Hive ETL:加载 JSON、XML、文本数据示例
Hive 作为 Hadoop 生态系统之上的 ETL 和数据仓库工具,提供了数据建模、数据操作、数据处理和数据查询等功能。Hive 中的数据提取是指创建 Hive 表,加载结构化和半结构化数据,以及根据需求查询数据。
对于批量处理,我们将使用脚本语言编写自定义定义的脚本,包括自定义 map 和 reduce 脚本。它提供类似 SQL 的环境,并支持轻松查询。
使用 Hive 处理结构化数据
结构化数据是指数据以行和列的正确格式表示。这更像是具有正确行和列的 RDBMS 数据。
在这里,我们将加载文本文件中存在的结构化数据到 Hive 中
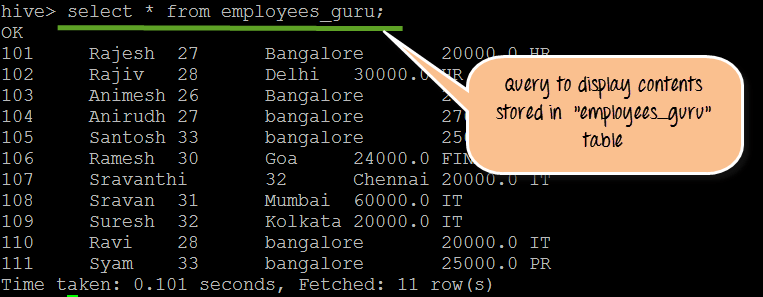
步骤 1)在此步骤中,我们创建名为“employees_guru”的表,其中包含员工的 Id、Name、Age、Address、Salary 和 Department 等列名及其数据类型。

从上面的屏幕截图中,我们可以观察到以下内容:
- 创建表“employees_guru”
- 将数据从 Employees.txt 加载到表“employees_guru”
步骤 2)在此步骤中,我们使用“Select”命令显示存储在此表中的内容。我们可以在以下屏幕截图中看到表的内容。
– 示例代码片段
要执行的查询
1) Create table employees_guru(Id INT, Name STRING, Age INT, Address STRING, Salary FLOAT, Department STRING) > Row format delimited > Fields terminated by ','; 2) load data local inpath '/home/hduser/Employees.txt' into TABLE employees_guru; 3) select * from employees_guru;
使用 Hive 处理半结构化数据(XML、JSON)
Hive 通过充当 ETL 工具 在 Hadoop 生态系统中执行 ETL 功能。在某些类型的应用程序中执行 map reduce 可能会很困难,Hive 可以降低复杂性,并在数据仓库领域为 IT 应用程序提供最佳解决方案。
使用 Hive 可以更轻松地处理 XML 和 JSON 等半结构化数据。首先,我们将了解如何将 Hive 用于 XML 。
XML 到 HIVE 表
在此,我们将把 XML 数据加载到 Hive 表中,然后获取 XML 标签中存储的值。
步骤 1)创建名为“xmlsample_guru”的表,其中包含 string 类型的 str 列。

从上面的屏幕截图中,我们可以观察到以下内容
- 创建表“xmlsample_guru”
- 将数据从 test.xml 加载到表“xmlsample_guru”
步骤 2)使用 XPath () 方法,我们将能够获取 XML 标签中存储的数据。
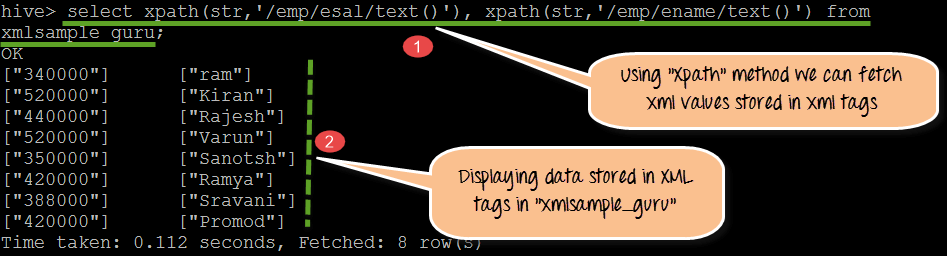
从上面的屏幕截图中,我们可以观察到以下内容
- 使用 XPATH( ) 方法,我们正在获取 /emp/esal/ 和 /emp/ename/ 下存储的值
- XML 标签内的值。在此步骤中,我们将显示存储在表“xmlsample_guru”的 XML 标签中的实际值。
步骤 3)在此步骤中,我们将获取并显示表“xmlsample_guru”的原始 XML。
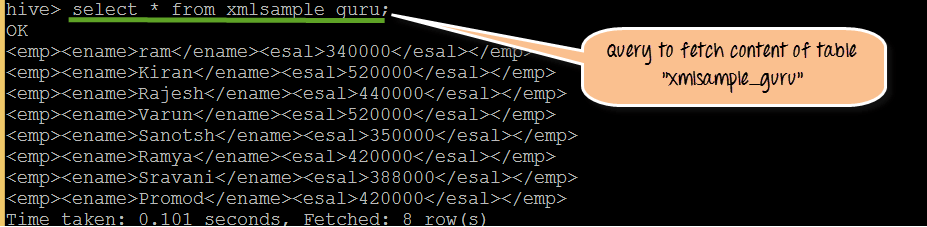
从上面的屏幕截图中,我们可以观察到以下内容
- 显示带有标签的实际 XML 数据
- 如果我们观察单个标签,它是一个带有“emp”作为父标签,“ename”和“esal”作为子标签。
代码片段
要执行的查询
1) create table xmlsample_guru(str string); 2) load data local inpath '/home/hduser/test.xml' overwrite into table xmlsample_guru; 3) select xpath(str,'emp/ename/text()'), xpath(str,'emp/esal/text()') from xmlsample_guru;
JSON(JavaScript 对象表示法)
Twitter 和网站数据以 JSON 格式存储。当我们尝试从在线服务器获取数据时,它会返回 JSON 文件。使用 Hive 作为数据存储,我们可以通过创建模式将 JSON 数据加载到 Hive 表中。
JSON 到 HIVE 表
在此,我们将把 JSON 数据加载到 Hive 表中,然后获取 JSON 模式中存储的值。
步骤 1)在此步骤中,我们将创建一个名为“json_guru”的 JSON 表。创建后,我们将加载并显示实际模式的内容。
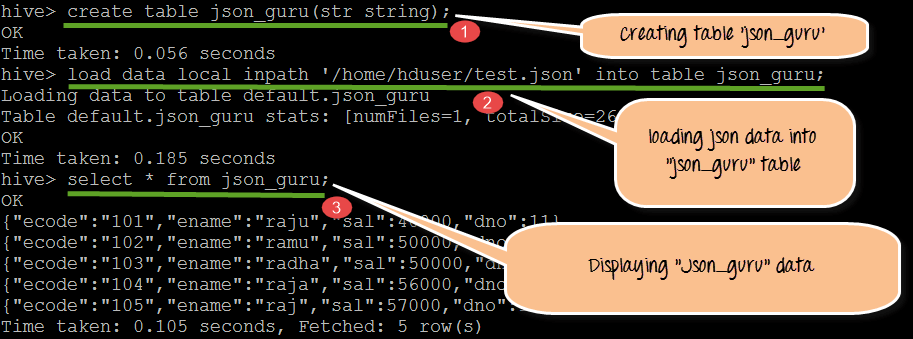
从上面的屏幕截图中,我们可以观察到以下内容
- 创建表“json_guru”
- 将数据从 test.json 加载到表“json_guru”
- 显示存储在 json_guru 表中的 JSON 文件的实际模式
步骤 2)使用 get_json_object() 方法,我们可以获取 JSON 层次结构中存储的数据值。

从上面的屏幕截图中,我们可以观察到以下几点
- 使用 get_json_object (str,‘$.ecode)可以从表 json_guru 获取 ecode 值。类似地,使用 get_json_object (str,‘$.ename)和 get_json_object (str,‘$.Sali),它将从表 json_guru 获取 ename 和 sal 值。
- json_guru 中 JSON 层次结构内存储的值
代码片段
要执行的查询
1) create table json_guru(str string); 2) load data inpath 'home/hduser/test.json' into table json_guru; 3) select * from json1; 4) select get_json_object(str,'$.ecode') as ecode, get_json_object(str,'$.ename') as ename ,get_json_object(str,'$.sal') as salary from json_guru;
复杂 JSON 到 HIVE 表
在此,我们将把复杂 JSON 数据加载到 Hive 表中,然后获取 JSON 模式中存储的值。
步骤 1)创建 complexjson_guru,其中包含单个字段。

从上面的屏幕截图中,我们可以观察到以下内容
- 创建 complexjson_guru 表,其中包含单个字段作为 string 数据类型
- 将数据从 emp.json 复杂 JSON 文件加载到 complexjson_guru
步骤 2)通过使用 get_json_object,我们可以检索存储在 JSON 文件层次结构中的实际内容。
从下面的屏幕截图,我们可以看到存储在 complexjson_guru 中的数据的输出。

步骤 3)在此步骤中,通过使用“Select”命令,我们可以实际看到存储在表“complexjson_guru”中的复杂 JSON 数据。

-示例代码片段,
要执行的查询
1) create table complexjson_guru(json string); 2) load data inpath 'home/hduser/emp.json' into table complexjson_guru; 3) select get_json_object(json,'$.ecode') as ecode ,get_json_object(json,'$.b') as code, get_json_object(json,'$.c') from complexjson_guru; 4) select * from complexjson_guru;
Hive 在实际项目中的应用——何时何地使用
何时何地在 Hadoop 生态系统中使用 Hive
何时
- 在 Hadoop 生态系统中使用强大而有效的统计函数时
- 在处理结构化和半结构化数据时
- 作为 Hadoop 的数据仓库工具
- 对于实时数据摄取,可以使用 HBASE 和 Hive。
Where
- 为了方便使用 ETL 和数据仓库工具
- 提供类似 SQL 的环境,并通过 HIVEQL 进行类似 SQL 的查询
- 使用和部署为特定客户需求定制的 map 和 reducer 脚本