R 编程中的函数及示例
R 中的函数是什么?
在编程环境中,函数是一组指令。程序员构建函数是为了避免重复相同的任务,或减少复杂性。
函数应该
- 编写用于执行特定任务
- 可能包含也可能不包含参数
- 包含主体
- 可能返回一个或多个值,也可能不返回。
函数的一般方法是使用参数部分作为输入,馈入主体部分,最后返回输出。函数语法如下:
function (arglist) {
#Function body
}
R 重要内置函数
R 中有很多内置函数。R 会将您的输入参数与函数参数进行匹配,无论是按值还是按位置,然后执行函数体。函数参数可以有默认值:如果您不指定这些参数,R 将采用默认值。
注意:
可以通过在控制台中运行函数本身来查看函数的源代码。
我们将看到三组函数的作用
- 通用函数
- 数学函数
- 统计函数
通用函数
我们已经熟悉了 cbind()、rbind()、range()、sort()、order() 等通用函数。这些函数中的每一个都有特定的任务,接受参数并返回输出。以下是您必须了解的重要函数:
diff() 函数
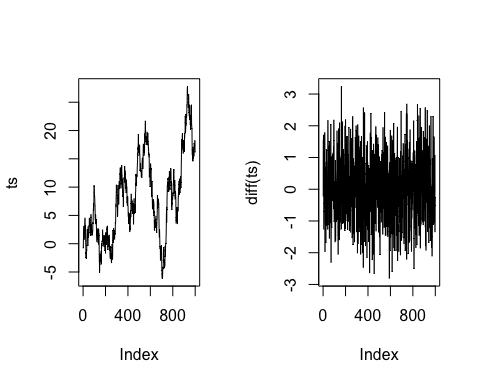
如果您处理时间序列,则需要通过获取其滞后值来使序列平稳。平稳过程允许均值、方差和自相关随时间保持不变。这主要可以改善时间序列的预测。可以使用 diff() 函数轻松完成。我们可以构建一个具有趋势的随机时间序列数据,然后使用 diff() 函数使序列平稳。diff() 函数接受一个参数,即一个向量,并返回合适的滞后和迭代差分。
注意:我们经常需要创建随机数据,但为了学习和比较,我们希望数字在不同机器上都相同。为确保我们都生成相同的数据,我们将使用 set.seed() 函数,并提供任意值 123。set.seed() 函数通过伪随机数生成器过程生成,这使得所有现代计算机都能拥有相同的数字序列。如果我们不使用 set.seed() 函数,我们将拥有不同的数字序列。
set.seed(123) ## Create the data x = rnorm(1000) ts <- cumsum(x) ## Stationary the serie diff_ts <- diff(ts) par(mfrow=c(1,2)) ## Plot the series plot(ts, type='l') plot(diff(ts), type='l')
length() 函数
在许多情况下,我们需要知道向量的长度用于计算或在 for 循环中使用。length() 函数计算向量 x 中的行数。以下代码导入 cars 数据集并返回行数。
注意:length() 返回向量中的元素数量。如果函数传递给矩阵或数据框,则返回列数。
dt <- cars ## number columns length(dt)
输出
## [1] 1
## number rows length(dt[,1])
输出
## [1] 50
数学函数
R 拥有大量的数学函数。
| 运算符 | 描述 |
|---|---|
| abs(x) | 取 x 的绝对值 |
| log(x,base=y) | 取以 y 为底的 x 的对数;如果未指定基数,则返回自然对数 |
| exp(x) | 返回 x 的指数 |
| sqrt(x) | 返回 x 的平方根 |
| factorial(x) | 返回 x 的阶乘(x!) |
# sequence of number from 44 to 55 both including incremented by 1 x_vector <- seq(45,55, by = 1) #logarithm log(x_vector)
输出
## [1] 3.806662 3.828641 3.850148 3.871201 3.891820 3.912023 3.931826 ## [8] 3.951244 3.970292 3.988984 4.007333
#exponential exp(x_vector)
#squared root sqrt(x_vector)
输出
## [1] 6.708204 6.782330 6.855655 6.928203 7.000000 7.071068 7.141428 ## [8] 7.211103 7.280110 7.348469 7.416198
#factorial factorial(x_vector)
输出
## [1] 1.196222e+56 5.502622e+57 2.586232e+59 1.241392e+61 6.082819e+62 ## [6] 3.041409e+64 1.551119e+66 8.065818e+67 4.274883e+69 2.308437e+71 ## [11] 1.269640e+73
统计函数
R 标准安装包含广泛的统计函数。在本教程中,我们将简要介绍最重要的函数。
基本统计函数
| 运算符 | 描述 |
|---|---|
| mean(x) | x 的平均值 |
| median(x) | x 的中位数 |
| var(x) | x 的方差 |
| sd(x) | x 的标准差 |
| scale(x) | x 的标准分数(z 分数) |
| quantile(x) | x 的四分位数 |
| summary(x) | x 的摘要:平均值、最小值、最大值等。 |
speed <- dt$speed speed # Mean speed of cars dataset mean(speed)
输出
## [1] 15.4
# Median speed of cars dataset median(speed)
输出
## [1] 15
# Variance speed of cars dataset var(speed)
输出
## [1] 27.95918
# Standard deviation speed of cars dataset sd(speed)
输出
## [1] 5.287644
# Standardize vector speed of cars dataset head(scale(speed), 5)
输出
## [,1] ## [1,] -2.155969 ## [2,] -2.155969 ## [3,] -1.588609 ## [4,] -1.588609 ## [5,] -1.399489
# Quantile speed of cars dataset quantile(speed)
输出
## 0% 25% 50% 75% 100% ## 4 12 15 19 25
# Summary speed of cars dataset summary(speed)
输出
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 4.0 12.0 15.0 15.4 19.0 25.0
到目前为止,我们已经了解了很多 R 内置函数。
注意:请注意参数的类,即数字、布尔值或字符串。例如,如果我们需要传递字符串值,我们需要将字符串括在引号中:“ABC”。
在 R 中编写函数
在某些情况下,我们需要编写自己的函数,因为我们需要完成特定的任务而没有现成的函数。用户定义的函数包含一个名称、参数和一个主体。
function.name <- function(arguments)
{
computations on the arguments
some other code
}
注意:一个好的做法是为用户定义的函数命名,使其不同于内置函数。这可以避免混淆。
单参数函数
在下一个代码片段中,我们定义了一个简单的平方函数。该函数接受一个值并返回该值的平方。
square_function<- function(n)
{
# compute the square of integer `n`
n^2
}
# calling the function and passing value 4
square_function(4)
代码解释
- 该函数名为 square_function;我们可以随意调用它。
- 它接收一个参数“n”。我们没有指定变量类型,因此用户可以传递整数、向量或矩阵。
- 该函数获取输入“n”并返回输入的平方。使用完函数后,可以使用 rm() 函数将其删除。
# 创建函数后
rm(square_function) square_function
在控制台中,我们可以看到一条错误消息:“Error: object ‘square_function’ not found”,表明该函数不存在。
环境作用域
在 R 中,环境是对象的集合,如函数、变量、数据框等。
每次提示 Rstudio 时,R 都会打开一个环境。
可用的顶级环境是全局环境,称为 R_GlobalEnv。我们还有局部环境。
我们可以列出当前环境的内容。
ls(environment())
输出
## [1] "diff_ts" "dt" "speed" "square_function" ## [5] "ts" "x" "x_vector"
您可以看到在 R_GlobalEnv 中创建的所有变量和函数。
上面的列表将因您在 R Studio 中执行的历史代码而异。
请注意,square_function 函数的参数 n不在该全局环境中。
为每个函数创建新环境。在上面的示例中,square_function() 函数在全局环境内创建了一个新环境。
为了阐明全局和局部环境之间的区别,让我们研究以下示例。
这些函数接受一个值 x 作为参数,并将其添加到在函数外部和内部定义的 y 中。
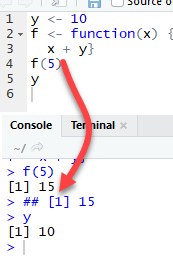
函数 f 返回输出 15。这是因为 y 定义在全局环境中。在全局环境中定义的任何变量都可以在本地使用。变量 y 在所有函数调用期间的值都为 10,并且可以随时访问。
让我们看看如果变量 y 在函数内部定义会发生什么。
我们需要在运行此代码之前使用 rm r drop `y`
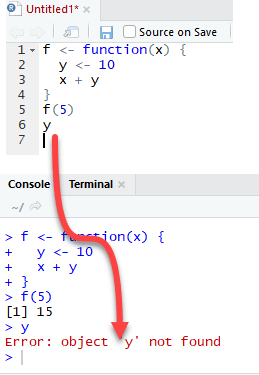
调用 f(5) 时,输出也是 15,但尝试打印 y 的值时会返回错误。变量 y 不在全局环境中。
最后,R 使用最近的变量定义来传递到函数体内部。让我们考虑以下示例。
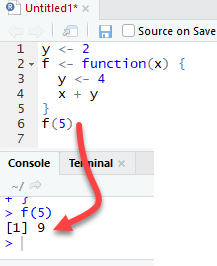
由于我们在函数体内显式创建了 y 变量,R 会忽略函数外部定义的 y 值。
多参数函数
我们可以编写一个具有多个参数的函数。考虑名为“times”的函数。它是一个将两个变量相乘的直接函数。
times <- function(x,y) {
x*y
}
times(2,4)
输出
## [1] 8
我们应该何时编写函数?
数据科学家需要做许多重复性的任务。大多数时候,我们会反复复制粘贴代码块。例如,在运行机器学习算法之前,强烈建议对变量进行归一化。归一化变量的公式是:
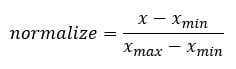
我们已经知道如何在 R 中使用 min() 和 max() 函数。我们使用 tibble 库来创建数据框。到目前为止,tibble 是从头开始创建数据集最方便的函数。
library(tibble) # Create a data frame data_frame <- tibble( c1 = rnorm(50, 5, 1.5), c2 = rnorm(50, 5, 1.5), c3 = rnorm(50, 5, 1.5), )
我们将分两步计算上述函数。第一步,我们将创建一个名为 c1_norm 的变量,它是 c1 的重缩放。在第二步,我们只需复制粘贴 c1_norm 的代码,然后将其更改为 c2 和 c3。
带有 c1 列的函数详细信息
分子:: data_frame$c1 -min(data_frame$c1))
分母: max(data_frame$c1)-min(data_frame$c1))
因此,我们可以对它们进行除法以获得 c1 列的归一化值。
(data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
我们可以创建 c1_norm、c2_norm 和 c3_norm。
Create c1_norm: rescaling of c1 data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1)) # show the first five values head(data_frame$c1_norm, 5)
输出
## [1] 0.3400113 0.4198788 0.8524394 0.4925860 0.5067991
它有效。我们可以复制粘贴
data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
然后将 c1_norm 改为 c2_norm,将 c1 改为 c2。我们对 c3_norm 做同样的事情。
data_frame$c2_norm <- (data_frame$c2 - min(data_frame$c2))/(max(data_frame$c2)-min(data_frame$c2)) data_frame$c3_norm <- (data_frame$c3 - min(data_frame$c3))/(max(data_frame$c3)-min(data_frame$c3))
我们完美地重缩放了变量 c1、c2 和 c3。
但是,此方法容易出错。我们可能会复制然后忘记粘贴后更改列名。因此,一个好的做法是,每次需要复制相同代码两次以上时,都编写一个函数。我们可以将代码重新排列成一个公式,并在需要时调用它。要编写自己的函数,我们需要给它
- 名称: normalize。
- 参数数量:我们只需要一个参数,即我们在计算中使用的列。
- 主体:这只是我们想要返回的公式。
我们将逐步创建 normalize 函数。
步骤 1) 我们创建分子,即 。在 R 中,我们可以将分子存储在变量中,如下所示。
nominator <- x-min(x)
步骤 2) 我们计算分母:。我们可以复制步骤 1 的思路,并将计算存储在变量中。
denominator <- max(x)-min(x)
步骤 3) 我们执行分子和分母之间的除法。
normalize <- nominator/denominator
步骤 4) 要将值返回到调用函数,我们需要将 normalize 放入 return() 中以获取函数的输出。
return(normalize)
步骤 5) 我们准备好使用该函数,方法是将所有内容包装在括号内。
normalize <- function(x){
# step 1: create the nominator
nominator <- x-min(x)
# step 2: create the denominator
denominator <- max(x)-min(x)
# step 3: divide nominator by denominator
normalize <- nominator/denominator
# return the value
return(normalize)
}
让我们用变量 c1 来测试我们的函数。
normalize(data_frame$c1)
它完美地运行。我们创建了第一个函数。
函数是执行重复任务的更全面的方法。我们可以对不同的列使用 normalize 公式,如下所示。
data_frame$c1_norm_function <- normalize (data_frame$c1) data_frame$c2_norm_function <- normalize (data_frame$c2) data_frame$c3_norm_function <- normalize (data_frame$c3)
尽管示例很简单,但我们可以推断出公式的力量。上面的代码更容易阅读,尤其是可以避免在粘贴代码时出错。
带条件的函数
有时,我们需要在函数中包含条件,以允许代码返回不同的输出。
在机器学习任务中,我们需要将数据集拆分为训练集和测试集。训练集允许算法从数据中学习。为了测试模型的性能,我们可以使用测试集来返回性能度量。R 没有创建两个数据集的函数。我们可以编写自己的函数来完成此操作。我们的函数接受两个参数,并称为 split_data()。其思想很简单,我们将数据集的长度(即观测值数量)乘以 0.8。例如,如果我们想将数据集按 80/20 的比例拆分,而我们的数据集包含 100 行,那么我们的函数将乘以 0.8*100 = 80。将选择 80 行作为我们的训练数据。
我们将使用 airquality 数据集来测试我们的用户定义函数。airquality 数据集有 153 行。我们可以使用下面的代码看到它。
nrow(airquality)
输出
## [1] 153
我们将按以下步骤进行:
split_data <- function(df, train = TRUE) Arguments: -df: Define the dataset -train: Specify if the function returns the train set or test set. By default, set to TRUE
我们的函数有两个参数。参数 train 是一个布尔参数。如果设置为 TRUE,我们的函数将创建训练数据集,否则它将创建测试数据集。
我们可以像对 normalise() 函数一样进行操作。我们像编写一次性代码一样编写代码,然后将条件包装在主体中以创建函数。
步骤 1
我们需要计算数据集的长度。这是使用 nrow() 函数完成的。Nrow 返回数据框中的总行数。我们将变量命名为 length。
length<- nrow(airquality) length
输出
## [1] 153
步骤 2
我们将长度乘以 0.8。它将返回要选择的行数。应该是 153*0.8 = 122.4
total_row <- length*0.8 total_row
输出
## [1] 122.4
我们想从 airquality 数据集中的 153 行中选择 122 行。我们创建一个包含从 1 到 total_row 的值的列表。我们将结果存储在名为 split 的变量中。
split <- 1:total_row split[1:5]
输出
## [1] 1 2 3 4 5
split 选择数据集的前 122 行。例如,我们可以看到我们的变量 split 收集了值 1、2、3、4、5 等。这些值将是我们选择要返回的行时的索引。
步骤 3
我们需要根据 split 变量中存储的值来选择 airquality 数据集中的行。这是这样做的:
train_df <- airquality[split, ] head(train_df)
输出
##[1] Ozone Solar.R Wind Temp Month Day ##[2] 51 13 137 10.3 76 6 20 ##[3] 15 18 65 13.2 58 5 15 ##[4] 64 32 236 9.2 81 7 3 ##[5] 27 NA NA 8.0 57 5 27 ##[6] 58 NA 47 10.3 73 6 27 ##[7] 44 23 148 8.0 82 6 13
步骤 4
我们可以使用剩余的行,即 123:153 来创建测试数据集。这是通过在 split 前面加上 – 来完成的。
test_df <- airquality[-split, ] head(test_df)
输出
##[1] Ozone Solar.R Wind Temp Month Day ##[2] 123 85 188 6.3 94 8 31 ##[3] 124 96 167 6.9 91 9 1 ##[4] 125 78 197 5.1 92 9 2 ##[5] 126 73 183 2.8 93 9 3 ##[6] 127 91 189 4.6 93 9 4 ##[7] 128 47 95 7.4 87 9 5
步骤 5
我们可以在函数的主体中创建条件。记住,我们有一个参数 train,它是一个布尔值,默认设置为 TRUE 以返回训练集。为了创建条件,我们使用 if 语法。
if (train ==TRUE){
train_df <- airquality[split, ]
return(train)
} else {
test_df <- airquality[-split, ]
return(test)
}
就是这样,我们可以编写函数了。我们只需要将 airquality 改为 df,因为我们想尝试将函数应用于任何数据框,而不仅仅是 airquality。
split_data <- function(df, train = TRUE){
length<- nrow(df)
total_row <- length *0.8
split <- 1:total_row
if (train ==TRUE){
train_df <- df[split, ]
return(train_df)
} else {
test_df <- df[-split, ]
return(test_df)
}
}
让我们在 airquality 数据集上试用我们的函数。我们应该有一个包含 122 行的训练集和一个包含 31 行的测试集。
train <- split_data(airquality, train = TRUE) dim(train)
输出
## [1] 122 6
test <- split_data(airquality, train = FALSE) dim(test)
输出
## [1] 31 6