Selenium 中的定位器
什么是定位器?
定位器是告诉 Selenium IDE 需要操作哪个 GUI 元素(如文本框、按钮、复选框等)的命令。正确识别 GUI 元素是创建自动化脚本的先决条件。但是,准确识别 GUI 元素比听起来更难。有时,您最终会使用不正确的 GUI 元素或根本没有元素!因此,Selenium 提供了许多定位器来精确地定位 GUI 元素
有些命令不需要定位器(例如“open”命令)。但是,大多数命令确实需要 Selenium WebDriver 中的元素定位器。
定位器的选择主要取决于您的被测应用程序。在本教程中,我们将根据 Facebook 和 new tours.demoaut 支持的定位器在这两者之间切换。同样,在您的测试项目中,您将根据您的应用程序支持选择上述任何一个 Selenium WebDriver 中的元素定位器。
通过 ID 定位
这是最常见的元素定位方式,因为 ID 对于每个元素都应该是唯一的。
目标格式:id=元素的 id
在此示例中,我们将使用 Facebook 作为我们的测试应用程序,因为 Mercury Tours 不使用 ID 属性。
步骤 1) 自本教程创建以来,Facebook 已更改其登录页面设计。请使用此演示页面 https://demo.guru99.com/test/facebook.html 进行测试。使用 Firebug 检查“电子邮件或电话”文本框并记下其 ID。在此示例中,ID 为“email”。
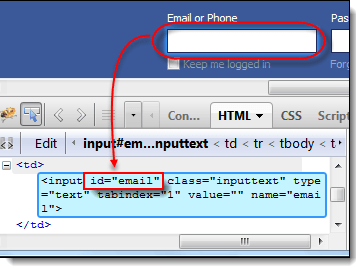
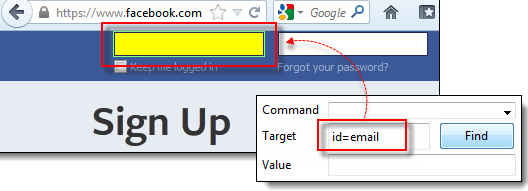
步骤 2) 启动 Selenium IDE 并在目标框中输入“id=email”。单击“查找”按钮并注意“电子邮件或电话”文本框变为黄色高亮显示并带有绿色边框,这意味着 Selenium IDE 能够正确找到该元素。
通过 Name 定位
通过名称定位元素与通过 ID 定位元素非常相似,只是我们使用“name=”前缀。
目标格式:name=元素的名称
在以下演示中,我们现在将使用 Mercury Tours,因为所有重要元素都具有名称。
步骤 1) 导航到 https://demo.guru99.com/test/newtours/ 并使用 Firebug 检查“用户名”文本框。记下其名称属性。
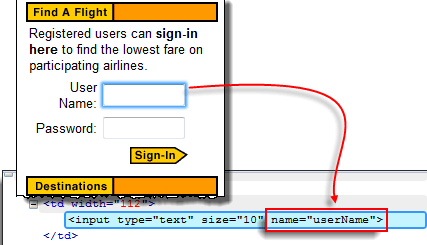
在这里,我们看到元素的名称是“userName”。
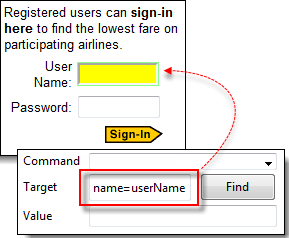
步骤 2) 在 Selenium IDE 中,在目标框中输入“name=userName”并单击“查找”按钮。Selenium IDE 应该能够通过高亮显示来定位用户名文本框。
如何使用过滤器通过 Name 定位元素
当多个元素具有相同的名称时,可以使用过滤器。过滤器是用于区分具有相同名称的元素的附加属性。
目标格式: name=元素名称 filter=过滤器值
让我们看一个例子 –
步骤 1) 登录 Mercury Tours。
使用“tutorial”作为用户名和密码登录 Mercury Tours。它应该会带您到如下所示的航班查找页面。
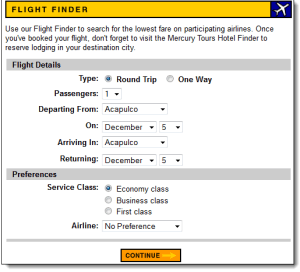
步骤 2) 使用 Firebug 使用 VALUE 属性。
使用 Firebug,请注意往返和单程单选按钮具有相同的名称“tripType”。但是,它们具有不同的 VALUE 属性,因此我们可以将它们中的每一个用作过滤器。
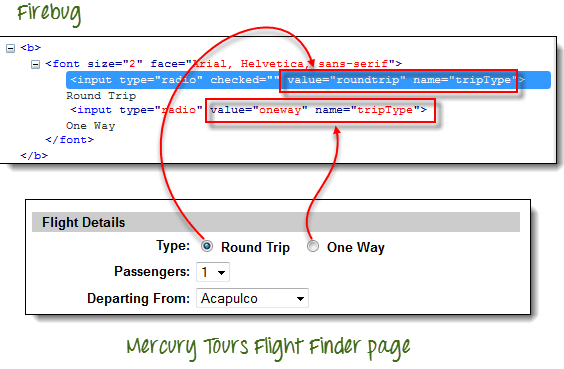
步骤 3) 点击第一行。
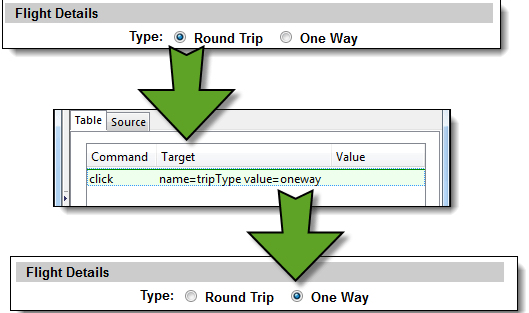
- 我们将首先访问“单程”单选按钮。单击编辑器中的第一行。
- 在 Selenium IDE 的命令框中,输入命令“click”。
- 在目标框中,输入“name=tripType value=oneway”。“value=oneway”部分是我们的过滤器。
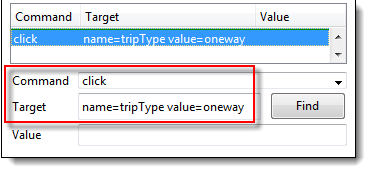
步骤 4) 点击“查找”按钮。
请注意,Selenium IDE 能够用绿色高亮显示“单程”单选按钮——这意味着我们能够成功使用其 VALUE 属性访问该元素。
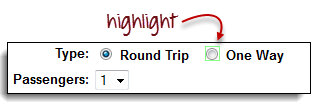
步骤 5) 选择“单程”单选按钮。
按下键盘上的“X”键执行此点击命令。注意“单程”单选按钮被选中。
您可以使用“往返”单选按钮执行完全相同的操作,这次将“name=tripType value=roundtrip”作为目标。
通过链接文本定位
这种 Selenium 中的 CSS 定位器仅适用于超链接文本。我们通过在目标前加上“link=”前缀,然后是超链接文本来访问链接。
目标格式: link=链接文本
在此示例中,我们将访问 Mercury Tours 主页上的“REGISTER”链接。
步骤 1)
- 首先,请确保您已从 Mercury Tours 注销。
- 前往 Mercury Tours 主页。
步骤 2)
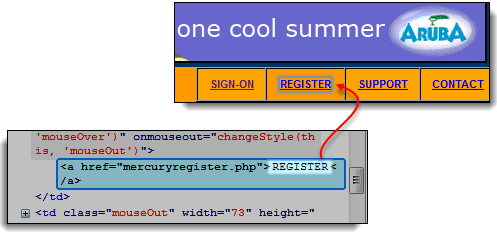
- 使用 Firebug 检查“REGISTER”链接。链接文本位于 和 标签之间。
- 在这种情况下,我们的链接文本是“REGISTER”。复制链接文本。
步骤 3) 复制 Firebug 中的链接文本并将其粘贴到 Selenium IDE 的目标框中。在其前面加上“link=”。
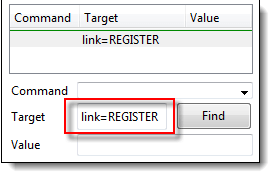
步骤 4) 点击“查找”按钮,注意 Selenium IDE 能够正确高亮显示 REGISTER 链接。

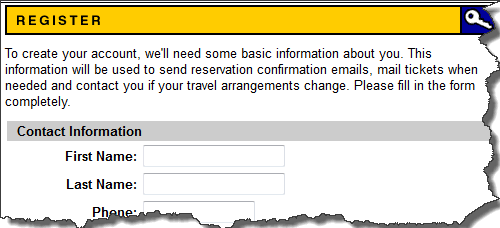
步骤 5) 为了进一步验证,在命令框中输入“clickAndWait”并执行。Selenium IDE 应该能够成功点击该 REGISTER 链接,并带您进入如下所示的注册页面。
通过 DOM(文档对象模型)定位
文档对象模型 (DOM),简单来说,是 HTML 元素结构化方式。Selenium IDE 能够使用 DOM 访问页面元素。如果我们使用此方法,我们的目标框将始终以“dom=document…”开头;然而,“dom=”前缀通常被删除,因为 Selenium IDE 能够自动将任何以关键字“document”开头的内容解释为 Selenium 中 DOM 内的路径。
在 Selenium 中通过 DOM 定位元素有四种基本方法
- getElementById
- getElementsByName
- dom:name(仅适用于命名表单中的元素)
- dom:index
通过 DOM – getElementById 定位
让我们关注第一种方法——在 Selenium 中使用 DOM 的 getElementById 方法。语法将是
语法
document.getElementById("元素的id")
- 元素的 id = 这是要访问的元素的 ID 属性的值。此值应始终用一对括号 (“”) 括起来。
步骤 1) 使用此演示页面 https://demo.guru99.com/test/facebook.html 导航到它并使用 Firebug 检查“保持登录”复选框。记下其 ID。
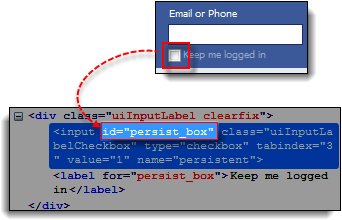
我们可以看到应该使用的 ID 是“persist_box”。
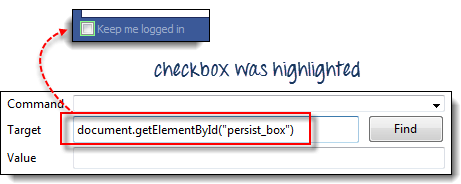
步骤 2) 打开 Selenium IDE 并在目标框中输入“document.getElementById(“persist_box”)”并点击查找。Selenium IDE 应该能够找到“保持登录”复选框。尽管它无法突出显示复选框的内部,但 Selenium IDE 仍然可以用亮绿色边框包围该元素,如下所示。
通过 DOM – getElementsByName 定位
getElementById 方法一次只能访问一个元素,即您指定的 ID 的元素。getElementsByName 方法则不同。它收集一个具有您指定的名称的元素数组。您可以使用从 0 开始的索引访问单个元素。
|
|
getElementById
|
|
|
getElementsByName
|

语法
document.getElementsByName(“名称”)[索引]
- 名称 = 元素由其“名称”属性定义的名称
- 索引 = 一个整数,指示将使用 getElementsByName 数组中的哪个元素。
步骤 1) 导航到 Mercury Tours 的主页,并使用“tutorial”作为用户名和密码登录。Firefox 应该会带您进入航班查找屏幕。
步骤 2) 使用 Firebug 检查页面底部的三个单选按钮(经济舱、商务舱和头等舱单选按钮)。请注意,它们都具有相同的名称“servClass”。
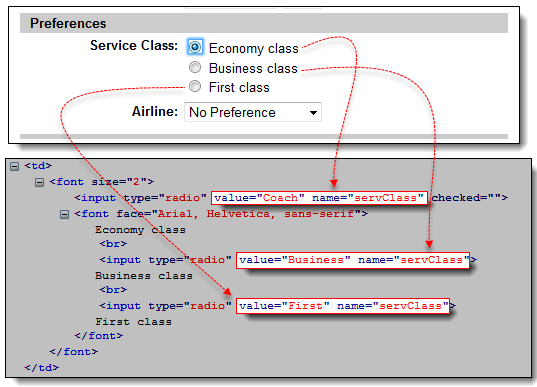
步骤 3) 我们首先访问“经济舱”单选按钮。在这三个单选按钮中,此元素排在第一位,因此其索引为 0。在 Selenium IDE 中,键入“document.getElementsByName(“servClass”)[0]”并单击“查找”按钮。Selenium IDE 应该能够正确识别经济舱单选按钮。
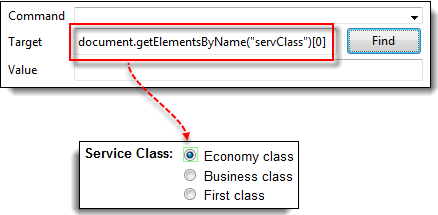
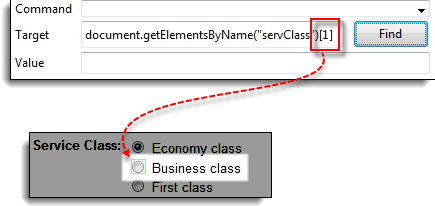
步骤 4) 将索引号更改为 1,这样您的目标将变为 document.getElementsByName(“servClass”)[1]。单击“查找”按钮,Selenium IDE 应该能够高亮显示“商务舱”单选按钮,如下所示。
通过 DOM – dom:name 定位
如前所述,此方法仅适用于您正在访问的元素包含在命名表单中。
语法
document.forms[“表单名称”].elements[“元素名称”]
- 表单名称 = 包含您要访问的元素的表单标签的 name 属性值
- 元素名称 = 您希望访问的元素的名称属性值
步骤 1) 导航到 Mercury Tours 主页 https://demo.guru99.com/test/newtours/ 并使用 Firebug 检查用户名文本框。请注意,它包含在一个名为“home”的表单中。
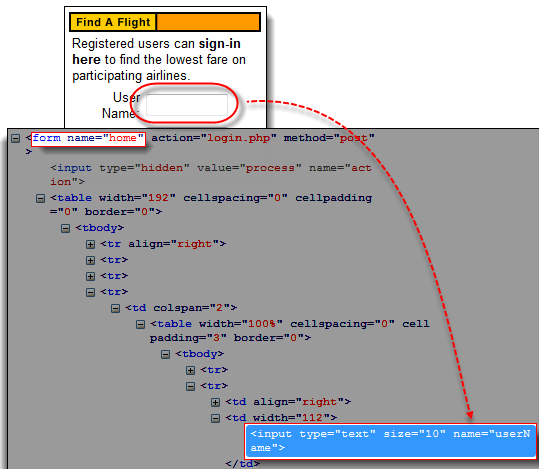
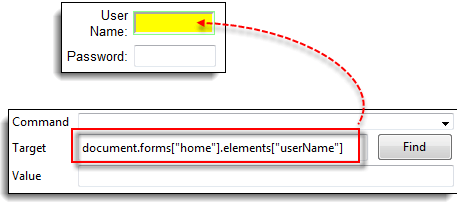
步骤 2) 在 Selenium IDE 中,输入“document.forms[“home”].elements[“userName”]”并单击“查找”按钮。Selenium IDE 必须能够成功访问该元素。
通过 DOM – dom:index 定位
此方法即使元素不在命名表单中也适用,因为它使用表单的索引而不是其名称。
语法
document.forms[表单索引].elements[元素索引]
- 表单索引 = 表单相对于整个页面的索引号(从 0 开始)
- 元素索引 = 元素相对于包含它的整个表单的索引号(从 0 开始)
我们将访问 Mercury Tours 注册页面中的“电话”文本框。该页面中的表单没有名称和 ID 属性,因此这将是一个很好的例子。
步骤 1) 导航到 Mercury Tours 注册页面并检查电话文本框。请注意,包含它的表单没有 ID 和名称属性。
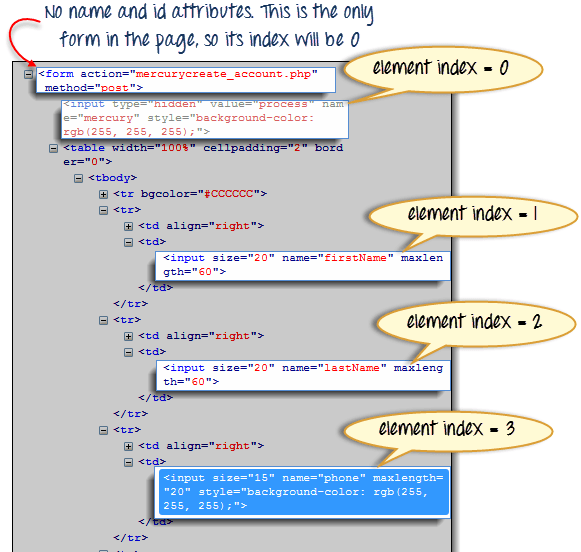
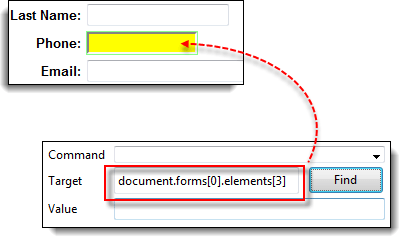
步骤 2) 在 Selenium IDE 的目标框中输入“document.forms[0].elements[3]”,然后单击“查找”按钮。Selenium IDE 应该能够正确访问电话文本框。
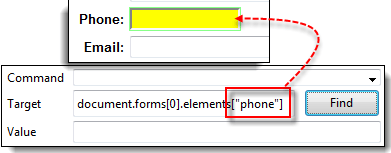
步骤 3) 或者,您可以使用元素的名称而不是其索引来获得相同的结果。在 Selenium IDE 的目标框中输入“document.forms[0].elements[“phone”]”。电话文本框仍然应该被高亮显示。
通过 XPath 定位
XPath 是用于定位 XML(可扩展标记语言)节点的语言。由于 HTML 可以被认为是 XML 的一种实现,我们也可以使用 XPath 来定位 HTML 元素。
- 优点: 它可以访问几乎任何元素,即使是没有类、名称或 ID 属性的元素。
- 缺点: 它是识别元素最复杂的方法,因为有太多不同的规则和注意事项。
幸运的是,Firebug 可以自动生成 XPath Selenium 定位器。在下面的示例中,我们将访问一个无法通过我们之前讨论的方法访问的图像。
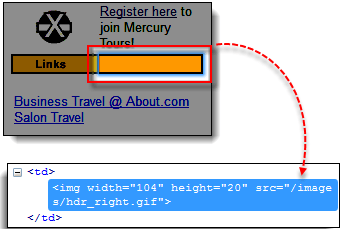
步骤 1) 导航到 Mercury Tours 主页并使用 Firebug 检查黄色“链接”框右侧的橙色矩形。请参考下图。
步骤 2) 右键单击元素的 HTML 代码,然后选择“复制 XPath”选项。
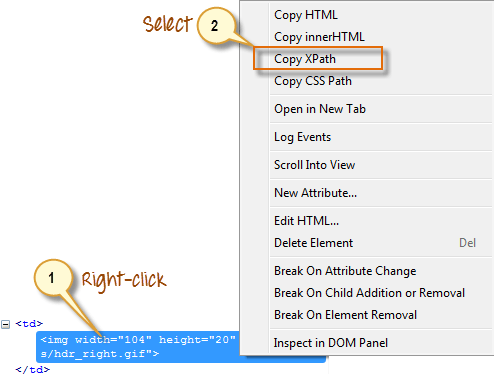
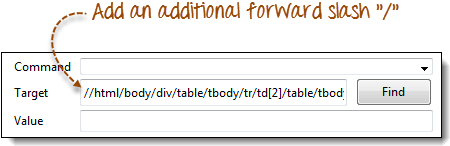
步骤 3) 在 Selenium IDE 中,在目标框中输入一个正斜杠“/”,然后粘贴我们在上一步中复制的 XPath。您目标框中的条目现在应该以两个正斜杠“//”开头。
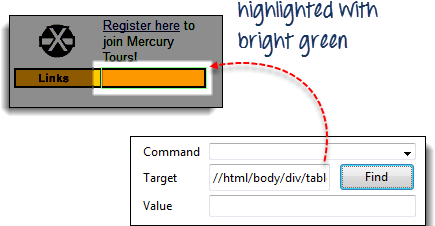
步骤 4) 点击“查找”按钮。Selenium IDE 应该能够高亮显示橙色框,如下所示。
摘要
定位器用法语法
| 方法 | 目标语法 | 示例 |
|---|---|---|
| 通过 ID | id= 元素的id | id=电子邮件 |
| 通过名称 | name=元素的名称 | name=用户名 |
| 使用过滤器按名称 | name=元素的名称 filter=过滤器值 | name=tripType value=oneway |
| 通过链接文本 | link=链接文本 | link=注册 |