什么是Hive?架构与模式
什么是Hive?
Hive是基于Hadoop分布式文件系统(HDFS)开发的ETL和数据仓库工具。Hive简化了执行操作的任务,例如
- 数据封装
- 临时查询
- 海量数据集分析
Hive的重要特性
- 在Hive中,首先创建表和数据库,然后将数据加载到这些表中。
- Hive作为数据仓库,专门用于管理和查询存储在表中的结构化数据。
- 在处理结构化数据时,Map Reduce缺少UDF等优化和可用性功能,但Hive框架具备。查询优化是指在性能方面有效的查询执行方式。
- Hive的类SQL语言使用户能够摆脱Map Reduce编程的复杂性。它重用了关系型数据库世界中熟悉的aughts,如表、行、列和模式等,以便于学习。
- Hadoop的编程基于平面文件。因此,Hive可以使用目录结构来“分区”数据,以提高某些查询的性能。
- Hive中一个新的重要组件是用于存储模式信息的Metastore。这个Metastore通常驻留在关系型数据库中。我们可以通过以下方式与Hive进行交互:
- Web GUI
- Java数据库连接(JDBC)接口
- 大多数交互通过命令行界面(CLI)进行。Hive提供了一个CLI,可以使用Hive查询语言(HQL)编写Hive查询。
- 通常,HQL语法与大多数数据分析师熟悉的 SQL 语法相似。下面的示例查询显示了指定表名中存在的所有记录。
- 示例查询:Select * from <表名>
- Hive支持四种文件格式:TEXTFILE、SEQUENCEFILE、ORC和RCFILE(记录列式文件)。
- 对于单用户元数据存储,Hive使用derby数据库;对于多用户元数据或共享元数据情况,Hive使用MYSQL。
要将MySQL设置为数据库并存储元数据信息,请查看教程“Hive和MySQL的安装与配置”。
关于Hive的一些要点
- HQL和SQL的主要区别在于Hive查询在Hadoop基础设施上执行,而不是在传统数据库上。
- Hive查询执行将是一系列自动生成的Map Reduce作业。
- Hive支持分区和分桶的概念,以便在客户端执行查询时轻松检索数据。
- Hive支持自定义特定的UDF(用户定义函数)来进行数据清理、过滤等。根据程序员的需求,可以定义Hive UDF。
Hive与关系型数据库
使用Hive,我们可以执行一些在关系型数据库中无法实现的功能。对于PB级别的大量数据,在几秒钟内查询并获得结果非常重要。Hive可以非常高效地做到这一点,它能快速处理查询并在几秒钟内产生结果。
让我们看看是什么让Hive如此快速。
Hive与关系型数据库之间的一些关键区别如下:
关系型数据库是“读时模式,写时模式”。先创建表,然后将数据插入到特定表中。在关系型数据库表中,可以执行插入、更新和修改等功能。
Hive是“仅读时模式”。因此,更新、修改等功能在此不起作用。因为Hive查询在典型的集群中运行在多个数据节点上。因此,不可能跨多个节点更新和修改数据(Hive版本0.13以下)。
此外,Hive支持“读多写一次”模式。这意味着在插入表之后,可以在最新版本的Hive中更新表。
注意:然而,新版本的Hive带来了更新的功能。Hive版本(Hive 0.14)提供了更新和删除选项作为新功能。
Hive架构
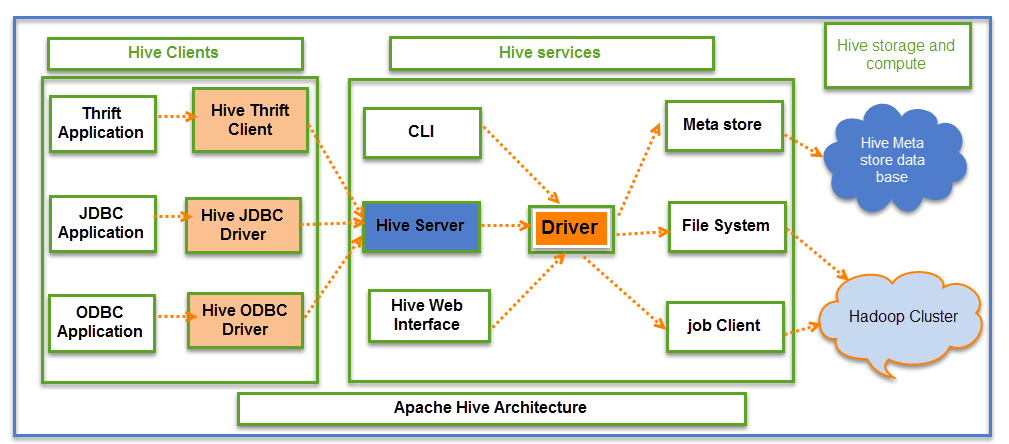
上图详细解释了 Apache Hive的架构。
Hive主要包含3个核心部分
- Hive客户端
- Hive服务
- Hive存储与计算
Hive客户端
Hive提供不同的驱动程序与不同类型的应用程序进行通信。对于基于Thrift的应用程序,它将提供Thrift客户端进行通信。
对于 Java 相关的应用程序,它提供JDBC驱动程序。对于任何其他类型的应用程序,提供ODBC驱动程序。这些客户端和驱动程序反过来又与Hive服务中的Hive服务器进行通信。
Hive服务
客户端可以通过Hive服务与Hive进行交互。如果客户端想要在Hive中执行任何与查询相关的操作,它必须通过Hive服务进行通信。
CLI是命令行界面,作为Hive服务进行DDL(数据定义语言)操作。所有驱动程序都与Hive服务器和Hive服务中的主驱动程序通信,如上图所示。
Hive服务中的Driver代表主Driver,它与所有类型的JDBC、ODBC和其他客户端特定应用程序进行通信。Driver将处理来自不同应用程序的这些请求,并将其发送到Meta store和文件系统进行进一步处理。
Hive存储与计算
Hive服务,如Meta store、文件系统和Job Client,反过来与Hive存储进行通信并执行以下操作:
- 在Hive中创建的表的元数据信息存储在Hive的“Meta storage数据库”中。
- 表中的查询结果和加载的数据将存储在Hadoop集群的HDFS上。
作业执行流程
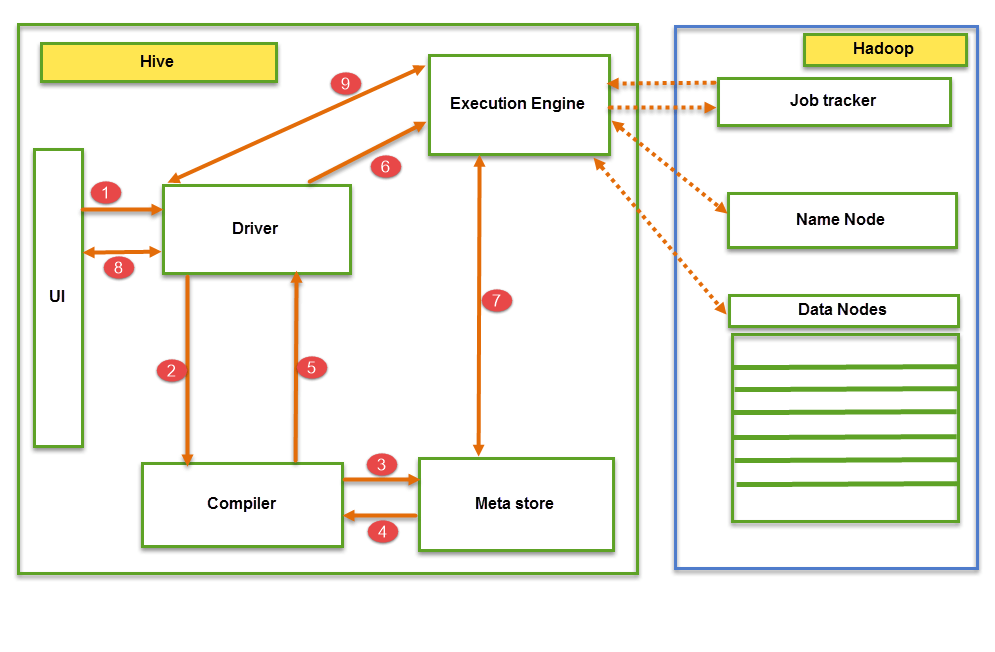
从上图我们可以理解Hive在Hadoop中的作业执行流程。
Hive中的数据流遵循以下模式:
- 通过UI(用户界面)执行查询
- Driver与Compiler交互以获取计划。(此处计划指查询执行)过程及其相关的元数据信息收集。
- Compiler为要执行的作业创建计划。Compiler与Meta store通信以获取元数据请求。
- Meta store将元数据信息发送回Compiler。
- Compiler与Driver通信,并提供要执行查询的计划。
- Driver将执行计划发送到Execution engine。
- Execution Engine(EE)充当Hive和Hadoop之间的桥梁,用于处理查询。用于DFS操作。
- EE首先应联系Name Node,然后联系Data nodes以获取存储在表中的值。
- EE将从Data nodes获取所需的记录。表的实际数据仅驻留在数据节点中。而从Name Node,它仅获取查询的元数据信息。
- 它从数据节点收集与查询相关的实际数据。
- Execution Engine(EE)与Hive中的Meta store双向通信,以执行DDL(数据定义语言)操作。此处执行CREATE、DROP和ALTER表和数据库等DDL操作。Meta store仅存储数据库名称、表名称和列名称的信息。它将获取与查询相关的数据。
- Execution Engine(EE)反过来与Name node、Data nodes和job tracker等Hadoop守护进程通信,以在Hadoop文件系统上执行查询。
- 从Driver获取结果。
- 将结果发送到Execution engine。一旦结果从数据节点获取到EE,它将把结果发送回Driver和UI(前端)。
Hive通过Execution engine持续与Hadoop文件系统及其守护进程通信。作业流程图中的虚线箭头表示Execution engine与Hadoop守护进程的通信。
Hive的不同模式
Hive根据Hadoop数据节点的大小,可以运行在两种模式下。
这些模式是:
- 本地模式
- Map Reduce模式
何时使用本地模式
- 如果Hadoop在伪模式下安装,只有一个数据节点,我们就使用此模式下的Hive。
- 如果数据大小较小,限于单个本地机器,则可以使用此模式。
- 在小数据集上处理速度会非常快。
何时使用Map Reduce模式
- 如果Hadoop有多个数据节点,并且数据分布在不同的节点上,我们就在此模式下使用Hive。
- 它将处理大量数据集,查询将并行执行。
- 通过此模式可以实现大数据集处理和更好的性能。
在Hive中,我们可以设置此属性来指定Hive可以工作在哪种模式?默认情况下,它在Map Reduce模式下工作,对于本地模式,您可以进行如下设置。
Hive以本地模式运行设置
SET mapred.job.tracker=local;
从Hive版本0.7开始,它支持一种模式,可以自动在本地模式下运行Map Reduce作业。
什么是Hive Server2(HS2)?
HiveServer2(HS2)是一个服务器接口,执行以下功能:
- 使远程客户端能够针对Hive执行查询。
- 检索指定查询的结果。
从最新版本开始,它具有一些基于Thrift RPC的高级功能,例如:
- 多客户端并发
- 认证
摘要
Hive是Hadoop生态系统上的ETL和数据仓库工具,用于处理结构化和半结构化数据。
- Hive是Hadoop生态系统中的一个数据库,执行DDL和DML操作,并提供灵活的查询语言,如HQL,以更好地查询和处理数据。
- 与具有某些限制的RDMS相比,它提供了许多功能。
对于用户特定的逻辑以满足客户需求。
- 它提供了编写和部署自定义脚本和用户定义函数(UDF)的选项。
- 此外,它还提供分区和分桶以实现特定存储逻辑。