R 聚合函数:Summarise & Group_by() 示例
对变量进行汇总对于了解数据很有帮助。虽然,按组汇总变量可以提供更好的数据分布信息。
在本教程中,您将学习如何使用 dplyr 库按组汇总数据集。
在本教程中,您将使用 batting 数据集。原始数据集包含 102816 个观测值和 22 个变量。您将只使用该数据集的 20%,并使用以下变量:
- playerID: 球员 ID 代码。因子
- yearID: 年份。因子
- teamID: 球队。因子
- lgID: 联盟。因子:AA AL FL NL PL UA
- AB: 打数。数值型
- G: 比赛:球员比赛场数。数值型
- R: 得分。数值型
- HR: 本垒打。数值型
- SH: 牺牲打。数值型
在执行汇总之前,您将执行以下步骤来准备数据:
- 步骤1: 导入数据
- 第 2 步:选择相关变量
- 第 3 步:对数据进行排序
library(dplyr)
# Step 1
data <- read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/lahman-batting.csv") % > %
# Step 2
select(c(playerID, yearID, AB, teamID, lgID, G, R, HR, SH)) % > %
# Step 3
arrange(playerID, teamID, yearID)
导入数据集时,使用 glimpse() 函数来了解数据集的结构是一个好习惯。
# Structure of the data glimpse(data)
输出
Observations: 104,324 Variables: 9 $ playerID <fctr> aardsda01, aardsda01, aardsda01, aardsda01, aardsda01, a... $ yearID <int> 2015, 2008, 2007, 2006, 2012, 2013, 2009, 2010, 2004, 196... $ AB <int> 1, 1, 0, 2, 0, 0, 0, 0, 0, 603, 600, 606, 547, 516, 495, ... $ teamID <fctr> ATL, BOS, CHA, CHN, NYA, NYN, SEA, SEA, SFN, ATL, ATL, A... $ lgID <fctr> NL, AL, AL, NL, AL, NL, AL, AL, NL, NL, NL, NL, NL, NL, ... $ G <int> 33, 47, 25, 45, 1, 43, 73, 53, 11, 158, 155, 160, 147, 15... $ R <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 117, 113, 84, 100, 103, 95, 75... $ HR <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 44, 39, 29, 44, 38, 47, 34, 40... $ SH <int> 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 6, ...
Summarise()
summarise() 的语法很简单,并且与 dplyr 库中包含的其他动词一致。
summarise(df, variable_name=condition) arguments: - `df`: Dataset used to construct the summary statistics - `variable_name=condition`: Formula to create the new variable
看看下面的代码:
summarise(data, mean_run =mean(R))
代码解释
- summarise(data, mean_run = mean(R)):创建一个名为 mean_run 的变量,它是数据集 data 中 run 列的平均值。
输出
## mean_run ## 1 19.20114
您可以根据需要添加任意数量的变量。您将返回平均比赛次数和平均牺牲打次数。
summarise(data, mean_games = mean(G),
mean_SH = mean(SH, na.rm = TRUE))
代码解释
- mean_SH = mean(SH, na.rm = TRUE):汇总第二个变量。您将 na.rm 设置为 TRUE,因为 SH 列包含缺失的观测值。
输出
## mean_games mean_SH ## 1 51.98361 2.340085
Group_by 与不 Group_by 的区别
没有 group_by() 的 summarise() 函数没有意义。它按组创建汇总统计信息。dplyr 库会在 group_by 动词内部自动将函数应用于您传递的组。
请注意,group_by 与所有其他动词(例如 mutate()、filter()、arrange() 等)都能完美配合。
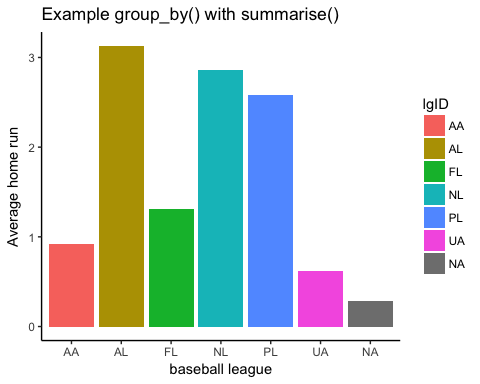
当您有多个步骤时,使用管道运算符很方便。您可以计算每个棒球联盟的平均本垒打数。
data % > % group_by(lgID) % > % summarise(mean_run = mean(HR))
代码解释
- data:用于构建汇总统计信息的 数据集
- group_by(lgID):按 `lgID` 变量分组来计算汇总
- summarise(mean_run = mean(HR)):计算平均本垒打数
输出
## # A tibble: 7 x 2 ## lgID mean_run ## <fctr> <dbl> ## 1 AA 0.9166667 ## 2 AL 3.1270988 ## 3 FL 1.3131313 ## 4 NL 2.8595953 ## 5 PL 2.5789474 ## 6 UA 0.6216216 ## 7 <NA> 0.2867133
管道运算符同样适用于 ggplot()。您可以轻松地使用图形显示汇总统计信息。所有步骤都通过管道传递,直到图形绘制完成。使用条形图可视化每个联盟的平均本垒打数似乎更直观。以下代码展示了将 group_by()、summarise() 和 ggplot() 结合使用的强大功能。
您将执行以下步骤:
- 步骤 1:选择数据框
- 步骤 2:分组数据
- 步骤 3:汇总数据
- 步骤 4:绘制汇总统计信息
library(ggplot2)
# Step 1
data % > %
#Step 2
group_by(lgID) % > %
#Step 3
summarise(mean_home_run = mean(HR)) % > %
#Step 4
ggplot(aes(x = lgID, y = mean_home_run, fill = lgID)) +
geom_bar(stat = "identity") +
theme_classic() +
labs(
x = "baseball league",
y = "Average home run",
title = paste(
"Example group_by() with summarise()"
)
)
输出
Summarise() 中的函数
summarise() 动词几乎兼容 R 中的所有函数。以下是您可以与 summarise() 一起使用的有用函数列表:
| 目标 | 函数 | 描述 |
|---|---|---|
| 基础版 | mean() | 向量 x 的平均值 |
| median() | 向量 x 的中位数 | |
| sum() | 向量 x 的总和 | |
| 方差 | sd() | 向量 x 的标准差 |
| IQR() | 向量 x 的四分位距 | |
| 范围 | min() | 向量 x 的最小值 |
| max() | 向量 x 的最大值 | |
| quantile() | 向量 x 的分位数 | |
| 职位 | first() | 与 group_by() 一起使用。组的第一个观测值 |
| last() | 与 group_by() 一起使用。组的最后一个观测值 | |
| nth() | 与 group_by() 一起使用。组的第 n 个观测值 | |
| Count (计数) | n() | 与 group_by() 一起使用。计算行数 |
| n_distinct() | 与 group_by() 一起使用。计算不同观测值的数量 |
我们将看到表 1 中每个函数的示例。
基本函数
在前面的示例中,您没有将汇总统计信息存储在数据框中。
您可以分两步从摘要生成数据框:
- 步骤 1:存储数据框以供后续使用
- 步骤 2:使用数据集创建折线图
步骤 1)计算每年平均比赛场次。
## Mean ex1 <- data % > % group_by(yearID) % > % summarise(mean_game_year = mean(G)) head(ex1)
代码解释
- batting 数据集的汇总统计信息存储在数据框 ex1 中。
输出
## # A tibble: 6 x 2 ## yearID mean_game_year ## <int> <dbl> ## 1 1871 23.42308 ## 2 1872 18.37931 ## 3 1873 25.61538 ## 4 1874 39.05263 ## 5 1875 28.39535 ## 6 1876 35.90625
步骤 2)使用折线图显示汇总统计信息并查看趋势。
# Plot the graph
ggplot(ex1, aes(x = yearID, y = mean_game_year)) +
geom_line() +
theme_classic() +
labs(
x = "Year",
y = "Average games played",
title = paste(
"Average games played from 1871 to 2016"
)
)
输出
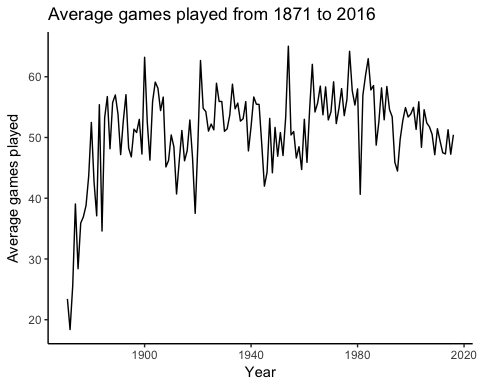
子集
summarise() 函数兼容子集操作。
## Subsetting + Median data % > % group_by(lgID) % > % summarise(median_at_bat_league = median(AB), #Compute the median without the zero median_at_bat_league_no_zero = median(AB[AB > 0]))
代码解释
- median_at_bat_league_no_zero = median(AB[AB > 0]):AB 变量包含大量的 0。您可以比较包含 0 和不包含 0 的“打数”变量的中位数。
输出
## # A tibble: 7 x 3 ## lgID median_at_bat_league median_at_bat_league_no_zero ## <fctr> <dbl> <dbl> ## 1 AA 130 131 ## 2 AL 38 85 ## 3 FL 88 97 ## 4 NL 56 67 ## 5 PL 238 238 ## 6 UA 35 35 ## 7 <NA> 101 101
求和
另一个有用的聚合变量的函数是 sum()。
您可以检查哪个联盟的本垒打数最多。
## Sum data % > % group_by(lgID) % > % summarise(sum_homerun_league = sum(HR))
输出
## # A tibble: 7 x 2 ## lgID sum_homerun_league ## <fctr> <int> ## 1 AA 341 ## 2 AL 29426 ## 3 FL 130 ## 4 NL 29817 ## 5 PL 98 ## 6 UA 46 ## 7 <NA> 41
标准差
数据中的离散度使用标准差或 R 中的 sd() 计算。
# Spread data % > % group_by(teamID) % > % summarise(sd_at_bat_league = sd(HR))
输出
## # A tibble: 148 x 2 ## teamID sd_at_bat_league ## <fctr> <dbl> ## 1 ALT NA ## 2 ANA 8.7816395 ## 3 ARI 6.0765503 ## 4 ATL 8.5363863 ## 5 BAL 7.7350173 ## 6 BFN 1.3645163 ## 7 BFP 0.4472136 ## 8 BL1 0.6992059 ## 9 BL2 1.7106757 ## 10 BL3 1.0000000 ## # ... with 138 more rows
每个球队的本垒打数量存在很大的不平等。
最大值和最小值
您可以使用 min() 和 max() 函数访问向量的最小值和最大值。
下面的代码返回了球员在一季中最少和最多的比赛次数。
# Min and max
data % > %
group_by(playerID) % > %
summarise(min_G = min(G),
max_G = max(G))
输出
## # A tibble: 10,395 x 3 ## playerID min_G max_G ## <fctr> <int> ## 1 aardsda01 53 73 ## 2 aaronha01 120 156 ## 3 aasedo01 24 66 ## 4 abadfe01 18 18 ## 5 abadijo01 11 11 ## 6 abbated01 3 153 ## 7 abbeybe01 11 11 ## 8 abbeych01 80 132 ## 9 abbotgl01 5 23 ## 10 abbotji01 13 29 ## # ... with 10,385 more rows
Count (计数)
按组计算观测值数量总是一个好主意。在 R 中,您可以使用 n() 来汇总出现次数。
例如,下面的代码计算了每位球员的比赛年数。
# count observations data % > % group_by(playerID) % > % summarise(number_year = n()) % > % arrange(desc(number_year))
输出
## # A tibble: 10,395 x 2 ## playerID number_year ## <fctr> <int> ## 1 pennohe01 11 ## 2 joosted01 10 ## 3 mcguide01 10 ## 4 rosepe01 10 ## 5 davisha01 9 ## 6 johnssi01 9 ## 7 kaatji01 9 ## 8 keelewi01 9 ## 9 marshmi01 9 ## 10 quirkja01 9 ## # ... with 10,385 more rows
第一个和最后一个
您可以选择组的第一个、最后一个或第 n 个位置。
例如,您可以找出每位球员的第一年和最后一年。
# first and last data % > % group_by(playerID) % > % summarise(first_appearance = first(yearID), last_appearance = last(yearID))
输出
## # A tibble: 10,395 x 3 ## playerID first_appearance last_appearance ## <fctr> <int> <int> ## 1 aardsda01 2009 2010 ## 2 aaronha01 1973 1975 ## 3 aasedo01 1986 1990 ## 4 abadfe01 2016 2016 ## 5 abadijo01 1875 1875 ## 6 abbated01 1905 1897 ## 7 abbeybe01 1894 1894 ## 8 abbeych01 1895 1897 ## 9 abbotgl01 1973 1979 ## 10 abbotji01 1992 1996 ## # ... with 10,385 more rows
第 n 个观测值
nth() 函数是对 first() 和 last() 的补充。您可以使用索引来访问组内的第 n 个观测值。
例如,您可以仅筛选球队比赛的第二年。
# nth data % > % group_by(teamID) % > % summarise(second_game = nth(yearID, 2)) % > % arrange(second_game)
输出
## # A tibble: 148 x 2 ## teamID second_game ## <fctr> <int> ## 1 BS1 1871 ## 2 CH1 1871 ## 3 FW1 1871 ## 4 NY2 1871 ## 5 RC1 1871 ## 6 BR1 1872 ## 7 BR2 1872 ## 8 CL1 1872 ## 9 MID 1872 ## 10 TRO 1872 ## # ... with 138 more rows
不同观测值的数量
n() 函数返回当前组中的观测值数量。与 n() 类似的是 n_distinct(),它计算唯一值的数量。
在下一个示例中,我们将计算球队在所有时期招募的球员总数。
# distinct values data % > % group_by(teamID) % > % summarise(number_player = n_distinct(playerID)) % > % arrange(desc(number_player))
代码解释
- group_by(teamID):按年份和球队分组
- summarise(number_player = **n_distinct**(playerID)):按球队计算不同的球员数量
- arrange(desc(number_player)):按球员数量对数据进行排序
输出
## # A tibble: 148 x 2 ## teamID number_player ## <fctr> <int> ## 1 CHN 751 ## 2 SLN 729 ## 3 PHI 699 ## 4 PIT 683 ## 5 CIN 679 ## 6 BOS 647 ## 7 CLE 646 ## 8 CHA 636 ## 9 DET 623 ## 10 NYA 612 ## # ... with 138 more rows
多组
可以在多个组之间进行汇总统计。
# Multiple groups data % > % group_by(yearID, teamID) % > % summarise(mean_games = mean(G)) % > % arrange(desc(teamID, yearID))
代码解释
- group_by(yearID, teamID):按年份和球队分组
- summarise(mean_games = mean(G)):汇总比赛场数
- arrange(desc(teamID, yearID)):按球队和年份对数据进行排序
输出
## # A tibble: 2,829 x 3 ## # Groups: yearID [146] ## yearID teamID mean_games ## <int> <fctr> <dbl> ## 1 1884 WSU 20.41667 ## 2 1891 WS9 46.33333 ## 3 1886 WS8 22.00000 ## 4 1887 WS8 51.00000 ## 5 1888 WS8 27.00000 ## 6 1889 WS8 52.42857 ## 7 1884 WS7 8.00000 ## 8 1875 WS6 14.80000 ## 9 1873 WS5 16.62500 ## 10 1872 WS4 4.20000 ## # ... with 2,819 more rows
过滤
在执行操作之前,您可以过滤数据集。数据集始于 1871 年,分析不需要 1980 年之前的年份。
# Filter data % > % filter(yearID > 1980) % > % group_by(yearID) % > % summarise(mean_game_year = mean(G))
代码解释
- filter(yearID > 1980):过滤数据,只显示相关年份(即 1980 年之后)
- group_by(yearID):按年份分组
- summarise(mean_game_year = mean(G)):汇总数据
输出
## # A tibble: 36 x 2 ## yearID mean_game_year ## <int> <dbl> ## 1 1981 40.64583 ## 2 1982 56.97790 ## 3 1983 60.25128 ## 4 1984 62.97436 ## 5 1985 57.82828 ## 6 1986 58.55340 ## 7 1987 48.74752 ## 8 1988 52.57282 ## 9 1989 58.16425 ## 10 1990 52.91556 ## # ... with 26 more rows
取消分组
最后但同样重要的是,您需要在更改计算级别之前删除分组。
# Ungroup the data data % > % filter(HR > 0) % > % group_by(playerID) % > % summarise(average_HR_game = sum(HR) / sum(G)) % > % ungroup() % > % summarise(total_average_homerun = mean(average_HR_game))
代码解释
- filter(HR >0) : 排除零本垒打
- group_by(playerID):按球员分组
- summarise(average_HR_game = sum(HR)/sum(G)):计算每位球员的平均本垒打数
- ungroup():删除分组
- summarise(total_average_homerun = mean(average_HR_game)):汇总数据
输出
## # A tibble: 1 x 1 ## total_average_homerun ## <dbl> ## 1 0.06882226
摘要
当您想按组返回汇总时,您可以使用
# group by X1, X2, X3 group(df, X1, X2, X3)
您需要使用以下方法取消分组数据:
ungroup(df)
下表总结了您通过 summarise() 学到的函数:
| 方法 | 函数 | 代码 |
|---|---|---|
| 平均值 | 平均值 |
summarise(df,mean_x1 = mean(x1)) |
| 中位数 | 中位数 |
summarise(df,median_x1 = median(x1)) |
| 总和 | 总和 |
summarise(df,sum_x1 = sum(x1)) |
| 标准差 | sd |
summarise(df,sd_x1 = sd(x1)) |
| 四分位距 | IQR |
summarise(df,interquartile_x1 = IQR(x1)) |
| 最小值 | min |
summarise(df,minimum_x1 = min(x1)) |
| 最大值 | max |
summarise(df,maximum_x1 = max(x1)) |
| 分位数 | 分位数 |
summarise(df,quantile_x1 = quantile(x1)) |
| 第一个观测值 | first |
summarise(df,first_x1 = first(x1)) |
| 最后一个观测值 | last |
summarise(df,last_x1 = last(x1)) |
| 第 n 个观测值 | nth |
summarise(df,nth_x1 = nth(x1, 2)) |
| 出现次数 | n |
summarise(df,n_x1 = n(x1)) |
| 不同出现次数 | n_distinct |
summarise(df,n_distinct _x1 = n_distinct(x1)) |