Hive 查询:Order By、Group By、Distribute By、Cluster By 示例
Hive 在 Hadoop 文件系统之上提供了一种用于 ETL 的类 SQL 查询语言。
Hive 查询语言 (HiveQL) 在 Hive 中提供了一个类 SQL 环境,用于处理表、数据库和查询。
为了更好地与环境外的不同节点连接,Hive 提供了多种子句来执行不同类型的数据操作和查询,Hive 还提供 JDBC 连接。
Hive 查询提供以下功能:
- 数据建模,例如创建数据库、表等。
- ETL 功能,例如从表中提取、转换和加载数据。
- Join 合并不同的数据表。
- 用户特定的自定义脚本,以便于编写代码。
- Hadoop 之上的更快的查询工具。
在 Hive 中创建表。
在开始本教程的主要主题之前,我们首先创建一个表作为后续教程的参考。
在本教程中,我们将创建名为“employees_guru”的表,其中包含 6 列。

从上面的截图来看,
- 我们正在创建“employees_guru”表,其中包含 6 列值,如 Id、Name、Age、Address、Salary、Department,这些值属于组织“guru”中的员工。
- 在此步骤中,我们将数据加载到 employees_guru 表中。我们将加载的数据将放在 Employees.txt 文件下。
ORDER BY 查询。
HiveQL 中的 ORDER BY 语法与 SQL 语言中的 ORDER BY 语法相似。
ORDER BY 是我们在 Hive 查询中与“SELECT”语句一起使用的子句,它有助于对数据进行排序。ORDER BY 子句使用 Hive 表中的列来排序“ORDER BY”中指定的特定列值。对于我们为 ORDER BY 子句定义的任何列名,查询都将按特定列值的升序或降序选择和显示结果。
如果指定的 ORDER BY 字段是字符串,则结果将按字典顺序显示。在后端,它必须传递给单个 reducer。
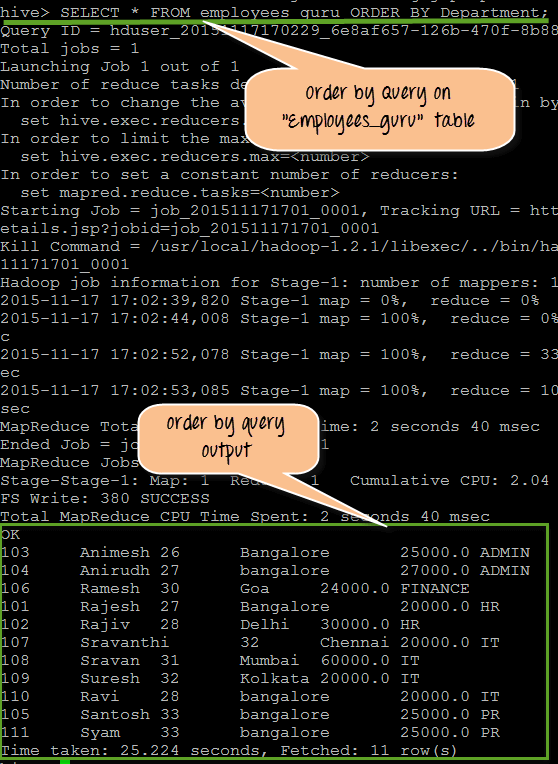
从上面的截图,我们可以观察到以下几点:
- 这是对“employees_guru”表执行的查询,其中 ORDER BY 子句将 Department 定义为 ORDER BY 列名。“Department”是字符串,因此它将根据字典顺序显示结果。
- 这是查询的实际输出。如果我们仔细观察,可以看到结果是根据 Department 列显示的,例如 ADMIN、Finance 等,按顺序执行查询。
查询
SELECT * FROM employees_guru ORDER BY Department;
GROUP BY 查询。
GROUP BY 子句使用 Hive 表中的列来对 GROUP BY 中指定的特定列值进行分组。对于我们为“groupby”子句定义的任何列名,查询都将通过对特定列值进行分组来选择和显示结果。
例如,在下面的截图中,它将显示每个部门的员工总数。这里我们将“Department”作为 GROUP BY 值。
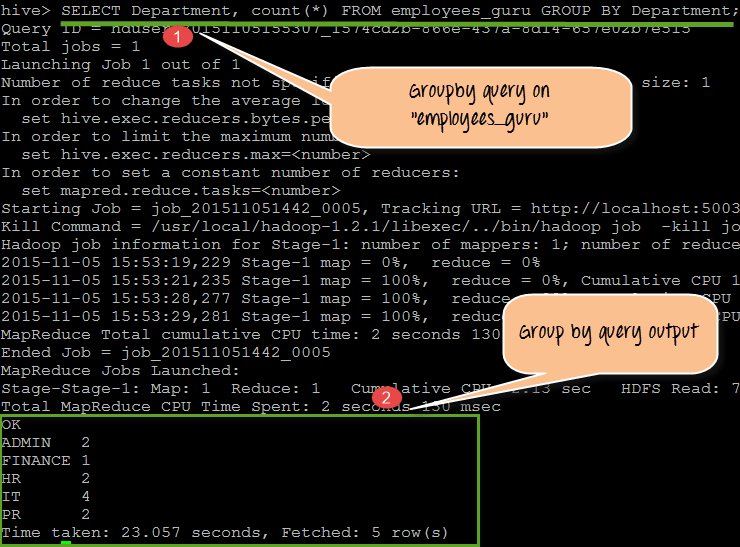
从上面的截图,我们将观察到以下几点:
- 这是对“employees_guru”表执行的查询,其中 GROUP BY 子句将 Department 定义为 GROUP BY 列名。
- 显示的输出是部门名称以及不同部门的员工计数。这里属于特定部门的所有员工都按部门分组并显示在结果中。因此,结果是部门名称以及每个部门的员工总数。
查询
SELECT Department, count(*) FROM employees_guru GROUP BY Department;
SORT BY。
SORT BY 子句作用于 Hive 表的列名以对输出进行排序。我们可以指定 DESC 表示降序排序,指定 ASC 表示升序排序。
在此 SORT BY 中,它将在将行馈送到 reducer 之前对其进行排序。SORT BY 始终取决于列类型。
例如,如果列类型是数字,它将按数字顺序排序;如果列类型是字符串,它将按字典顺序排序。
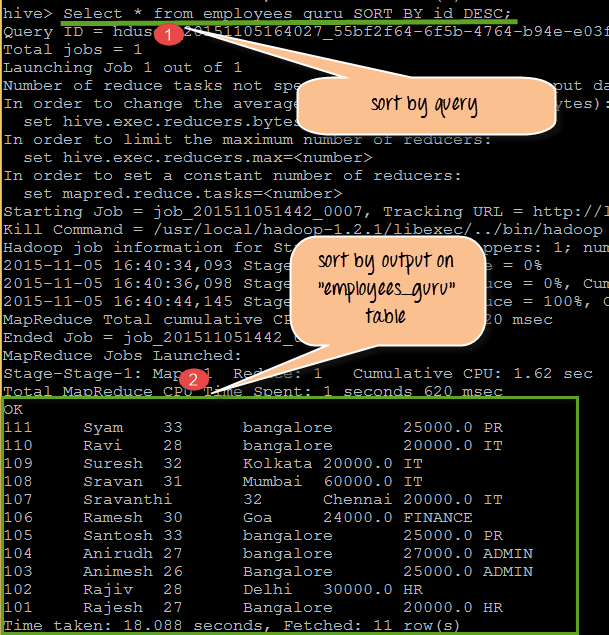
从上面的屏幕截图中,我们可以观察到以下几点
- 这是在“employees_guru”表上使用 SORT BY 子句并以“id”作为定义的 SORT BY 列名执行的查询。我们使用了 DESC 关键字。
- 因此,显示的输出将是“id”的降序。
查询
SELECT * from employees_guru SORT BY Id DESC;
CLUSTER BY。
Cluster By 用作 Hive-QL 中 Distribute BY 和 Sort BY 子句的替代。
Cluster By 子句用于 Hive 中的表。Hive 使用 Cluster by 中的列将行分发给 reducer。Cluster By 列将进入多个 reducer。
- 它确保多个 reducer 中的值具有排序顺序。
例如,Cluster By 子句在 employees_guru 表的 Id 列名上指定。执行此查询时,输出将在后端提供给多个 reducer。但作为前端,它是 Sort By 和 Distribute By 的替代子句。
当我们在 MapReduce 框架中执行带有 sort by、group by 和 cluster by 的查询时,这实际上是后端进程。因此,如果我们想将结果存储到多个 reducer 中,我们会选择 Cluster By。
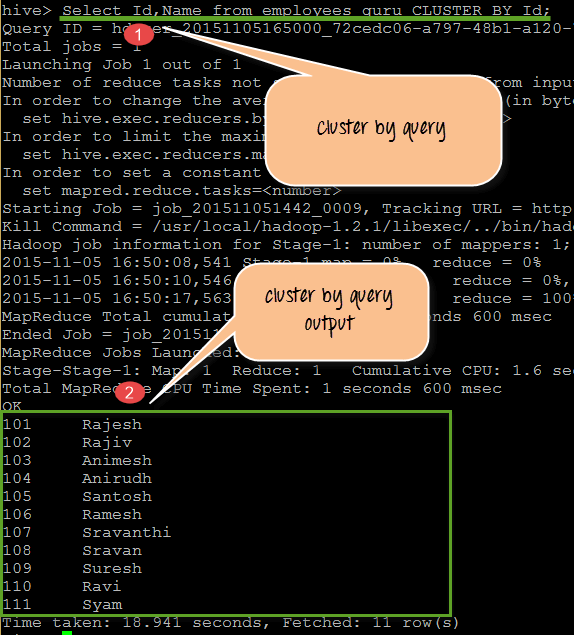
从上面的截图中,我们得到了以下观察结果:
- 这是对 Id 字段值执行 CLUSTER BY 子句的查询。在这里,它将对 Id 值进行排序。
- 它按排序后的 id 和 name 显示 guru_employees 中的 Id 和 Name。
查询
SELECT Id, Name from employees_guru CLUSTER BY Id;
DISTRIBUTE BY。
Distribute By 子句用于 Hive 中的表。Hive 使用 Distribute by 中的列将行分发给 reducer。所有 Distribute By 列将进入同一个 reducer。
- 它确保 N 个 reducer 中的每一个都获得非重叠的列范围。
- 它不排序每个 reducer 的输出。
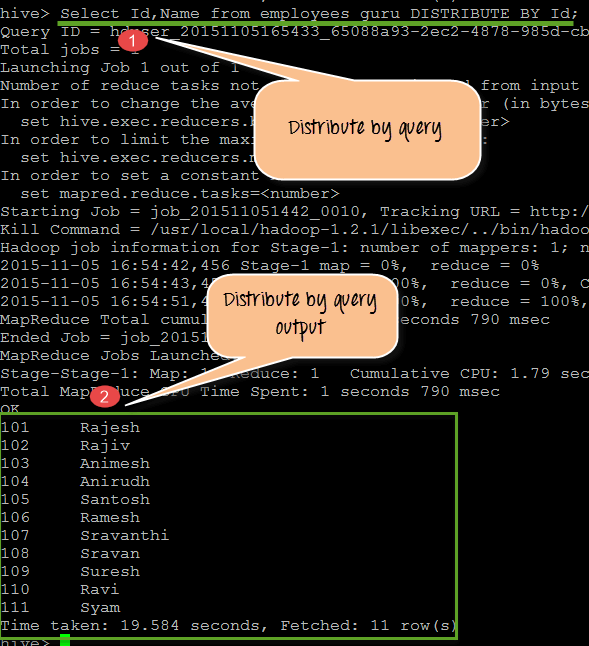
从上面的屏幕截图中,我们可以观察到以下内容
- DISTRIBUTE BY 子句作用于“empoloyees_guru”表上的 Id。
- 输出显示 Id、Name。在后端,它将进入同一个 reducer。
查询
SELECT Id, Name from employees_guru DISTRIBUTE BY Id;