Hive 分区和分桶示例
表、分区和桶是 Hive 数据建模的组成部分。
什么是分区?
Hive 分区是一种通过根据分区键将表划分为不同部分来组织表的方式。
当表中有一个或多个分区键时,分区非常有用。分区键是确定表中数据存储方式的基本元素。
例如:–
“一个客户拥有一些属于印度运营的电子商务数据,其中提到了所有 38 个州的运营。如果我们以 state 列作为分区键,并对整个印度数据进行分区,我们将获得 38 个分区(对应 38 个州)。这样,每个州的数据都可以在分区表中单独查看。
分区的示例代码片段
- 创建所有州的表
create table all states(state string, District string,Enrolments string) row format delimited fields terminated by ',';
- 将数据加载到已创建的所有州表中
Load data local inpath '/home/hduser/Desktop/AllStates.csv' into table allstates;
- 创建分区表
create table state_part(District string,Enrolments string) PARTITIONED BY(state string);
- 对于分区,我们需要设置此属性
set hive.exec.dynamic.partition.mode=nonstrict
- 将数据加载到分区表中
INSERT OVERWRITE TABLE state_part PARTITION(state) SELECT district,enrolments,state from allstates;
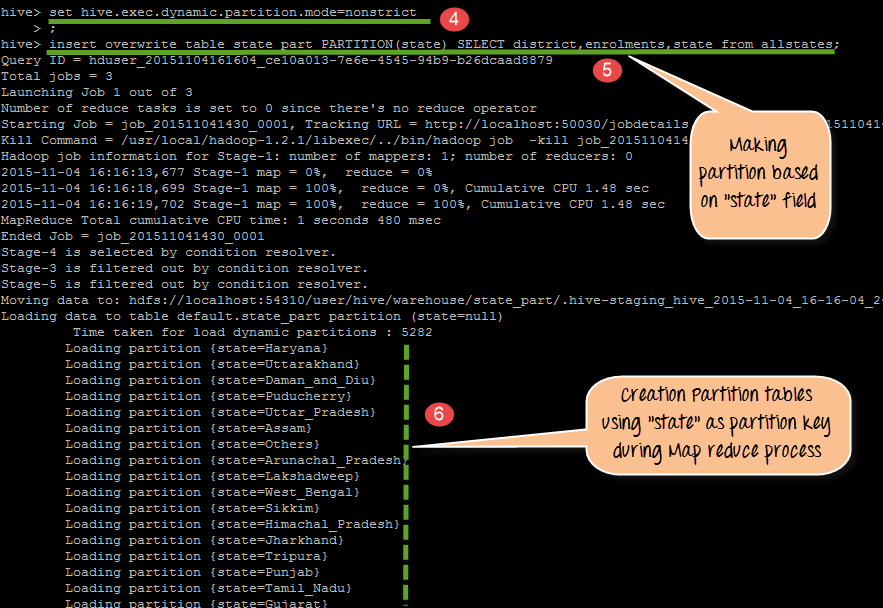
- 实际处理和基于州作为分区键形成分区表
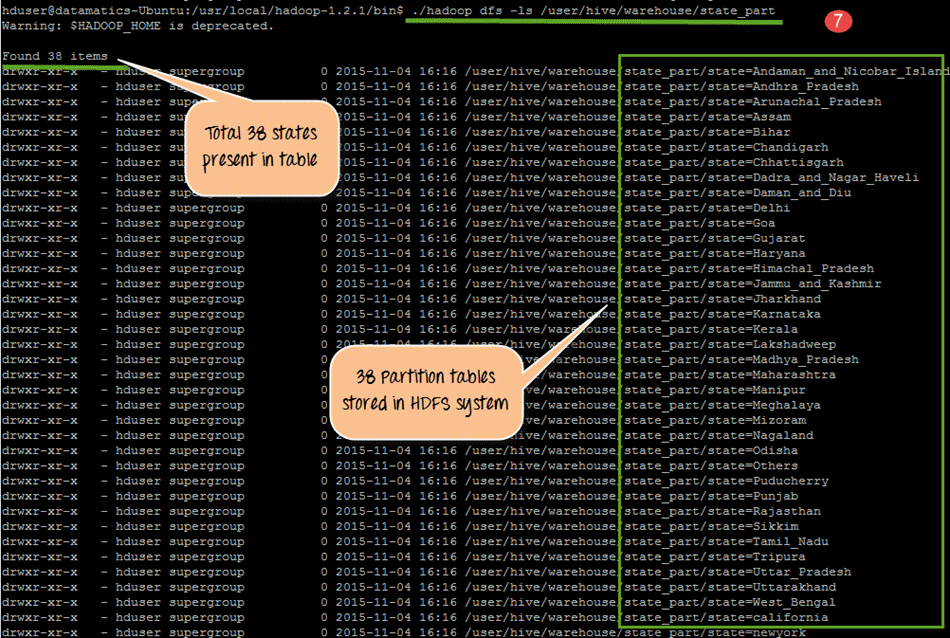
- HDFS 存储中将有 38 个分区输出,文件名为州名。我们将在这一步进行检查。
以下屏幕截图将展示上述代码的执行情况。


从上面的代码,我们执行以下操作:
- 创建包含 state、district 和 enrollment 这 3 列名称的表 all states。
- 将数据加载到表 all states 中
- 创建以 state 作为分区键的分区表
- 在此步骤中,将分区模式设置为非严格模式(此模式将激活动态分区模式)。
- 将数据加载到分区表 state_part 中
- 实际处理和基于州作为分区键形成分区表
- HDFS 存储中将有 38 个分区输出,文件名为州名。我们将在这一步进行检查。在此步骤中,我们看到了 HDFS 中的 38 个分区输出。
什么是分桶?
Hive 中的分桶用于将 Hive 表数据分隔到多个文件或目录中。它用于提高查询效率。
- 分区中的数据可以进一步划分为桶。
- 划分是基于我们选择的表中的特定列的哈希值进行的。
- 桶在后台使用某种哈希算法来读取每个记录并将其放入桶中。
- 在 Hive 中,我们必须通过使用 **set.hive.enforce.bucketing=true;** 来启用分桶。
步骤 1) 如下创建桶。
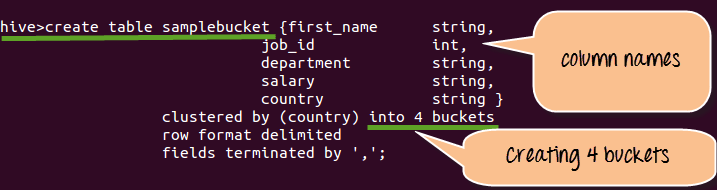
从上面的屏幕截图
- 我们创建 sample_bucket,其列名包括 first_name、job_id、department、salary 和 country。
- 我们在这里创建了 4 个桶。
- 数据加载后,它会自动将数据放入 4 个桶中。
步骤 2) 将数据加载到表 sample_bucket 中
假设“Employees 表”已在 Hive 系统中创建。在此步骤中,我们将查看从 employees 表加载数据到表 sample_bucket。
在开始将 employees 数据移入桶之前,请确保它包含 first_name、job_id、department、salary 和 country 等列名。
这里我们正在将 employees 表中的数据加载到 sample_bucket 中。

步骤 3) 显示在步骤 1 中创建的 4 个桶。
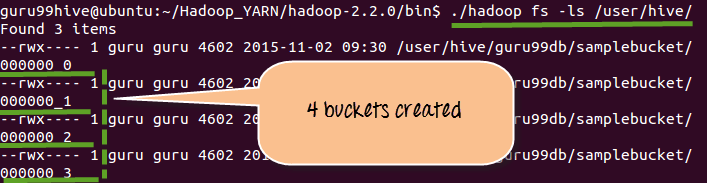
从上面的屏幕截图,我们可以看到 employees 表中的数据已转移到步骤 1 中创建的 4 个桶中。