Dplyr 教程:在 R 中合并和连接数据及示例
数据分析导论
数据分析可分为三个部分
- 提取:首先,我们需要从多个来源收集数据并合并它们。
- 转换:此步骤涉及数据操作。一旦我们整合了所有数据来源,我们就可以开始清理数据。
- 可视化:最后一步是可视化我们的数据以检查不规则之处。
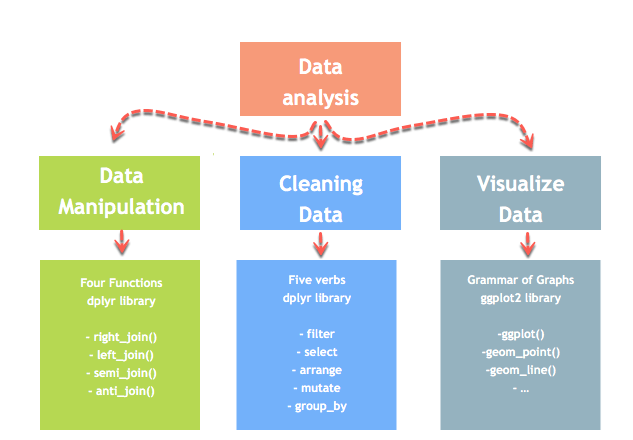
数据科学家面临的最重大挑战之一是数据操作。数据很少能以所需的格式获得。数据科学家需要花费至少一半的时间来清理和操作数据。这是工作中最重要的任务之一。如果数据操作过程不完整、不精确、不严谨,模型将无法正确运行。
R Dplyr
R 有一个名为 dplyr 的库来帮助进行数据转换。dplyr 库主要围绕四个函数来操作数据和五个动词来清理数据。之后,我们可以使用 ggplot 库来分析和可视化数据。
我们将学习如何使用 dplyr 库来操作 Data Frame。
使用 R Dplyr 合并数据
dplyr 提供了一种方便的方式来合并数据集。我们可能有许多输入数据源,在某些时候,我们需要将它们合并。dplyr 的连接将变量添加到原始数据集的右侧。
Dplyr 连接
以下是 dplyr 用于合并两个数据集的四个重要连接类型
| 函数 | 目标 | 参数 | 多键 |
|---|---|---|---|
| left_join() | 合并两个数据集。保留源表中的所有观察值 | data, origin, destination, by = “ID” | origin, destination, by = c(“ID”, “ID2”) |
| right_join() | 合并两个数据集。保留目标表中的所有观察值 | data, origin, destination, by = “ID” | origin, destination, by = c(“ID”, “ID2”) |
| inner_join() | 合并两个数据集。排除所有不匹配的行 | data, origin, destination, by = “ID” | origin, destination, by = c(“ID”, “ID2”) |
| full_join() | 合并两个数据集。保留所有观察值 | data, origin, destination, by = “ID” | origin, destination, by = c(“ID”, “ID2”) |
我们将通过一个简单的例子来学习所有连接类型。
首先,我们构建两个数据集。表 1 包含两个变量 ID 和 y,而表 2 包含 ID 和 z。在每种情况下,我们需要有一个键对变量。在我们的例子中,ID 是我们的键变量。该函数将查找两个表中的相同值,并将返回的值绑定到表 1 的右侧。
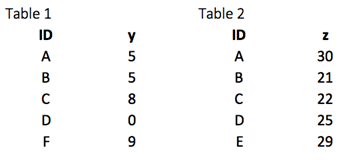
library(dplyr) df_primary <- tribble( ~ID, ~y, "A", 5, "B", 5, "C", 8, "D", 0, "F", 9) df_secondary <- tribble( ~ID, ~z, "A", 30, "B", 21, "C", 22, "D", 25, "E", 29)
Dplyr left_join()
合并两个数据集的最常用方法是使用 left_join() 函数。从下面的图片中我们可以看到,键对完美匹配了两个数据集中的 A、B、C 和 D 行。但是,E 和 F 被遗漏了。我们如何处理这两个观察值?使用 left_join(),我们将保留原始表中的所有变量,而不考虑目标表中没有键对的变量。在我们的例子中,变量 E 在表 1 中不存在。因此,该行将被删除。变量 F 来自源表;它将被保留在 left_join() 之后,并在 z 列中返回 NA。下图重现了 left_join() 的结果。
dplyr left_join() 示例
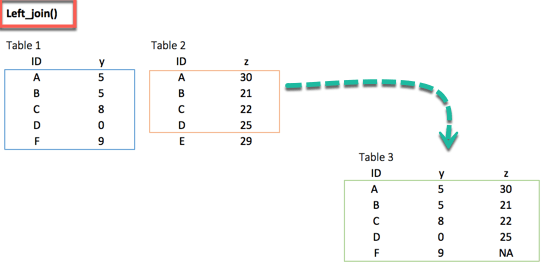
left_join(df_primary, df_secondary, by ='ID')
输出
## # A tibble: 5 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25 ## 5 F 9 NA
Dplyr right_join()
right_join() 函数的功能与 left_join() 完全相同。唯一的区别在于被删除的行。目标数据框中可用值 E 存在于新表中,并且 y 列的值为 NA。
dplyr right_join() 示例
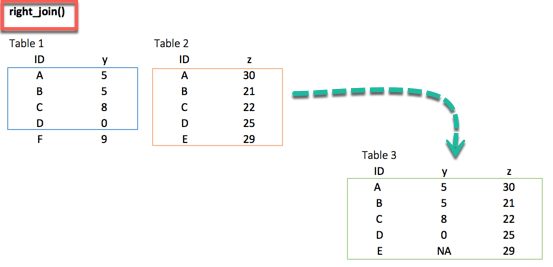
right_join(df_primary, df_secondary, by = 'ID')
输出
## # A tibble: 5 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25 ## 5 E NA 29
Dplyr inner_join()
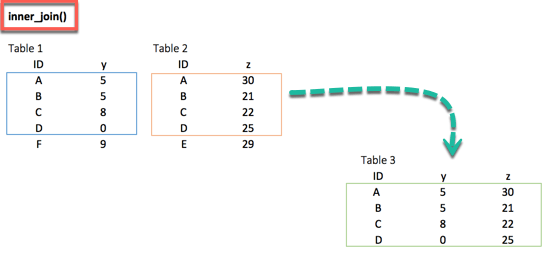
当我们 100% 确定两个数据集不会匹配时,我们可以考虑仅返回两个数据集中都存在的行。当我们需要一个干净的数据集或者我们不想用平均值或中位数来填充缺失值时,这是可能的。
inner_join() 会有所帮助。此函数会排除不匹配的行。
dplyr inner_join() 示例
inner_join(df_primary, df_secondary, by ='ID')
输出
## # A tibble: 4 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25
Dplyr full_join()
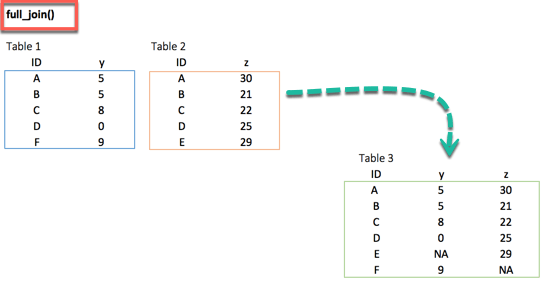
最后,full_join() 函数保留所有观察值并将缺失值替换为 NA。
dplyr full_join() 示例
full_join(df_primary, df_secondary, by = 'ID')
输出
## # A tibble: 6 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25 ## 5 F 9 NA ## 6 E NA 29
多个键对
最后但同样重要的是,我们的数据集中可能有多对键。考虑以下数据集,其中我们有年份或客户购买的产品列表。

如果我们尝试合并这两个表,R 会抛出错误。为了解决这个问题,我们可以传递两个键对变量,即 ID 和 year,它们出现在两个数据集中。我们可以使用以下代码来合并 table1 和 table 2。
df_primary <- tribble(
~ID, ~year, ~items,
"A", 2015,3,
"A", 2016,7,
"A", 2017,6,
"B", 2015,4,
"B", 2016,8,
"B", 2017,7,
"C", 2015,4,
"C", 2016,6,
"C", 2017,6)
df_secondary <- tribble(
~ID, ~year, ~prices,
"A", 2015,9,
"A", 2016,8,
"A", 2017,12,
"B", 2015,13,
"B", 2016,14,
"B", 2017,6,
"C", 2015,15,
"C", 2016,15,
"C", 2017,13)
left_join(df_primary, df_secondary, by = c('ID', 'year'))
输出
## # A tibble: 9 x 4 ## ID year items prices ## <chr> <dbl> <dbl> <dbl> ## 1 A 2015 3 9 ## 2 A 2016 7 8 ## 3 A 2017 6 12 ## 4 B 2015 4 13 ## 5 B 2016 8 14 ## 6 B 2017 7 6 ## 7 C 2015 4 15 ## 8 C 2016 6 15 ## 9 C 2017 6 13
R 中的数据清理函数
以下是清理数据的四个重要函数
| 函数 | 目标 | 参数 |
|---|---|---|
| gather() | 将数据从宽格式转换为长格式 | (data, key, value, na.rm = FALSE) |
| spread() | 将数据从长格式转换为宽格式 | (data, key, value) |
| separate() | 将一个变量拆分为两个 | (data, col, into, sep= “”, remove = TRUE) |
| unite() | 将两个变量合并为一个 | (data, col, conc ,sep= “”, remove = TRUE) |
我们使用 tidyr 库。该库属于用于操作、清理和可视化数据的库集合。如果我们使用 anaconda 安装 R,该库已经安装。我们可以在此处找到该库:https://anaconda.org/r/r-tidyr。
如果尚未安装,请键入以下命令来安装 tidyr
install tidyr : install.packages("tidyr")
gather()
gather() 函数的目的是将数据从宽格式转换为长格式。
语法
gather(data, key, value, na.rm = FALSE) Arguments: -data: The data frame used to reshape the dataset -key: Name of the new column created -value: Select the columns used to fill the key column -na.rm: Remove missing values. FALSE by default
示例
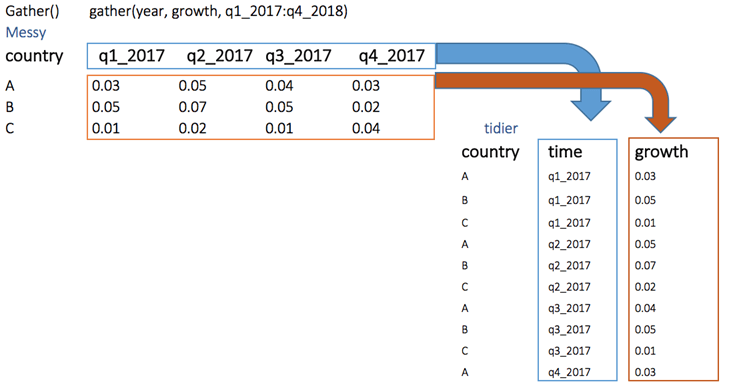
下面,我们可以可视化从宽到长的重塑概念。我们想创建一个名为 growth 的单个列,该列由 quarter 变量的行填充。
library(tidyr)
# Create a messy dataset
messy <- data.frame(
country = c("A", "B", "C"),
q1_2017 = c(0.03, 0.05, 0.01),
q2_2017 = c(0.05, 0.07, 0.02),
q3_2017 = c(0.04, 0.05, 0.01),
q4_2017 = c(0.03, 0.02, 0.04))
messy
输出
## country q1_2017 q2_2017 q3_2017 q4_2017 ## 1 A 0.03 0.05 0.04 0.03 ## 2 B 0.05 0.07 0.05 0.02 ## 3 C 0.01 0.02 0.01 0.04
# Reshape the data tidier <-messy %>% gather(quarter, growth, q1_2017:q4_2017) tidier
输出
## country quarter growth ## 1 A q1_2017 0.03 ## 2 B q1_2017 0.05 ## 3 C q1_2017 0.01 ## 4 A q2_2017 0.05 ## 5 B q2_2017 0.07 ## 6 C q2_2017 0.02 ## 7 A q3_2017 0.04 ## 8 B q3_2017 0.05 ## 9 C q3_2017 0.01 ## 10 A q4_2017 0.03 ## 11 B q4_2017 0.02 ## 12 C q4_2017 0.04
在 gather() 函数中,我们创建了两个新变量 quarter 和 growth,因为我们原始数据集有一个分组变量:即 country 和键值对。
spread()
spread() 函数的功能与 gather 相反。
语法
spread(data, key, value) arguments: data: The data frame used to reshape the dataset key: Column to reshape long to wide value: Rows used to fill the new column
示例
我们可以使用 spread() 将更整洁的数据集重塑为混乱的状态。
# Reshape the data messy_1 <- tidier %>% spread(quarter, growth) messy_1
输出
## country q1_2017 q2_2017 q3_2017 q4_2017 ## 1 A 0.03 0.05 0.04 0.03 ## 2 B 0.05 0.07 0.05 0.02 ## 3 C 0.01 0.02 0.01 0.04
separate()
separate() 函数根据分隔符将一个列拆分为两个。此函数在某些情况下很有用,例如日期变量。我们的分析可能需要关注月份和年份,而我们想将该列拆分为两个新变量。
语法
separate(data, col, into, sep= "", remove = TRUE) arguments: -data: The data frame used to reshape the dataset -col: The column to split -into: The name of the new variables -sep: Indicates the symbol used that separates the variable, i.e.: "-", "_", "&" -remove: Remove the old column. By default sets to TRUE.
示例
通过应用 separate() 函数,我们可以将 quarter 从 year 中拆分出来。
separate_tidier <-tidier %>%
separate(quarter, c("Qrt", "year"), sep ="_")
head(separate_tidier)
输出
## country Qrt year growth ## 1 A q1 2017 0.03 ## 2 B q1 2017 0.05 ## 3 C q1 2017 0.01 ## 4 A q2 2017 0.05 ## 5 B q2 2017 0.07 ## 6 C q2 2017 0.02
unite()
unite() 函数将两个列连接成一个。
语法
unit(data, col, conc ,sep= "", remove = TRUE) arguments: -data: The data frame used to reshape the dataset -col: Name of the new column -conc: Name of the columns to concatenate -sep: Indicates the symbol used that unites the variable, i.e: "-", "_", "&" -remove: Remove the old columns. By default, sets to TRUE
示例
在上面的示例中,我们从 year 中拆分了 quarter。如果我们想合并它们怎么办?我们使用以下代码
unit_tidier <- separate_tidier %>% unite(Quarter, Qrt, year, sep ="_") head(unit_tidier)
输出
## country Quarter growth ## 1 A q1_2017 0.03 ## 2 B q1_2017 0.05 ## 3 C q1_2017 0.01 ## 4 A q2_2017 0.05 ## 5 B q2_2017 0.07 ## 6 C q2_2017 0.02
摘要
- 数据分析可分为三个部分:提取、转换和可视化。
- R 有一个名为 dplyr 的库来帮助进行数据转换。dplyr 库主要围绕四个函数来操作数据和五个动词来清理数据。
- dplyr 提供了一种方便的方式来合并数据集。dplyr 的连接将变量添加到原始数据集的右侧。
- dplyr 的优点在于它处理四种类型的连接,与 SQL 类似。
- left_join() – 合并两个数据集并保留源表中的所有观察值。
- right_join() – 合并两个数据集并保留目标表中的所有观察值。
- inner_join() – 合并两个数据集并排除所有不匹配的行。
- full_join() – 合并两个数据集并保留所有观察值。
- 使用 tidyr 库,您可以使用以下函数转换数据集
- gather():将数据从宽格式转换为长格式。
- spread():将数据从长格式转换为宽格式。
- separate():将一个变量拆分为两个。
- unit():将两个变量合并为一个。