Hive Join 和子查询教程(附示例)
Join 查询
Join 查询可以在 Hive 中的两个表上执行。为了清楚地理解 Join 的概念,我们在这里创建两个表,
- Sample_joins(与客户详细信息相关)
- Sample_joins1(与员工下的订单详细信息相关)
步骤 1) 创建表“sample_joins”,其列名为 ID、Name、Age、address 和 salary。

步骤 2) 加载和显示数据
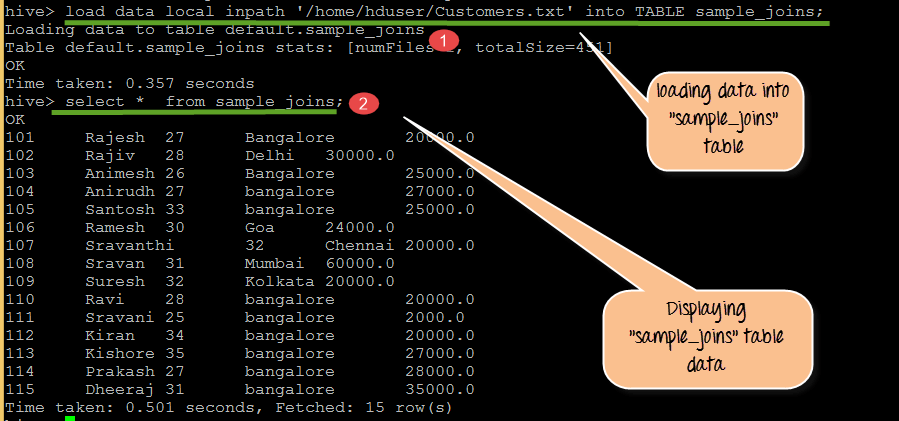
从上面的屏幕截图
- 将数据从 Customers.txt 加载到 sample_joins
- 显示 sample_joins 表内容
步骤 3) 创建 sample_joins1 表并加载、显示数据
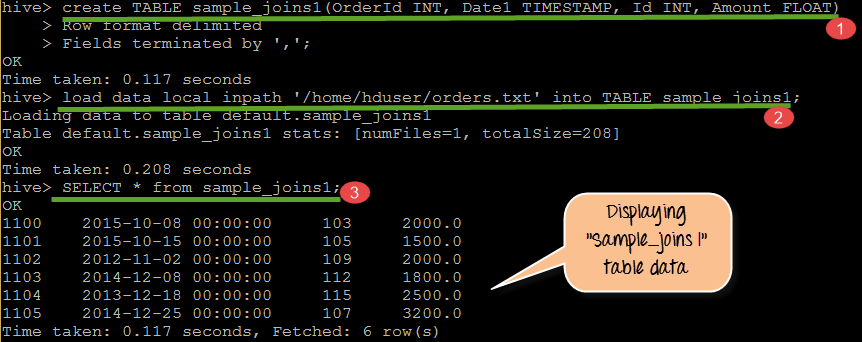
从上面的屏幕截图中,我们可以观察到以下内容
- 创建表 sample_joins1,其列为 Orderid、Date1、Id、Amount
- 将数据从 orders.txt 加载到 sample_joins1
- 显示 sample_joins1 中存在的记录
接下来,我们将看到可以在我们创建的表上执行的不同类型的 Join,但在此之前,您需要考虑 Join 的以下几点。
Join 中需要注意的一些点
- Join 中只允许相等 Join
- 在同一查询中可以 Join 两个以上的表
- LEFT、RIGHT、FULL OUTER join 存在,以便为没有匹配的 ON 子句提供更多控制
- Join 不具有交换律
- 无论 Join 是 LEFT 还是 RIGHT,它们都遵循左结合律
不同类型的 Join
Join 分为 4 种类型,分别是:
- 内连接
- 左外连接
- Right Outer Join
- Full Outer Join
内连接 (Inner Join)
此内连接将检索两个表中都存在的记录。
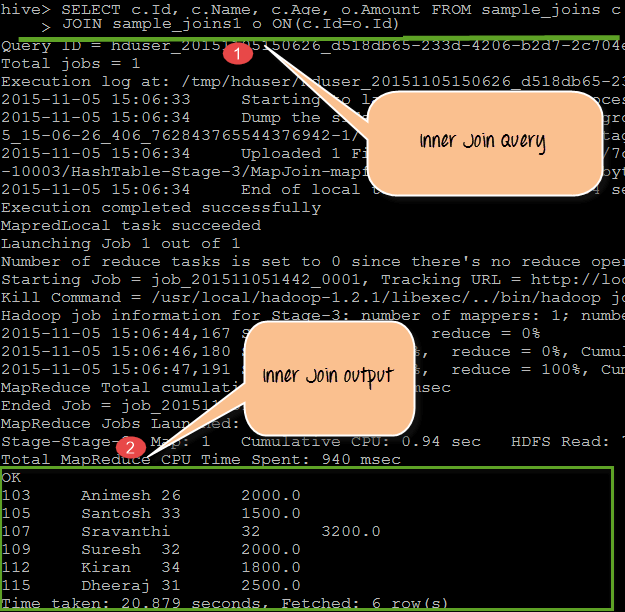
从上面的屏幕截图中,我们可以观察到以下内容
- 此处我们使用 JOIN 关键字在 sample_joins 和 sample_joins1 表之间执行 join 查询,匹配条件为 (c.Id= o.Id)。
- 输出显示了通过检查查询中指定的条件在两个表中都存在的共同记录。
查询
SELECT c.Id, c.Name, c.Age, o.Amount FROM sample_joins c JOIN sample_joins1 o ON(c.Id=o.Id);
左外连接
- Hive 查询语言 LEFT OUTER JOIN 返回左表的所有行,即使右表中没有匹配项。
- 如果 ON 子句没有匹配到右表中的任何记录,Join 仍然会在结果中返回一条记录,其中右表的所有列都为 NULL。
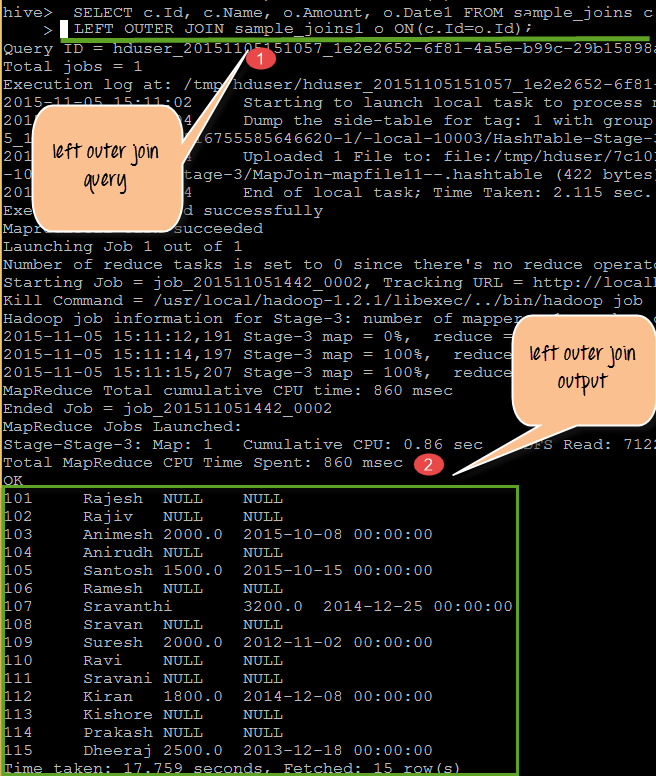
从上面的屏幕截图中,我们可以观察到以下内容
- 此处我们使用“LEFT OUTER JOIN”关键字在 sample_joins 和 sample_joins1 表之间执行 join 查询,匹配条件为 (c.Id= o.Id)。例如,这里我们使用员工 ID 作为参考,它会检查 ID 是否在右表和左表中都存在。它充当匹配条件。
- 输出显示了通过检查查询中指定的条件在两个表中都存在的共同记录。上述输出中的 NULL 值表示右表(即 sample_joins1)中没有值的列。
查询
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c LEFT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
右外连接
- Hive 查询语言 RIGHT OUTER JOIN 返回右表的所有行,即使左表中没有匹配项。
- 如果 ON 子句没有匹配到左表中的任何记录,Join 仍然会在结果中返回一条记录,其中左表的所有列都为 NULL。
- RIGHT join 始终返回来自右表的记录以及来自左表的匹配记录。如果左表在相应列中没有值,则会在该位置返回 NULL 值。
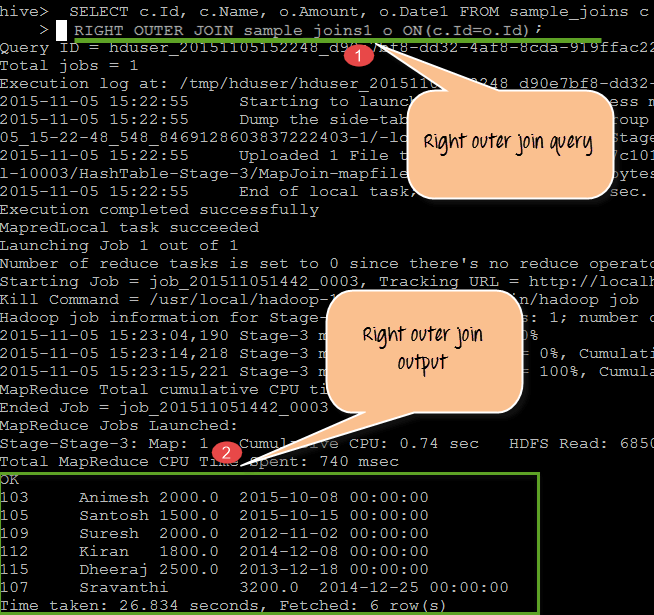
从上面的屏幕截图中,我们可以观察到以下内容
- 此处我们使用“RIGHT OUTER JOIN”关键字在 sample_joins 和 sample_joins1 表之间执行 join 查询,匹配条件为 (c.Id= o.Id)。
- 输出显示了通过检查查询中指定的条件在两个表中都存在的共同记录。
查询:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c RIGHT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
全外连接
它根据查询中给定的 JOIN 条件合并 sample_joins 和 sample_joins1 表的记录。
它返回两个表的所有记录,并为任一侧匹配时缺失值的列填充 NULL 值。
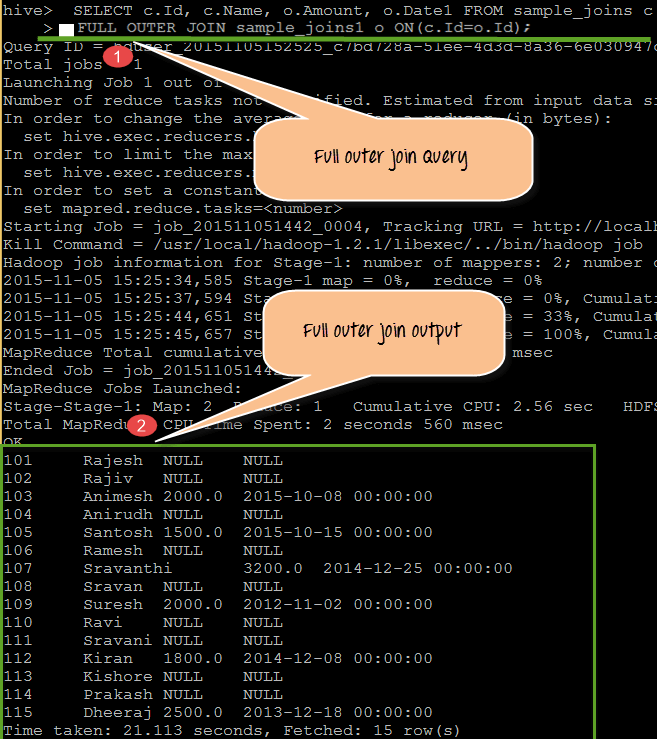
从上面的屏幕截图中,我们可以观察到以下几点
- 此处我们使用“FULL OUTER JOIN”关键字在 sample_joins 和 sample_joins1 表之间执行 join 查询,匹配条件为 (c.Id= o.Id)。
- 输出显示了通过检查查询中指定的条件在两个表中存在的记录。这里的 NULL 值表示两个表中列的缺失值。
查询
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c FULL OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
子查询
包含在查询中的查询称为子查询。主查询将依赖于子查询返回的值。
子查询可分为两种类型
- FROM 子句中的子查询
- WHERE 子句中的子查询
何时使用
- 从不同表中的两个列值中获取特定值的组合
- 一个表的值依赖于其他表
- 对一个表的值与其他表的值进行比较检查
语法
Subquery in FROM clause SELECT <column names 1, 2…n>From (SubQuery) <TableName_Main > Subquery in WHERE clause SELECT <column names 1, 2…n> From<TableName_Main>WHERE col1 IN (SubQuery);
示例
SELECT col1 FROM (SELECT a+b AS col1 FROM t1) t2
这里 t1 和 t2 是表名。着色部分是在表 t1 上执行的子查询。这里 a 和 b 是在子查询中添加并分配给 col1 的列。col1 是主表中存在的列。子查询中的此列“col1”等同于主查询中的列 col1。
嵌入自定义脚本
Hive 为客户端需求提供了编写用户特定脚本的可能性。用户可以为需求编写自己的 map 和 reduce 脚本。这些称为嵌入式自定义脚本。代码逻辑在自定义脚本中定义,我们可以在 ETL 时间使用该脚本。
何时选择嵌入式脚本
- 在客户端特定需求中,开发人员必须在 Hive 中编写和部署脚本
- 当 Hive 内置函数无法满足特定域需求时
为此,Hive 使用 TRANSFORM 子句来嵌入 map 和 reducer 脚本。
在此嵌入式自定义脚本中,我们必须注意以下几点:
- 列将被转换为字符串,并用 TAB 分隔,然后提供给用户脚本。
- 用户脚本的标准输出将被视为 TAB 分隔的字符串列。
示例嵌入式脚本,
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' AS dt, uid CLUSTER BY dt) map_output INSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.dt, map_output.uid USING 'reduce_script' AS date, count;
从上面的脚本中,我们可以观察到以下几点:
这只是一个用于理解的示例脚本。
- pv_users 是用户表,它具有 map_script 中提到的 userid 和 date 字段。
- Reducer 脚本定义在 date 和 pv_users 表的计数上。