Python 列表示例气泡排序算法
什么是冒泡排序?
冒泡排序是一种排序算法,通过比较两个相邻的值,将列表项按升序排序。如果第一个值大于第二个值,则第一个值占据第二个值的位置,而第二个值占据第一个值的位置。如果第一个值小于第二个值,则不进行交换。
此过程将一直重复,直到列表中的所有值都被比较并根据需要进行交换。每次迭代通常称为一个“趟”。冒泡排序中的趟数等于列表中元素的数量减一。
在本篇 Python 教程中,你将学习:
实现冒泡排序算法
我们将把实现分解为三个步骤:问题、解决方案和可用于编写任何语言代码的算法。
问题
给定一个随机顺序的列表,我们希望将其按有序的方式排列。
考虑以下列表
[21,6,9,33,3]
解决方案
遍历列表,比较相邻的两个元素,如果第一个值大于第二个值,则交换它们。
结果应如下所示
[3,6,9,21,33]
算法
冒泡排序算法的工作原理如下:
第一步)获取元素总数。获取给定列表中的项总数。
第二步)确定要进行的外部趟数(n-1)。其长度是列表长度减一。
第三步)对外趟 1 执行内趟(n-1)次。获取第一个元素的值并与第二个值进行比较。如果第二个值小于第一个值,则交换位置。
第四步)重复第三步的趟数,直到达到外部趟(n-1)。获取列表中的下一个元素,然后重复第三步中执行的过程,直到所有值都已放置在正确的升序中。
第五步)所有趟都完成后返回结果。返回排序列表的结果。
第六步)优化算法
如果列表或相邻值已排序,则避免不必要的内部趟。例如,如果提供的列表已按升序排序,则可以提前终止循环。
优化的冒泡排序算法
默认情况下,Python 中的冒泡排序算法会比较列表中的所有项,而不管列表是否已排序。如果给定的列表已排序,比较所有值会浪费时间和资源。
优化冒泡排序可以帮助我们避免不必要的迭代,节省时间和资源。
例如,如果第一个和第二个项已排序,则无需遍历其余值。迭代将终止,然后开始下一个,直到完成过程,如下面的冒泡排序示例所示。
优化通过以下步骤完成:
第一步)创建一个标志变量,用于监视内部循环中是否发生了任何交换。
第二步)如果值已交换位置,则继续下一个迭代。
第三步)如果值未交换位置,则终止内部循环,并继续外部循环。
优化的冒泡排序更有效,因为它只执行必要的步骤,并跳过不需要的步骤。
可视化表示
给定一个包含五个元素的列表,下图说明了冒泡排序在排序它们时如何遍历这些值。
下图显示了未排序的列表。

第一次迭代
步骤 1)
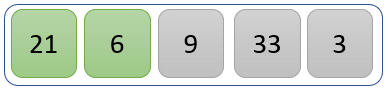
比较值 21 和 6,检查哪个值更大。
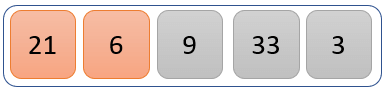
21 大于 6,因此 21 占据 6 的位置,而 6 占据 21 占据的位置。

我们修改后的列表现在看起来像上面。
步骤 2)
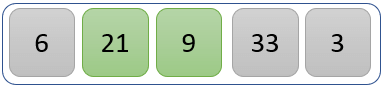
比较值 21 和 9。
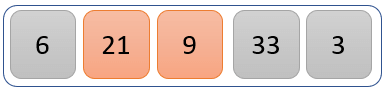
21 大于 9,因此我们交换 21 和 9 的位置。
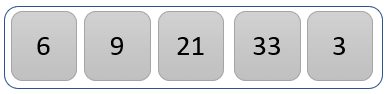
新列表现在如上。
步骤 3)
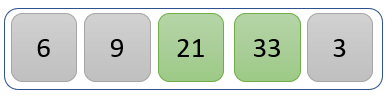
比较值 21 和 33,找出较大的值。
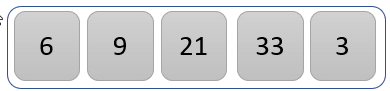
33 大于 21,因此不发生交换。
步骤 4)
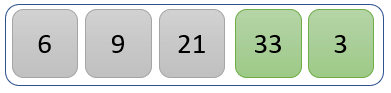
比较值 33 和 3,找出较大的值。
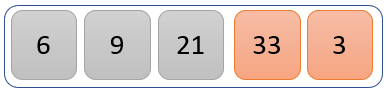
33 大于 3,因此我们交换它们的位置。
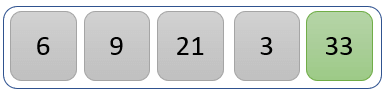
第一次迭代结束时排序后的列表如上。
第二次迭代
第二次迭代后的新列表如下:
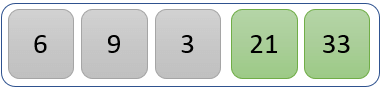
第三次迭代
第三次迭代后的新列表如下:

第四次迭代
第四次迭代后的新列表如下:
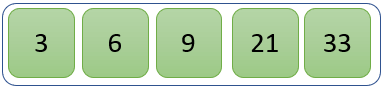
Python 示例
以下代码显示了如何在 Python 中实现冒泡排序算法。
def bubbleSort( theSeq ):
n = len( theSeq )
for i in range( n - 1 ) :
flag = 0
for j in range(n - 1) :
if theSeq[j] > theSeq[j + 1] :
tmp = theSeq[j]
theSeq[j] = theSeq[j + 1]
theSeq[j + 1] = tmp
flag = 1
if flag == 0:
break
return theSeq
el = [21,6,9,33,3]
result = bubbleSort(el)
print (result)
执行上述 Python 冒泡排序程序会产生以下结果:
[6, 9, 21, 3, 33]
代码解释
对 Python 冒泡排序程序代码的解释如下:
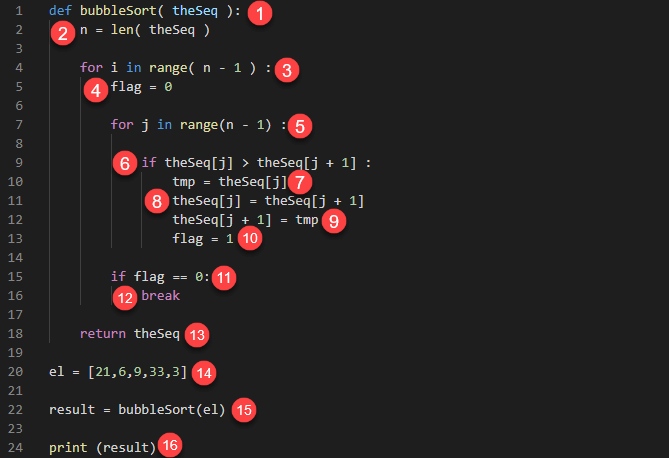
此处,
- 定义一个接受参数 theSeq 的 bubbleSort 函数。代码不输出任何内容。
- 获取数组的长度并将值赋给变量 n。代码不输出任何内容。
- 启动一个 for 循环,该循环运行冒泡排序算法 (n-1) 次。这是外部循环。代码不输出任何内容。
- 定义一个标志变量,用于确定是否发生了交换。这是为了优化目的。代码不输出任何内容。
- 启动内部循环,该循环将列表中的所有值从第一个比较到最后一个。代码不输出任何内容。
- 使用 if 语句检查左侧的值是否大于其右侧紧邻的值。代码不输出任何内容。
- 如果条件求值为 true,则将 theSeq[j] 的值赋给临时变量 tmp。代码不输出任何内容。
- 将 theSeq[j + 1] 的值赋给 theSeq[j] 的位置。代码不输出任何内容。
- 将变量 tmp 的值赋给 theSeq[j + 1] 的位置。代码不输出任何内容。
- 将标志变量赋值为 1,表示已发生交换。代码不输出任何内容。
- 使用 if 语句检查变量 flag 的值是否为 0。代码不输出任何内容。
- 如果值为 0,则调用 break 语句退出内部循环。
- 返回已排序的 theSeq 值。代码输出排序后的列表。
- 定义一个变量 el,其中包含一个随机数列表。代码不输出任何内容。
- 将 bubbleSort 函数的值赋给变量 result。
- 打印变量 result 的值。
冒泡排序的优点
以下是冒泡排序算法的一些优点:
- 易于理解。
- 当列表已排序或几乎排序时,它表现非常好。
- 它不需要大量的内存。
- 编写算法代码很容易。
- 与其他排序算法相比,空间要求极小。
冒泡排序的缺点
冒泡排序算法的一些缺点如下:
- 在排序大型列表时,其表现不佳。它需要大量的时间和资源。
- 它主要用于学术目的,而非实际应用。
- 对列表进行排序所需的步数约为 n2。
冒泡排序的复杂度分析
有三种类型的复杂度:
1)排序复杂度
排序复杂度用于表示对列表进行排序所需的执行时间和空间量。冒泡排序需要 (n-1) 次迭代来对列表进行排序,其中 n 是列表中元素的总数。
2)时间复杂度
冒泡排序的时间复杂度为 O(n2)。
时间复杂度可分为:
- 最坏情况:列表按降序提供。算法执行最大次数的执行,表示为 [大 O] O(n2)。
- 最佳情况:当提供的列表已排序时,这种情况发生。算法执行最少次数的执行,表示为 [大 Ω] Ω(n)。
- 平均情况:当列表为随机顺序时,这种情况发生。平均复杂度表示为 [大 θ] ⊝(n2)。
3)空间复杂度
空间复杂度衡量了对列表进行排序所需的额外空间量。冒泡排序仅需要一个额外的空间用于交换值的临时变量。因此,其空间复杂度为 O(1)。
摘要
- 冒泡排序算法通过比较两个相邻的值,如果左边的值小于右边的值,则交换它们。
- 使用 Python 实现冒泡排序算法相对简单。您只需要使用 for 循环和 if 语句。
- 冒泡排序算法解决的问题是将一个随机列表项转换为一个有序列表。
- 当列表已排序时,数据结构中的冒泡排序算法表现最佳,因为它执行的迭代次数最少。
- 当列表顺序颠倒时,冒泡排序算法的表现不佳。
- 冒泡排序的时间复杂度为 O(n2),空间复杂度为 O(1)。
- 冒泡排序算法最适合学术目的,不适合实际应用。
- 优化的冒泡排序通过跳过对已排序值的检查,从而提高了算法的效率。