合并 R 中的数据框:完全匹配和部分匹配
很多时候,我们有来自多个来源的数据。要执行分析,我们需要使用一个或多个**共同键变量**将两个数据框**合并**在一起。
在本教程中,您将学习
完全匹配
完全匹配会返回在目标表中具有对应项的值。不匹配的值将不会在新数据框中返回。然而,部分匹配会将缺失值返回为 NA。
我们将看到一个简单的**内连接**。内连接关键字选择两个表中具有匹配值的记录。要连接两个数据集,我们可以使用 merge() 函数。我们将使用三个参数
merge(x, y, by.x = x, by.y = y) Arguments: -x: The origin data frame -y: The data frame to merge -by.x: The column used for merging in x data frame. Column x to merge on -by.y: The column used for merging in y data frame. Column y to merge on
示例
创建第一个包含变量的数据集
- 姓氏
- 国籍
创建第二个包含变量的数据集
- 姓氏
- 电影
共同的键变量是姓氏。我们可以合并两个数据并检查维度是否为 7×3。
我们在数据框中添加 stringsAsFactors=FALSE,因为我们不希望 R 将字符串转换为因子,我们希望将变量视为字符。
# Create origin dataframe(
producers <- data.frame(
surname = c("Spielberg","Scorsese","Hitchcock","Tarantino","Polanski"),
nationality = c("US","US","UK","US","Poland"),
stringsAsFactors=FALSE)
# Create destination dataframe
movies <- data.frame(
surname = c("Spielberg",
"Scorsese",
"Hitchcock",
"Hitchcock",
"Spielberg",
"Tarantino",
"Polanski"),
title = c("Super 8",
"Taxi Driver",
"Psycho",
"North by Northwest",
"Catch Me If You Can",
"Reservoir Dogs","Chinatown"),
stringsAsFactors=FALSE)
# Merge two datasets
m1 <- merge(producers, movies, by.x = "surname")
m1
dim(m1)
输出
surname nationality title 1 Hitchcock UK Psycho 2 Hitchcock UK North by Northwest 3 Polanski Poland Chinatown 4 Scorsese US Taxi Driver 5 Spielberg US Super 8 6 Spielberg US Catch Me If You Can 7 Tarantino US Reservoir Dogs
当共同键变量的名称不同时,我们来合并数据框。
我们将 movies 数据框中的 surname 改为 name。我们使用 identical(x1, x2) 函数来检查两个数据框是否相同。
# Change name of ` movies ` dataframe colnames(movies)[colnames(movies) == 'surname'] <- 'name' # Merge with different key value m2 <- merge(producers, movies, by.x = "surname", by.y = "name") # Print head of the data head(m2)
输出
##surname nationality title ## 1 Hitchcock UK Psycho ## 2 Hitchcock UK North by Northwest ## 3 Polanski Poland Chinatown ## 4 Scorsese US Taxi Driver ## 5 Spielberg US Super 8 ## 6 Spielberg US Catch Me If You Can
# Check if data are identical identical(m1, m2)
输出
## [1] TRUE
这表明即使列名不同,合并操作也会执行。
部分匹配
两个数据框具有相同的共同键变量并不奇怪。在**完全匹配**中,数据框**仅**返回 x 和 y 数据集中找到的行。通过**部分合并**,可以保留与其他数据框中没有匹配行的行。这些行将在通常填充 y 值数据的列中具有 NA。我们可以通过将 all.x 设置为 TRUE 来实现此目的。
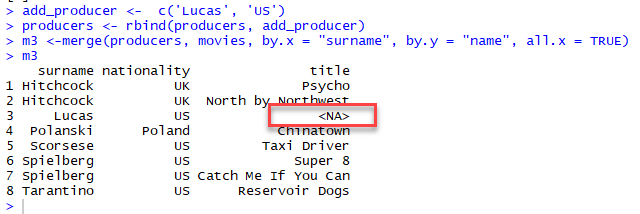
例如,我们可以在 producer 数据框中添加一个新制作人 Lucas,而 movies 数据框中没有电影引用。如果我们设置 all.x= FALSE,R 将仅连接两个数据集中匹配的值。在我们的例子中,制作人 Lucas 将不会被合并,因为它在一个数据集中缺失。
让我们看看当我们指定 all.x= TRUE 和不指定 all.x= TRUE 时每个输出的维度。
# Create a new producer
add_producer <- c('Lucas', 'US')
# Append it to the ` producer` dataframe
producers <- rbind(producers, add_producer)
# Use a partial merge
m3 <-merge(producers, movies, by.x = "surname", by.y = "name", all.x = TRUE)
m3
输出
# Compare the dimension of each data frame dim(m1)
输出
## [1] 7 3
dim(m2)
输出
## [1] 7 3
dim(m3)
输出
## [1] 8 3
可以看到,新数据框的维度为 8×3,而 m1 和 m2 的维度为 7×3。R 为 books 数据框中缺失的作者包含 NA。