R 数据导入:读取 CSV、Excel、SPSS、Stata、SAS 文件
数据可以以各种格式存在。对于每种格式,R都有特定的函数和参数。本教程解释如何将数据导入R。
读取CSV
最常见的数据存储格式之一是.csv(逗号分隔值)文件格式。R在启动时会加载一系列库,包括utils包。这个包可以方便地打开csv文件,并结合reading.csv()函数使用。下面是read.csv的语法。
read.csv(file, header = TRUE, sep = ",")
论证:
- file: 文件存储的路径
- header: 确认文件是否有标题行,默认为TRUE
- sep: 用于分隔变量的符号。默认为 `,`。
我们将读取名为mtcats的数据文件。csv文件在线存储。如果您的.csv文件存储在本地,您可以替换代码片段中的PATH。别忘了将其括在‘ ‘中。PATH需要是字符串值。
对于Mac用户,下载文件夹的路径是
"/Users/USERNAME/Downloads/FILENAME.csv"
对于Windows用户
"C:\Users\USERNAME\Downloads\FILENAME.csv"
请注意,我们应该始终指定文件名扩展名。
- .csv
- .xlsx
- .txt
- …
PATH <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/mtcars.csv' df <- read.csv(PATH, header = TRUE, sep = ',') length(df)
输出
## [1] 12
class(df$X)
输出
## [1] "factor"
R默认将字符值返回为因子(Factor)。我们可以通过添加stringsAsFactors = FALSE来关闭此设置。
PATH <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/mtcars.csv' df <-read.csv(PATH, header =TRUE, sep = ',', stringsAsFactors =FALSE) class(df$X)
输出
## [1] "character"
变量X的类现在是字符。
读取Excel文件
Excel文件在数据分析师中非常受欢迎。电子表格易于使用且灵活。R配备了readxl库来导入Excel电子表格。
使用此代码
require(readxl)
来检查readxl是否已安装在您的机器上。如果您使用r-conda-essential安装了R,则该库已安装。您应该在命令窗口中看到
输出
Loading required package: readxl.
如果包不存在,您可以通过conda 库进行安装,或者在终端中使用conda install -c mittner r-readxl。
使用以下命令加载库以导入Excel文件。
library(readxl)
readxl_example()
在本教程中,我们将使用readxl包中包含的示例。
使用代码
readxl_example()
查看库中所有可用的电子表格。
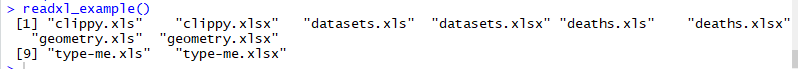
要检查名为clippy.xls的电子表格的位置,只需使用
readxl_example("geometry.xls")

如果您使用conda安装了R,则电子表格位于Anaconda3/lib/R/library/readxl/extdata/filename.xls
read_excel()
read_excel()函数在打开xls和xlsx扩展名时非常有用。
语法是
read_excel(PATH, sheet = NULL, range= NULL, col_names = TRUE) arguments: -PATH: Path where the excel is located -sheet: Select the sheet to import. By default, all -range: Select the range to import. By default, all non-null cells -col_names: Select the columns to import. By default, all non-null columns
我们可以从readxl库导入电子表格,并计算第一个工作表中的列数。
# Store the path of `datasets.xlsx`
example <- readxl_example("datasets.xlsx")
# Import the spreadsheet
df <- read_excel(example)
# Count the number of columns
length(df)
输出
## [1] 5
excel_sheets()
文件datasets.xlsx由4个工作表组成。我们可以使用excel_sheets()函数找出工作簿中有哪些工作表。
example <- readxl_example("datasets.xlsx")
excel_sheets(example)
输出
[1] "iris" "mtcars" "chickwts" "quakes"
如果工作表包含许多工作表,可以通过使用sheet参数轻松选择特定工作表。我们可以指定工作表的名称或工作表的索引。我们可以使用identical()来验证两个函数是否返回相同的结果。
example <- readxl_example("datasets.xlsx")
quake <- read_excel(example, sheet = "quakes")
quake_1 <-read_excel(example, sheet = 4)
identical(quake, quake_1)
输出
## [1] TRUE
我们可以通过两种方式控制要读取的单元格
- 使用n_max参数返回n行
- 使用range参数结合cell_rows或cell_cols
例如,我们将n_max设置为5以导入前五行。
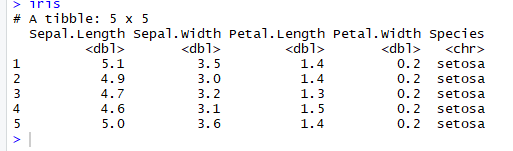
# Read the first five row: with header iris <-read_excel(example, n_max =5, col_names =TRUE)
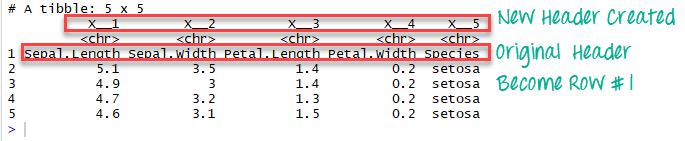
如果我们将col_names设置为FALSE,R将自动创建标题。
# Read the first five row: without header iris_no_header <-read_excel(example, n_max =5, col_names =FALSE)
iris_no_header
在数据框iris_no_header中,R创建了五个名为X__1、X__2、X__3、X__4和X__5的新变量。
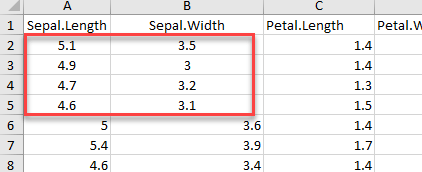
我们还可以使用range参数来选择电子表格中的行和列。在下面的代码中,我们使用Excel风格来选择范围A1到B5。
# Read rows A1 to B5 example_1 <-read_excel(example, range = "A1:B5", col_names =TRUE) dim(example_1)
输出
## [1] 4 2
我们可以看到example_1返回了4行2列。该数据集有标题,因此维度是4×2。
在第二个示例中,我们使用cell_rows()函数来控制要返回的行范围。如果我们想导入第1到5行,我们可以设置cell_rows(1:5)。请注意,cell_rows(1:5)返回的结果与cell_rows(5:1)相同。
# Read rows 1 to 5 example_2 <-read_excel(example, range =cell_rows(1:5),col_names =TRUE) dim(example_2)
输出
## [1] 4 5
然而,example_2是一个4×5的矩阵。iris数据集有5列带标题。我们返回标题的所有列的前四行。
如果我们想导入不从第一行开始的行,我们必须包含col_names = FALSE。如果我们使用range = cell_rows(2:5),那么很明显我们的数据框不再有标题了。
iris_row_with_header <-read_excel(example, range =cell_rows(2:3), col_names=TRUE) iris_row_no_header <-read_excel(example, range =cell_rows(2:3),col_names =FALSE)
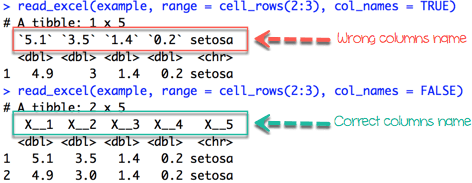
We can select the columns with the letter, like in Excel.
# Select columns A and B
col <-read_excel(example, range =cell_cols("A:B"))
dim(col)
输出
## [1] 150 2
注意:range = cell_cols(“A:C”)返回所有具有非空值的单元格。该数据集包含150行,因此read_excel()最多返回150行。这可以通过dim()函数进行验证。
read_excel()在单元格中出现没有数值的符号时返回NA。我们可以使用两个函数组合来计算缺失值的数量。
- sum
- is.na
这是代码
iris_na <-read_excel(example, na ="setosa") sum(is.na(iris_na))
输出
## [1] 50
我们有50个缺失值,这些行属于setosa物种。
从其他统计软件导入数据
我们将使用heaven包导入不同的文件格式。该包支持SAS、STATA和SPSS软件。我们可以使用以下函数根据文件扩展名打开不同类型的数据集。
- SAS: read_sas()
- STATA: read_dta() (或read_stata(),它们是相同的)
- SPSS: read_sav()或read_por()。我们需要检查扩展名。
这些函数只需要一个参数。我们需要知道文件存储的PATH。这样,我们就可以打开SAS、STATA和SPSS的所有文件。这三个函数也接受URL。
library(haven)
haven包随conda r-essential一起提供,否则请访问链接或在终端中执行conda install -c conda-forge r-haven。
读取SAS
在我们的示例中,我们将使用IDRE的admission数据集。
PATH_sas <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.sas7bdat?raw=true' df <- read_sas(PATH_sas) head(df)
输出
## # A tibble: 6 x 4 ## ADMIT GRE GPA RANK ## <dbl> <dbl> <dbl> <dbl> ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2
读取STATA
对于STATA数据文件,您可以使用read_dta()。我们使用完全相同的数据集,但存储在.dta文件中。
PATH_stata <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.dta?raw=true' df <- read_dta(PATH_stata) head(df)
输出
## # A tibble: 6 x 4 ## admit gre gpa rank ## <dbl> <dbl> <dbl> <dbl> ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2
读取SPSS
我们使用read_sav()函数来打开SPSS文件。文件扩展名为“.sav”。
PATH_spss <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.sav?raw=true' df <- read_sav(PATH_spss) head(df)
输出
## # A tibble: 6 x 4 ## admit gre gpa rank ## <dbl> <dbl> <dbl> <dbl> ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2
数据导入最佳实践
当我们要将数据导入R时,实现以下清单很有用。它将使数据正确导入R变得容易。
- 电子表格的典型格式是使用前几行作为标题(通常是变量名)。
- 避免使用空格命名数据集;这可能导致将其解释为单独的变量。或者,首选使用‘_’或‘-’。
- 偏好使用简短的名称。
- 不要在名称中包含符号:例如:exchange_rate_$_€是不正确的。最好命名为:exchange_rate_dollar_euro。
- 使用NA表示缺失值,否则我们需要稍后清理格式。
摘要
下表总结了在R中导入不同类型文件所需的函数。第一列是与函数相关的库。最后一列是指默认参数。
| 库 | 目标 | 函数 | 默认参数 |
|---|---|---|---|
| utils | 读取CSV文件 | read.csv() | file, header =,TRUE, sep = “,” |
| readxl | 读取EXCEL文件 | read_excel() | path, range = NULL, col_names = TRUE |
| haven | 读取SAS文件 | read_sas() | path |
| haven | 读取STATA文件 | read_stata() | path |
| haven | 读取SPSS文件 | read_sav() | path |
下表显示了使用read_excel()函数导入选定内容的各种方法。
| 函数 | 目标 | 参数 |
|---|---|---|
| read_excel() | 读取n行数 | n_max = 10 |
| 像Excel一样选择行和列 | range = “A1:D10” | |
| 按索引选择行 | range= cell_rows(1:3) | |
| 按字母选择列 | range = cell_cols(“A:C”) |