Selenium 中的 XPath:教程
Selenium 中的 XPath 是什么?
Selenium 中的 XPath 是一种 XML 路径,用于通过页面的 HTML 结构进行导航。它是一种用于使用 XML 路径表达式查找网页上任何元素的语法或语言。XPath 可用于 HTML 和 XML 文档,通过 HTML DOM 结构查找网页上任何元素的位置。
在 Selenium 自动化中,如果元素无法通过 id、class、name 等通用定位器找到,则使用 XPath 来查找网页上的元素。
在本教程中,我们将学习 XPath 和不同的 XPath 表达式,以查找复杂或动态元素,这些元素的属性在刷新或任何操作时会动态更改。
XPath 语法
XPath 包含网页上元素的路徑。创建 XPath 的标准 XPath 语法是。
Xpath=//tagname[@attribute='value']
下面通过截图解释 Selenium 中 XPath 的基本格式。
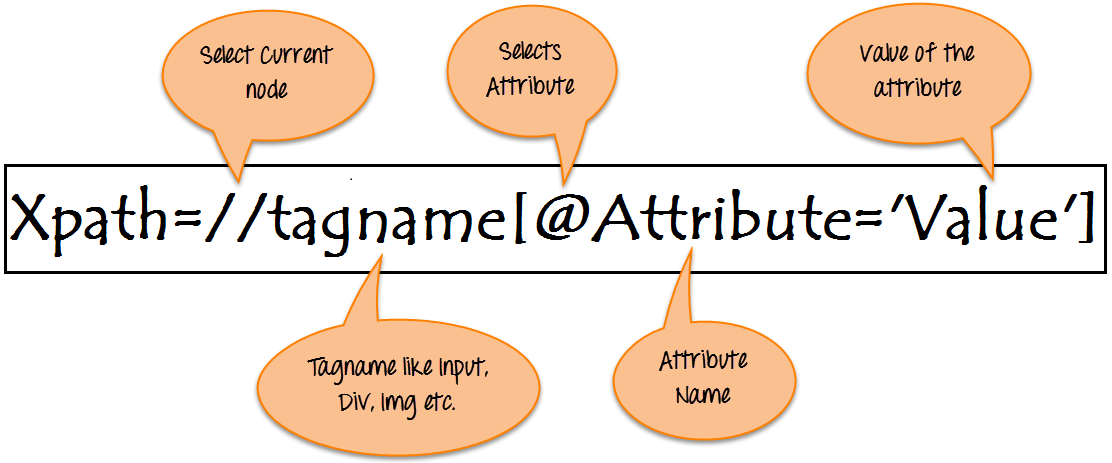
- // : 选择当前节点。
- 标签名: 特定节点的标签名。
- @: 选择属性。
- 属性: 节点的属性名称。
- 值: 属性的值。
为了准确地在网页上查找元素,有不同类型的定位器
| XPath 定位器 | 在网页上查找不同的元素 |
|---|---|
| ID | 通过元素的 ID 查找元素 |
| 类名 | 通过元素的类名查找元素 |
| 名称 | 通过元素的名称查找元素 |
| 链接文本 | 通过链接的文本查找元素 |
| XPath | 查找动态元素并在网页的各种元素之间遍历所需的 XPath |
| CSS 路径 | CSS 路径也定位没有名称、类或 ID 的元素。 |
XPath 的类型
XPath 有两种类型
1) 绝对 XPath
2) 相对 XPath
绝对 XPath
这是查找元素的直接方式,但绝对 XPath 的缺点是,如果元素的路径发生任何更改,则该 XPath 将失效。
XPath 的关键特征是它以单个正斜杠 (/) 开头,这意味着您可以从根节点选择元素。
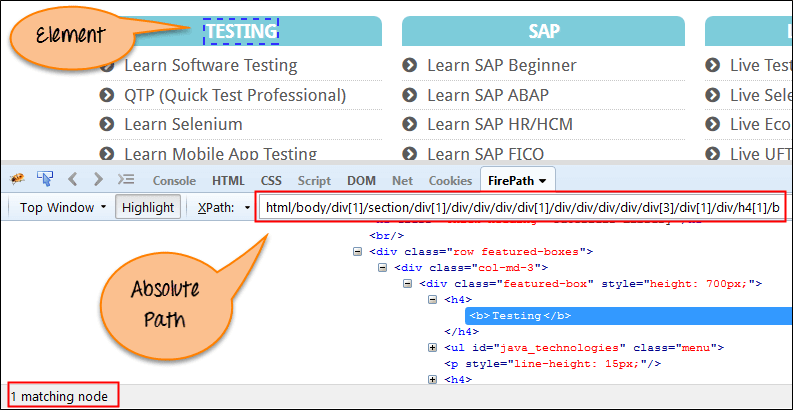
以下是屏幕中所示元素的绝对 XPath 表达式的示例。
注意:您可以在此页面上练习以下 XPath 练习 https://demo.guru99.com/test/selenium-xpath.html
如果视频无法访问,请点击此处
绝对 XPath
/html/body/div[2]/div[1]/div/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]/b[1]
相对 XPath
相对 XPath 从 HTML DOM 结构的中间开始。它以双正斜杠 (//) 开头。它可以在网页上的任何位置搜索元素,这意味着无需编写冗长的 XPath,您可以从 HTML DOM 结构的中间开始。相对 XPath 总是首选,因为它不是从根元素的完整路径。
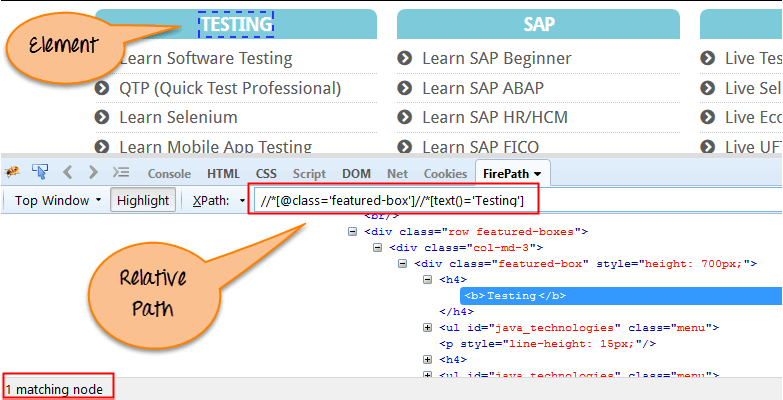
以下是屏幕中所示相同元素的相对 XPath 表达式的示例。这是通过 XPath 查找元素的常用格式。
如果视频无法访问,请点击此处
相对 XPath://div[@class='featured-box cloumnsize1']//h4[1]//b[1]
什么是 XPath 轴。
XPath 轴从当前上下文节点在 XML 文档中搜索不同的节点。XPath 轴是用于查找动态元素的方法,否则无法通过没有 ID、类名、名称等的普通 XPath 方法找到。Selenium 中的 XPath 包括多种方法,例如 Contains、AND、Absolute XPath 和 Relative XPath,用于根据各种属性和条件识别和定位动态元素。
轴方法用于查找那些在刷新或任何其他操作时动态更改的元素。在 Selenium Webdriver 中常用的一些轴方法包括 child、parent、ancestor、sibling、preceding、self 等。
如何在 Selenium WebDriver 中编写动态 XPath
1) 基本 XPath
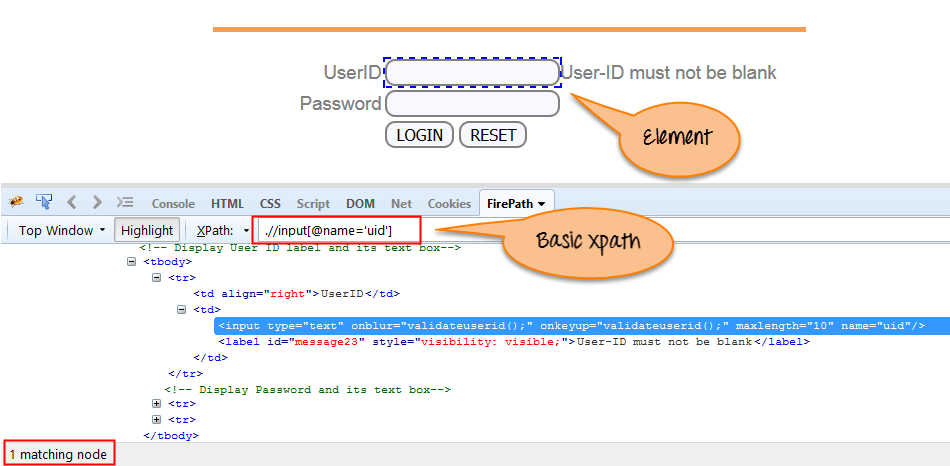
XPath 表达式根据 XML 文档中的属性(如 ID、名称、类名等)选择节点或节点列表,如下所示。
Xpath=//input[@name='uid']
这里是访问页面的链接 https://demo.guru99.com/test/selenium-xpath.html
更多基本 xpath 表达式
Xpath=//input[@type='text'] Xpath=//label[@id='message23'] Xpath=//input[@value='RESET'] Xpath=//*[@class='barone'] Xpath=//a[@href='https://demo.guru99.com/'] Xpath=//img[@src='//guru99.com/images/home/java.png']
2) Contains()
Contains() 是 XPath 表达式中使用的一种方法。当任何属性的值动态更改时使用,例如登录信息。
contains 功能能够使用部分文本查找元素,如下面的 XPath 示例所示。
在此示例中,我们尝试仅使用属性的部分文本值来识别元素。在下面的 XPath 表达式中,部分值“sub”用于代替提交按钮。可以看出,该元素已成功找到。
“Type”的完整值是“submit”,但仅使用部分值“sub”。
Xpath=//*[contains(@type,'sub')]
“name”的完整值是“btnLogin”,但仅使用部分值“btn”。
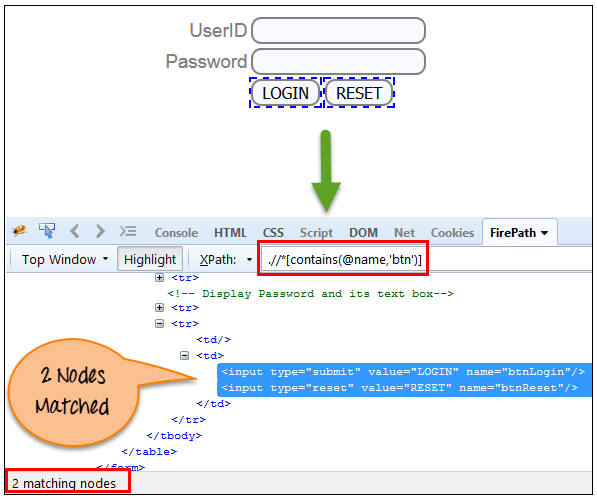
Xpath=//*[contains(@name,'btn')]
在上述表达式中,我们已将“name”作为属性,将“btn”作为部分值,如以下屏幕截图所示。这将找到 2 个元素(LOGIN 和 RESET),因为它们的“name”属性以“btn”开头。
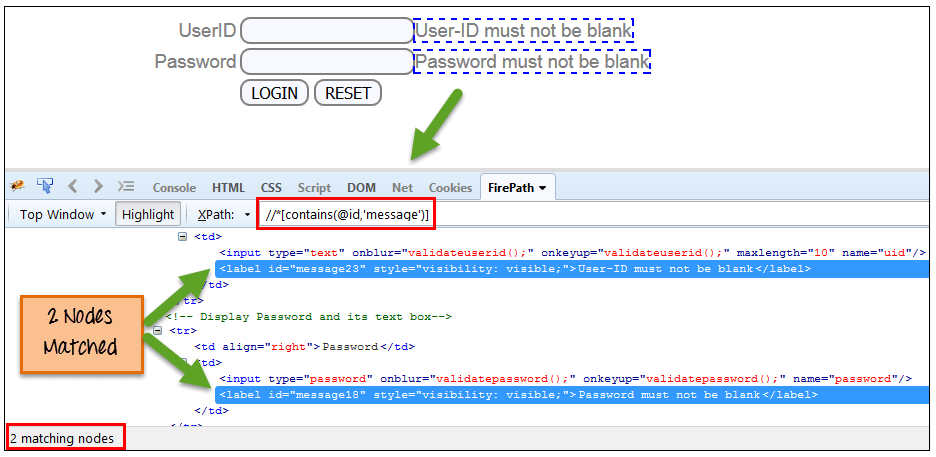
同样,在下面的表达式中,我们已将“id”作为属性,将“message”作为部分值。这将找到 2 个元素(“用户 ID 不能为空”和“密码不能为空”),因为它们的“id”属性以“message”开头。
Xpath=//*[contains(@id,'message')]
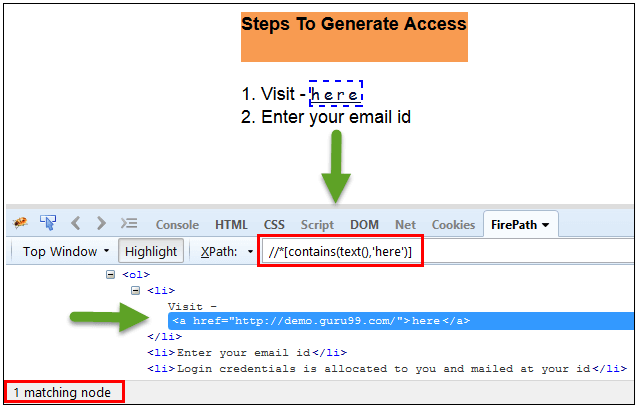
在下面的表达式中,我们已将链接的“文本”作为属性,将“here”作为部分值,如以下屏幕截图所示。这将找到链接(“here”),因为它显示文本“here”。
Xpath=//*[contains(text(),'here')]
Xpath=//*[contains(@href,'guru99.com')]
3) 使用 OR 和 AND
在 OR 表达式中,使用两个条件,第一个条件或第二个条件应为真。如果任何一个条件为真或两个条件都为真,它也适用。这意味着任何一个条件都应为真才能找到元素。
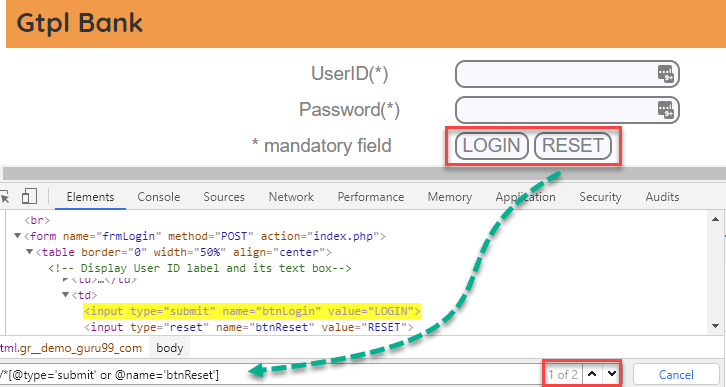
在下面的 XPath 表达式中,它标识了其单个或两个条件都为真的元素。
Xpath=//*[@type='submit' or @name='btnReset']
突出显示两个元素,“LOGIN”元素具有属性“type”,“RESET”元素具有属性“name”。
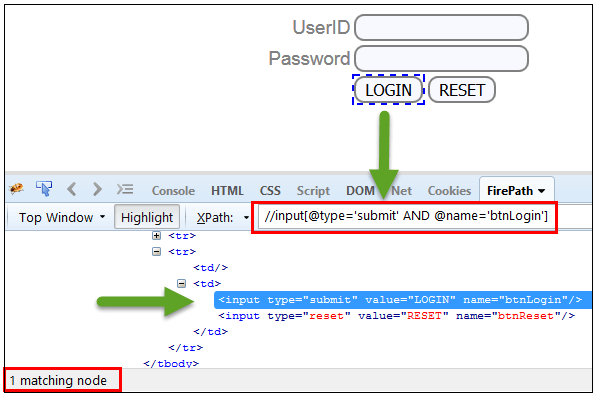
在 AND 表达式中,使用两个条件,两个条件都必须为真才能找到元素。如果任何一个条件为假,它就无法找到元素。
Xpath=//input[@type='submit' and @name='btnLogin']
在下面的表达式中,突出显示“LOGIN”元素,因为它同时具有“type”和“name”属性。
4) XPath Starts-with
XPath starts-with() 是一个用于查找属性值在刷新或网页上其他动态操作时会更改的 Web 元素的功能。在此方法中,属性的起始文本与要查找的属性值动态更改的元素匹配。您还可以查找属性值为静态(不更改)的元素。
例如 -:假设特定元素的 ID 动态更改,例如
Id=” message12″
Id=” message345″
Id=” message8769″
等等.. 但初始文本是相同的。在这种情况下,我们使用 Start-with 表达式。
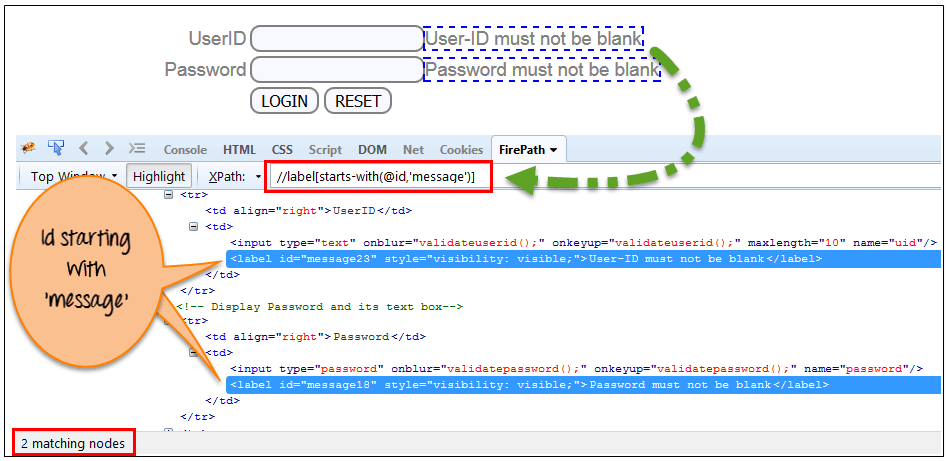
在下面的表达式中,有两个元素的 ID 以“message”开头(即“用户 ID 不能为空”和“密码不能为空”)。在下面的示例中,XPath 查找那些“ID”以“message”开头的元素。
Xpath=//label[starts-with(@id,'message')]
5) XPath Text() 函数
XPath text() 函数是 Selenium WebDriver 的内置函数,用于根据 Web 元素的文本定位元素。它有助于查找精确的文本元素,并在文本节点集中定位元素。要定位的元素应为字符串形式。
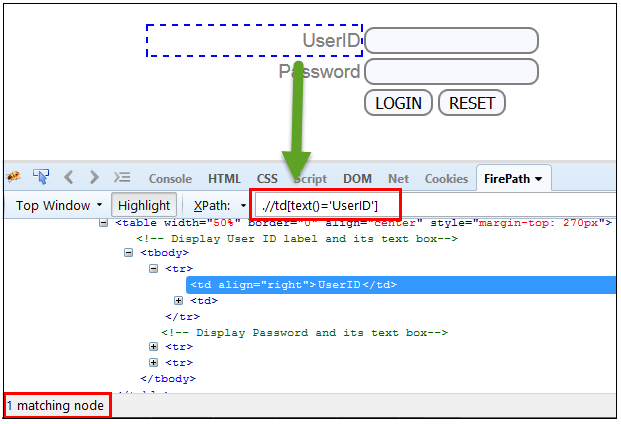
在此表达式中,使用 text 函数,我们查找与精确文本匹配的元素,如下所示。在我们的例子中,我们查找文本为“UserID”的元素。
Xpath=//td[text()='UserID']
XPath 轴方法
这些 XPath 轴方法用于查找复杂或动态元素。下面我们将看到其中一些方法。
为了说明这些 XPath 轴方法,我们将使用 Guru99 银行演示网站。
1) Following(后续)
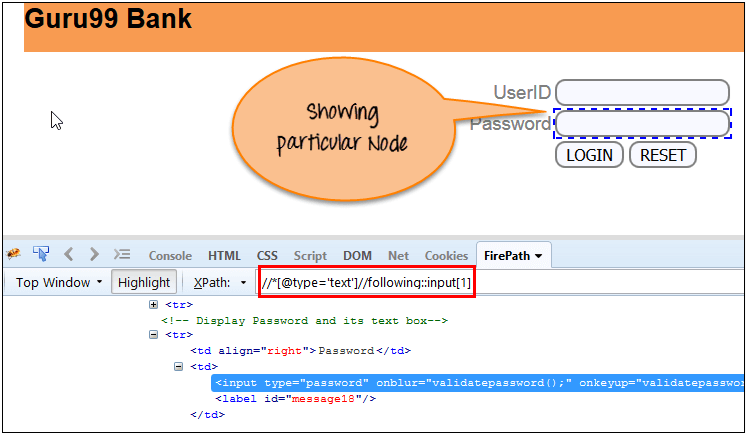
选择当前节点 ( ) [用户 ID 输入框是当前节点] 的文档中的所有元素,如以下屏幕所示。
Xpath=//*[@type='text']//following::input
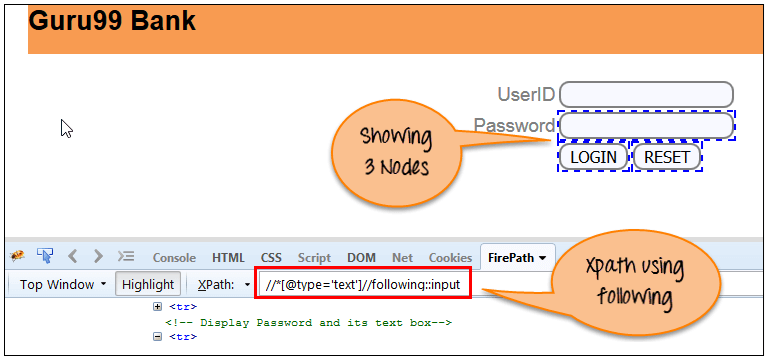
通过使用“following”轴,有 3 个“input”节点匹配——密码、登录和重置按钮。如果您想关注任何特定元素,则可以使用以下 XPath 方法
Xpath=//*[@type='text']//following::input[1]
您可以根据需要更改 XPath,例如将 [1]、[2]……等。
将输入设为“1”,下面的屏幕截图将找到特定的节点,即“密码”输入框元素。
2) Ancestor(祖先)
祖先轴选择当前节点的所有祖先元素(祖父、父等),如以下屏幕所示。
在下面的表达式中,我们正在查找当前节点(“企业测试”节点)的祖先元素。
Xpath=//*[text()='Enterprise Testing']//ancestor::div
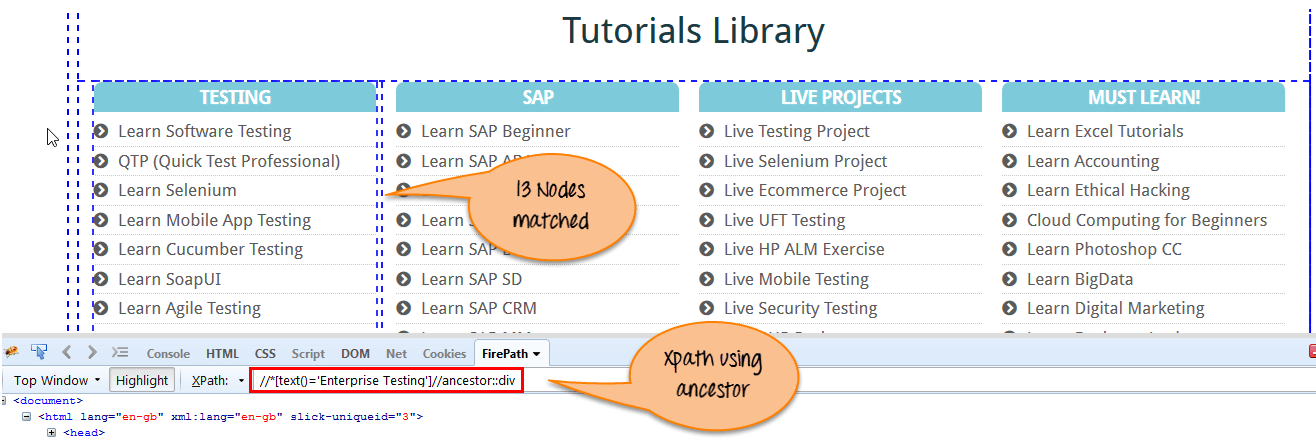
通过使用“ancestor”轴,有 13 个“div”节点匹配。如果您想关注任何特定元素,则可以使用以下 XPath,您需要根据自己的要求更改数字 1、2 等
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]
您可以根据需要更改 XPath,例如将 [1]、[2]……等。
3) Child(子代)
选择当前节点(Java)的所有子元素,如以下屏幕所示。
Xpath=//*[@id='java_technologies']//child::li
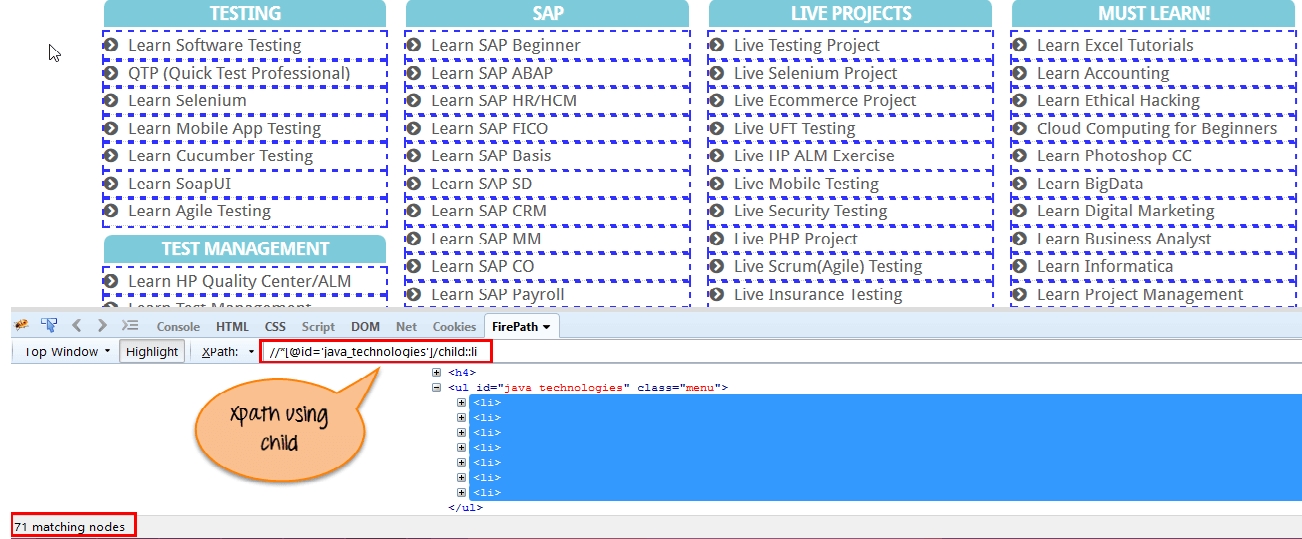
通过使用“child”轴,有 71 个“li”节点匹配。如果您想关注任何特定元素,则可以使用以下 XPath
Xpath=//*[@id='java_technologies']//child::li[1]
您可以根据需要更改 xpath,例如将 [1]、[2]……等。
4) Preceding(先行)
选择所有在当前节点之前出现的节点,如以下屏幕所示。
在下面的表达式中,它标识“LOGIN”按钮之前的所有输入元素,即 用户 ID 和 密码 输入元素。
Xpath=//*[@type='submit']//preceding::input
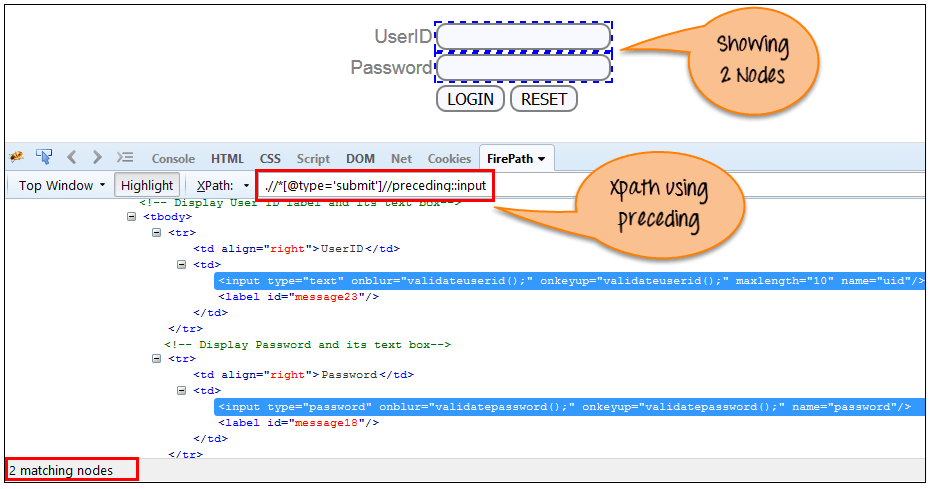
通过使用“preceding”轴,有 2 个“input”节点匹配。如果您想关注任何特定元素,则可以使用以下 XPath
Xpath=//*[@type='submit']//preceding::input[1]
您可以根据需要更改 xpath,例如将 [1]、[2]……等。
5) Following-sibling(后续兄弟)
选择上下文节点的后续兄弟节点。兄弟节点与当前节点处于同一级别,如以下屏幕所示。它将查找当前节点之后的元素。
xpath=//*[@type='submit']//following-sibling::input
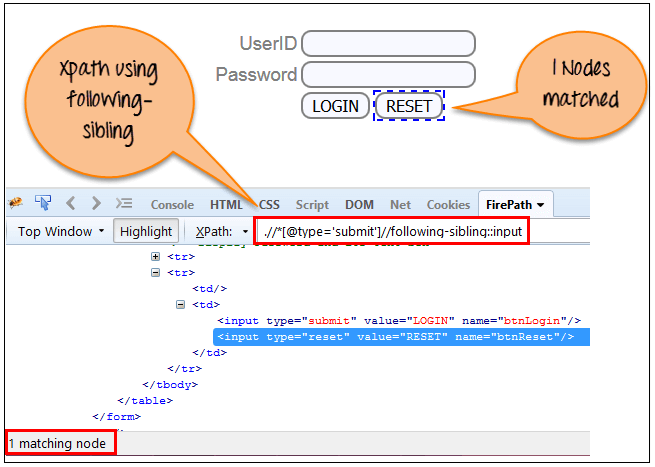
通过使用“following-sibling”轴,一个输入节点匹配。
6) Parent(父级)
选择当前节点的父级,如以下屏幕所示。
Xpath=//*[@id='rt-feature']//parent::div
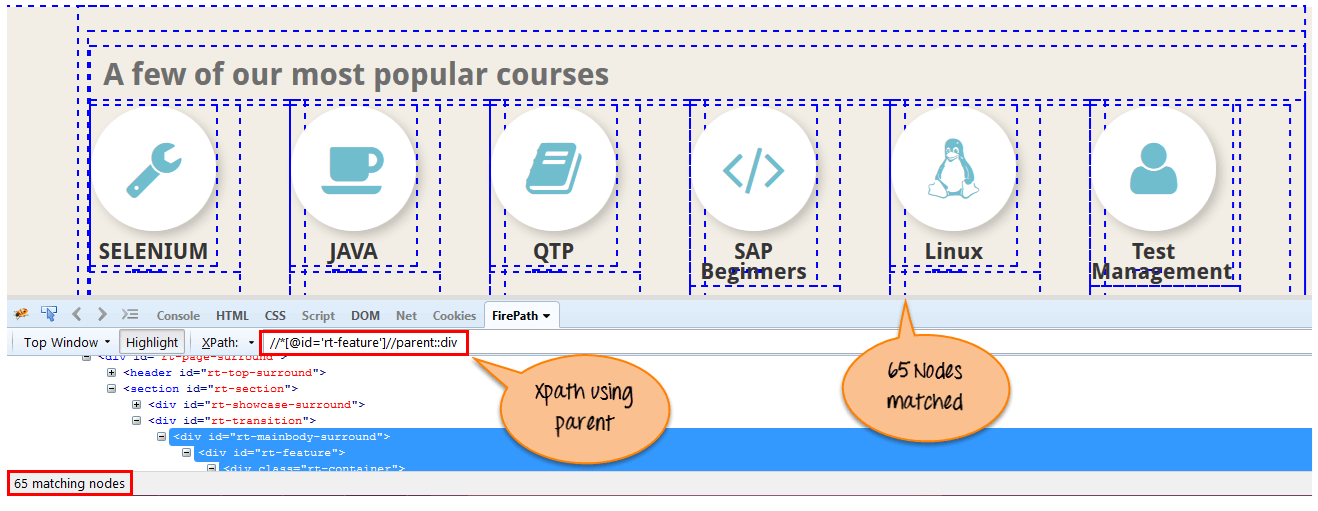
通过使用“parent”轴,有 65 个“div”节点匹配。如果您想关注任何特定元素,则可以使用以下 XPath
Xpath=//*[@id='rt-feature']//parent::div[1]
您可以根据需要更改 XPath,例如将 [1]、[2]……等。
7) Self(自身)
选择当前节点或“自身”,表示它指示节点本身,如以下屏幕所示。
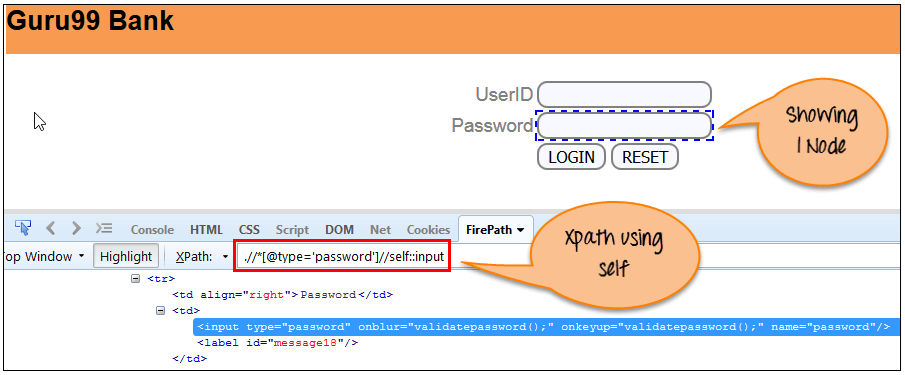
通过使用“self”轴,一个节点匹配。它总是只找到一个节点,因为它代表自身元素。
Xpath =//*[@type='password']//self::input
8) Descendant(后代)
选择当前节点的后代,如以下屏幕所示。
在下面的表达式中,它标识当前元素(“主内容环绕”框架元素)的所有后代元素,这意味着节点下的(子节点、孙节点等)。
Xpath=//*[@id='rt-feature']//descendant::a
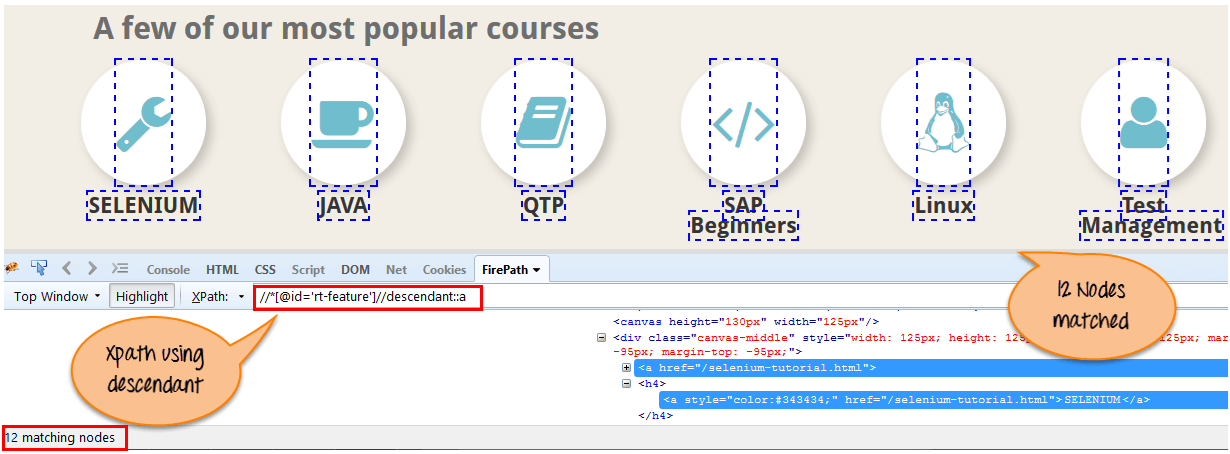
通过使用“descendant”轴,有 12 个“link”节点匹配。如果您想关注任何特定元素,则可以使用以下 XPath
Xpath=//*[@id='rt-feature']//descendant::a[1]
您可以根据需要更改 XPath,例如将 [1]、[2]……等。
摘要
需要 XPath 来查找网页上的元素,以便对该特定元素执行操作。
- Selenium XPath 有两种类型
- 绝对 XPath
- 相对 XPath
- XPath 轴是用于查找动态元素的方法,否则无法通过普通 XPath 方法找到这些元素
- XPath 表达式根据 XML 文档中的属性(如 ID、名称、类名等)选择节点或节点列表。
另请查看:- Selenium 初学者教程:7 天学习 WebDriver