺失值。
我们可以使用 na.omit() 删除它们。
library(dplyr) # Exclude the missing observations df_titanic_drop <-df_titanic %>% na.omit() dim(df_titanic_drop)
输出
## [1] 1045 13
新数据集包含 1045 行,而原始数据集有 1309 行。
用均值和中位数填充缺失数据
我们也可以用中位数或均值来填充(填充)缺失值。一个好的做法是为均值和中位数创建两个单独的变量。创建后,我们可以用新形成的变量替换缺失值。
我们将使用 apply 方法计算具有 NA 的列的均值。让我们看一个例子
步骤 1) 在本教程的较早部分,我们将包含缺失值的列名存储在名为 list_na 的列表中。我们将使用此列表
步骤 2) 现在我们需要使用参数 na.rm = TRUE 来计算均值。此参数是强制性的,因为列中包含缺失数据,这告诉 R 忽略它们。
# Create mean
average_missing <- apply(df_titanic[,colnames(df_titanic) %in% list_na],
2,
mean,
na.rm = TRUE)
average_missing
代码解释
我们在 apply 方法中传递了 4 个参数。
- df: df_titanic[,colnames(df_titanic) %in% list_na]。此代码将返回 list_na 对象中的列名(即“age”和“fare”)
- 2:在列上计算函数
- mean:计算均值
- na.rm = TRUE:忽略缺失值
输出
## age fare ## 29.88113 33.29548
我们已成功创建了包含缺失观测值的列的均值。这两个值将用于替换缺失的观测值。
步骤 3) 替换 NA 值
dplyr 库中的 mutate 动词对于创建新变量很有用。我们不一定想更改原始列,因此我们可以创建一个没有 NA 的新变量。mutate 易于使用,我们只需选择一个变量名并定义如何创建该变量。这是完整的代码
# Create a new variable with the mean and median df_titanic_replace <- df_titanic %>% mutate(replace_mean_age = ifelse(is.na(age), average_missing[1], age), replace_mean_fare = ifelse(is.na(fare), average_missing[2], fare))
代码解释
我们按照以下方式创建两个变量,replace_mean_age 和 replace_mean_fare
- replace_mean_age = ifelse(is.na(age), average_missing[1], age)
- replace_mean_fare = ifelse(is.na(fare), average_missing[2],fare)
如果 age 列有缺失值,则替换为 average_missing 的第一个元素(age 的均值),否则保留原始值。fare 的逻辑相同。
sum(is.na(df_titanic_replace$age))
输出
## [1] 263
执行替换
sum(is.na(df_titanic_replace$replace_mean_age))
输出
## [1] 0
原始的 age 列有 263 个缺失值,而新创建的变量已将它们替换为 age 变量的均值。
步骤 4) 我们也可以用中位数替换缺失值。
median_missing <- apply(df_titanic[,colnames(df_titanic) %in% list_na],
2,
median,
na.rm = TRUE)
df_titanic_replace <- df_titanic %>%
mutate(replace_median_age = ifelse(is.na(age), median_missing[1], age),
replace_median_fare = ifelse(is.na(fare), median_missing[2], fare))
head(df_titanic_replace)
输出

步骤 5) 大型数据集可能有许多缺失值,上述方法可能很麻烦。我们可以使用 sapply() 方法在一行代码中执行上述所有步骤。尽管我们不会知道均值和中位数的值。
sapply 不会创建 数据框,因此我们可以将 sapply() 函数包装在 data.frame() 中以创建数据框对象。
# Quick code to replace missing values with the mean
df_titanic_impute_mean < -data.frame(
sapply(
df_titanic,
function(x) ifelse(is.na(x),
mean(x, na.rm = TRUE),
x)))
摘要
我们有三种方法来处理缺失值
- 排除所有缺失的观测值
- 用均值填充
- 用中位数填充
下表总结了如何删除所有缺失的观测值
| 库 | 目标 | 代码 |
|---|---|---|
| base | 列出缺失的观测值 |
colnames(df)[apply(df, 2, anyNA)] |
| dplyr | 删除所有缺失值 |
na.omit(df) |
均值或中位数填充可以有两种方式实现
- 使用 apply
- 使用 sapply
| 方法 | 详情 | 优点 | 缺点 |
|---|---|---|---|
| 使用 apply 进行分步操作 | 检查有缺失的列,计算均值/中位数,存储值,然后使用 mutate() 替换 | 你知道均值/中位数的值 | 执行时间更长。对于大型数据集可能会变慢 |
| 使用 sapply 快速执行 | 使用 sapply() 和 data.frame() 自动查找并用均值/中位数替换缺失值 | 代码简洁且速度快 | 不知道填充值 |