词嵌入和 Word2Vec 模型示例
什么是词嵌入?
词嵌入是一种词语表示类型,它允许机器学习算法理解具有相似含义的词语。它是一种语言建模和特征学习技术,通过神经网络、概率模型或词语共现矩阵的降维来将词语映射到实数向量。
词嵌入也称为分布式语义模型、分布式表示、语义向量空间或向量空间模型。正如你读到的这些名称一样,你会遇到“语义”这个词,它的意思是将相似的词语归类。例如,苹果、芒果、香蕉等水果应该放在一起,而书籍则应该远离这些词语。广义上讲,词嵌入会创建水果的向量,而书籍的向量表示则会远离水果的向量表示。
词嵌入在哪里使用?
词嵌入有助于特征生成、文档聚类、文本分类和自然语言处理任务。让我们列出它们并对每个应用进行一些讨论。
- 计算相似词:词嵌入用于向预测模型正在处理的词语推荐相似词语。除此之外,它还可以推荐不相似的词语以及最常见的词语。
- 创建相关词组:它用于语义分组,将特征相似的词语分组在一起,将不相似的词语分远开。
- 文本分类特征:文本被映射到向量数组,然后馈送到模型进行训练和预测。基于文本的分类器模型无法在字符串上进行训练,因此这会将文本转换为机器可训练的形式。此外,其构建语义的特征有助于基于文本的分类。
- 文档聚类:这是词嵌入 Word2vec 广泛应用的另一个应用。
- 自然语言处理:有许多应用场景词嵌入都很有用,并且在特征提取阶段表现出色,例如词性标注、情感分析和句法分析。现在我们对词嵌入有了一些了解。还介绍了一些实现词嵌入的模型。整个词嵌入教程都专注于其中一个模型(Word2vec)。
什么是 Word2vec?
Word2vec 是一种用于生成更好词语表示的词语嵌入技术/模型。它是一种自然语言处理方法,可以捕捉大量精确的句法和语义词语关系。它是一个浅层两层神经网络,在训练后可以检测同义词并为部分句子提供附加词语建议。
在进一步深入 Word2vec 教程之前,请参阅下面词嵌入示例图所示的浅层神经网络和深度神经网络的区别。
浅层神经网络仅包含输入和输出之间的隐藏层,而深度神经网络则包含输入和输出之间的多个隐藏层。输入被馈送到节点,而隐藏层和输出层都包含神经元。
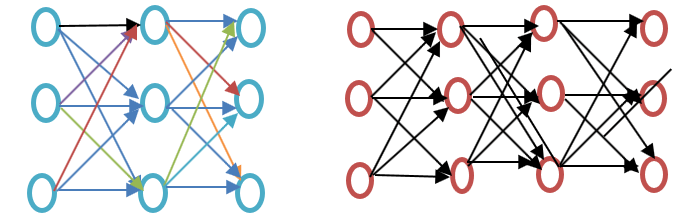
Word2vec 是一个两层网络,有一个输入层、一个隐藏层和一个输出层。
Word2vec 由Tomas Mikolov领导的谷歌研究团队开发。Word2vec 比潜在语义分析模型更好、更有效。
为什么是 Word2vec?
Word2vec 在向量空间表示中表示词语。词语以向量的形式表示,并且其位置安排方式使得含义相似的词语靠近,含义不相似的词语远离。这也被称为语义关系。神经网络不理解文本,它们只理解数字。词嵌入提供了一种将文本转换为数字向量的方法。
Word2vec 重建词语的语言上下文。在深入了解之前,让我们先理解什么是语言上下文?在一般的日常生活中,当我们说话或写作进行交流时,其他人会试图弄清楚句子的目的。例如,“印度的气温是多少”,这里的上下文是用户想知道“印度的气温”,这就是上下文。简而言之,句子的主要目的是上下文。口头或书面语(披露)的词语或句子周围的语境有助于确定上下文的含义。Word2vec 通过上下文学习词语的向量表示。
Word2vec 的作用是什么?
词嵌入之前
了解词嵌入之前的常用方法及其缺点很重要,然后我们将讨论如何使用 Word2vec 方法通过词嵌入克服这些缺点。最后,我们将讨论 Word2vec 的工作原理,因为理解它的工作原理很重要。
潜在语义分析的方法
这是在词嵌入之前使用的方法。它使用了词袋概念,其中词语以编码向量的形式表示。它是一种稀疏向量表示,其维度等于词汇表的大小。如果词语存在于词典中,则计数,否则不计数。要了解更多,请参见下面的程序。
Word2vec 示例
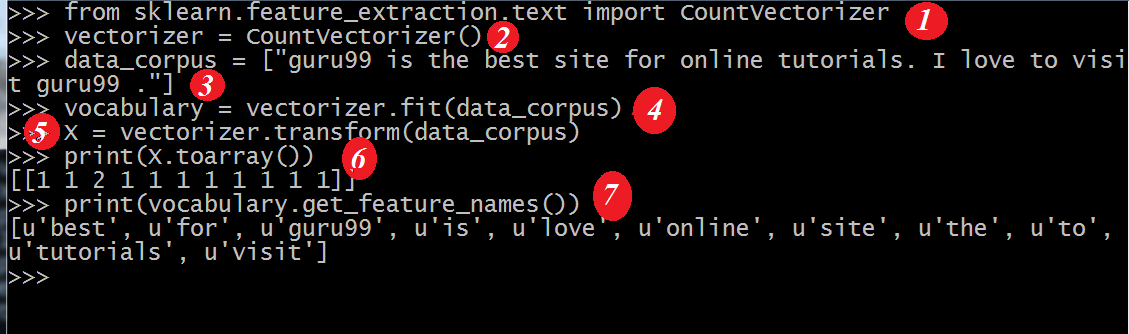
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
输出
[[1 2 1 1 1 1 1 1 1 1]]
[u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
代码解释
- CountVectorizer 是一个模块,用于根据拟合的词语来存储词汇表。它从 sklearn 导入。
- 使用 CountVectorizer 类创建对象。
- 将列表中的数据写入要拟合到 CountVectorizer 中的数据。
- 将数据拟合到从 CountVectorizer 类创建的对象中。
- 应用词袋方法来计算数据中的词语数量。如果词语或标记在词汇表中不可用,则将该索引位置设置为零。
- 第 5 行中的变量 x 被转换为数组(x 的可用方法)。这将提供第 3 行中提供的句子或列表中的每个标记的计数。
- 这将显示使用第 4 行中的数据拟合词汇表时包含的特征。
在潜在语义分析方法中,行代表唯一的词语,而列代表该词语在文档中出现的次数。它是词语在文档矩阵中的表示。词项频率-逆文档频率 (TFIDF) 用于计算文档中词语的频率,即文档中词语的频率/整个语料库中词语的频率。
词袋模型的缺点
- 它忽略了词语的顺序,例如,“this is bad” = “bad is this”。
- 它忽略了词语的上下文。假设我写句子“He loved books. Education is best found in books”。它会创建两个向量,一个用于“He loved books”,另一个用于“Education is best found in books”。它会将两者视为正交的,使它们独立,但实际上它们是相互关联的。
为了克服这些限制,词嵌入被开发出来,而 Word2vec 是一种实现这种方法。
Word2vec 如何工作?
Word2vec 通过预测其周围上下文来学习词语。例如,我们以词语“He loves Football.”为例。
我们要计算词语“loves”的 Word2vec。
假设
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
词语 loves 在语料库的每个词语上移动。词语的句法和语义关系都被编码。这有助于查找相似词和类比词。
计算词语 loves 的所有随机特征。通过反向传播方法,这些特征会根据邻近词或上下文词而改变或更新。
另一种学习方式是,如果两个词语的上下文相似,或者两个词语具有相似的特征,那么这些词语就是相关的。
Word2vec 架构
Word2vec 使用两种架构
- 连续词袋模型 (CBOW)
- Skip gram
在进一步深入 Word2vec 教程之前,让我们从词语表示的角度讨论一下为什么这些架构或模型很重要。学习词语表示本质上是无监督的,但需要目标/标签来训练模型。Skip-gram 和 CBOW 将无监督表示转换为有监督形式以便进行模型训练。
在 CBOW 中,当前词语是使用周围上下文窗口的窗口来预测的。例如,如果给定了词语或上下文 wi-1, wi-2, wi+1, wi+2,该模型将提供 wi。
Skip-Gram 的作用与 CBOW 相反,这意味着它从词语预测给定的序列或上下文。你可以反转上面的例子来理解它。如果给定了 wi,它将预测上下文或 wi-1, wi-2, wi+1, wi+2。
Word2vec 提供了在 CBOW(连续词袋模型)和 Skip-gram 之间进行选择的选项。在模型训练期间提供了这些参数。可以选择使用负采样或层次 Softmax 层。
连续词袋模型
让我们绘制一个简单的 Word2vec 示例图来理解连续词袋模型架构。
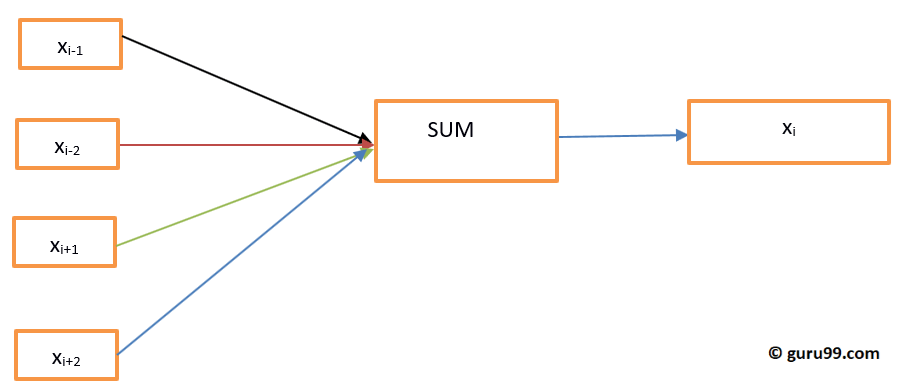
让我们用数学方式计算方程。假设 V 是词汇表大小,N 是隐藏层大小。输入定义为 { xi-1, xi-2, xi+1, xi+2}。通过将 V 乘以 N 得到权重矩阵。通过将输入向量与权重矩阵相乘得到另一个矩阵。也可以通过以下方程来理解。
h=xitW
其中 xit? W 分别是输入向量和权重矩阵,
要计算上下文和下一个词之间的匹配度,请参考以下方程。
u=predictedrepresentation*h
其中 predictedrepresentation 是上面方程中模型?h 得到的。
Skip-Gram 模型
Skip-Gram 方法用于在给定输入词的情况下预测句子。为了更好地理解,让我们绘制下面 Word2vec 示例图中的图。
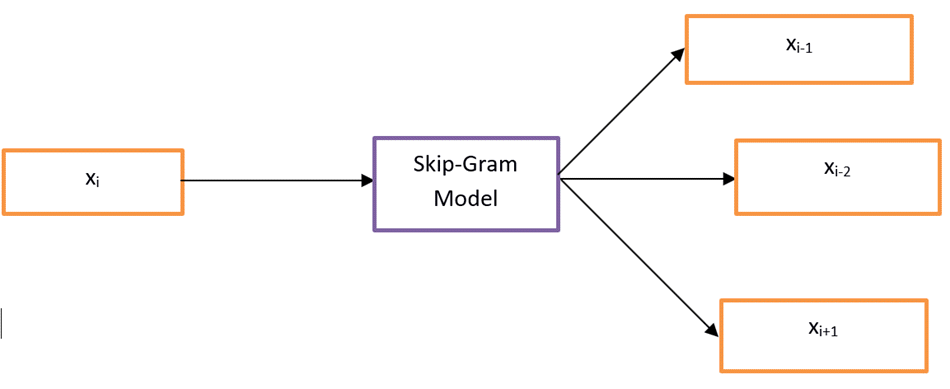
可以将它视为连续词袋模型的反向操作,其中输入是词语,模型提供上下文或序列。我们也可以得出结论,目标被馈送到输入层,而输出层被复制多次以容纳所选的上下文词语数量。所有输出层的误差向量被加总,通过反向传播方法调整权重。
选择哪个模型?
CBOW 的速度比 Skip-gram 快几倍,并且对于频繁词语提供更好的频率;而 Skip-gram 需要少量训练数据,并且能表示稀有词语或短语。
Word2vec 与 NLTK 的关系
NLTK 是自然语言工具包。它用于文本的预处理。您可以执行各种操作,如词性标注、词形还原、词干提取、停用词移除、移除稀有词或最少使用的词。它有助于清理文本,也有助于从有效词中准备特征。换句话说,Word2vec 用于语义(将紧密相关的项放在一起)和句法(序列)匹配。使用 Word2vec,您可以找到相似的词语、不相似的词语、降维等等。Word2vec 的另一个重要特性是将文本的高维表示转换为低维向量。
在哪里使用 NLTK 和 Word2vec?
如果需要完成一些通用的任务,如上面提到的分词、词性标注和解析,您应该使用 NLTK;而对于根据某些上下文预测词语、主题建模或文档相似度,则应该使用 Word2vec。
NLTK 和 Word2vec 的关系(附代码)
NLTK 和 Word2vec 可以一起使用来查找相似词表示或句法匹配。NLTK 工具包可用于加载 NLTK 附带的许多包,并可以使用 Word2vec 创建模型。然后可以在实时词语上进行测试。让我们在下面的代码中看看两者的结合。在继续处理之前,请查看 NLTK 提供的语料库。您可以使用命令下载
nltk(nltk.download('all'))
请查看截图中的代码。
import nltk
import gensim
from nltk.corpus import abc
model= gensim.models.Word2Vec(abc.sents())
X= list(model.wv.vocab)
data=model.most_similar('science')
print(data)
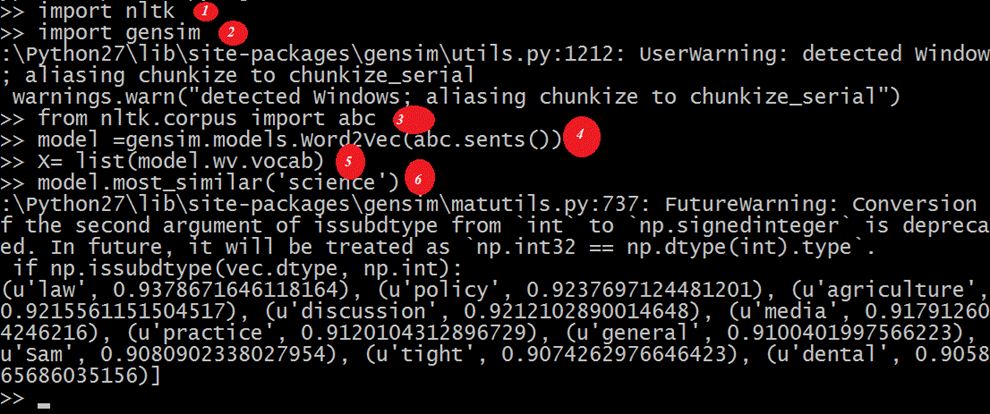
输出
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
代码解释
- 导入了 nltk 库,您可以从中下载 abc 语料库,我们将在下一步中使用它。
- 导入了 Gensim。如果未安装 Gensim Word2vec,请使用命令“pip3 install gensim”进行安装。请查看下面的截图。

- 导入使用 nltk.download(‘abc’) 下载的语料库 abc。
- 将文件以 sentences 的形式传递给从 Gensim 导入的 Word2vec 模型。
- 词汇表以变量的形式存储。
- 在样本词“science”上测试模型,因为这些文件与科学相关。
- 此处,模型预测了“science”的相似词。
激活函数和 Word2Vec
神经元的激活函数定义了该神经元在给定输入集的情况下产生的输出。在生物学上,它受到我们大脑中不同神经元通过不同刺激激活的启发。让我们通过以下图表来理解激活函数。
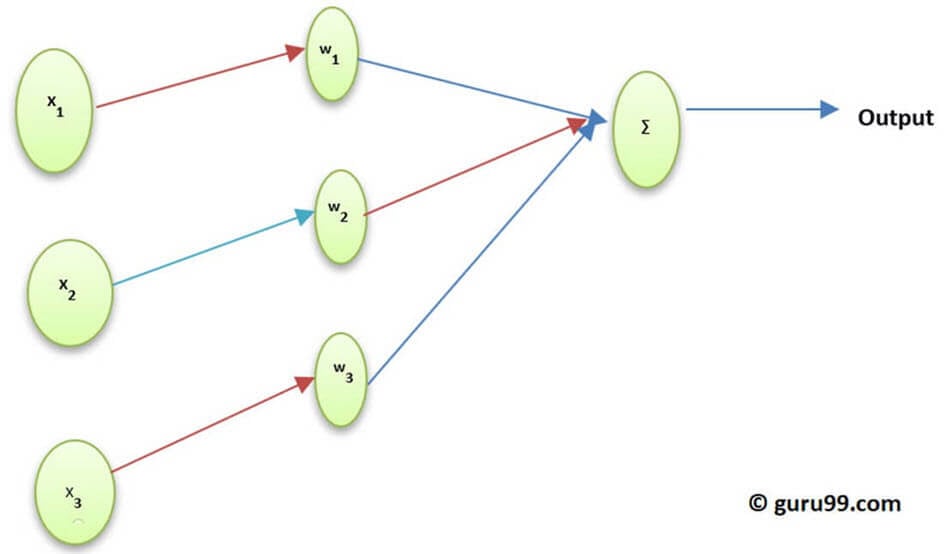
这里 x1, x2,..x4 是神经网络的节点。
w1, w2, w3 是节点的权重,
? 是所有权重和节点值的总和,它作为激活函数。
为什么需要激活函数?
如果没有激活函数,输出将是线性的,但线性函数的用途有限。为了实现复杂的任务,如目标检测、图像分类、通过语音输入文本等,需要非线性输出,这是通过激活函数实现的。
词嵌入(Word2vec)中如何计算激活层
Softmax 层(归一化指数函数)是激活或触发每个节点的输出层函数。另一种使用的方法是层次 Softmax,其复杂度为 O(log2V),而 Softmax 的复杂度为 O(V),其中 V 是词汇表大小。它们之间的区别在于层次 Softmax 层复杂度降低。为了理解其(层次 Softmax)功能,请看下面的词嵌入示例。
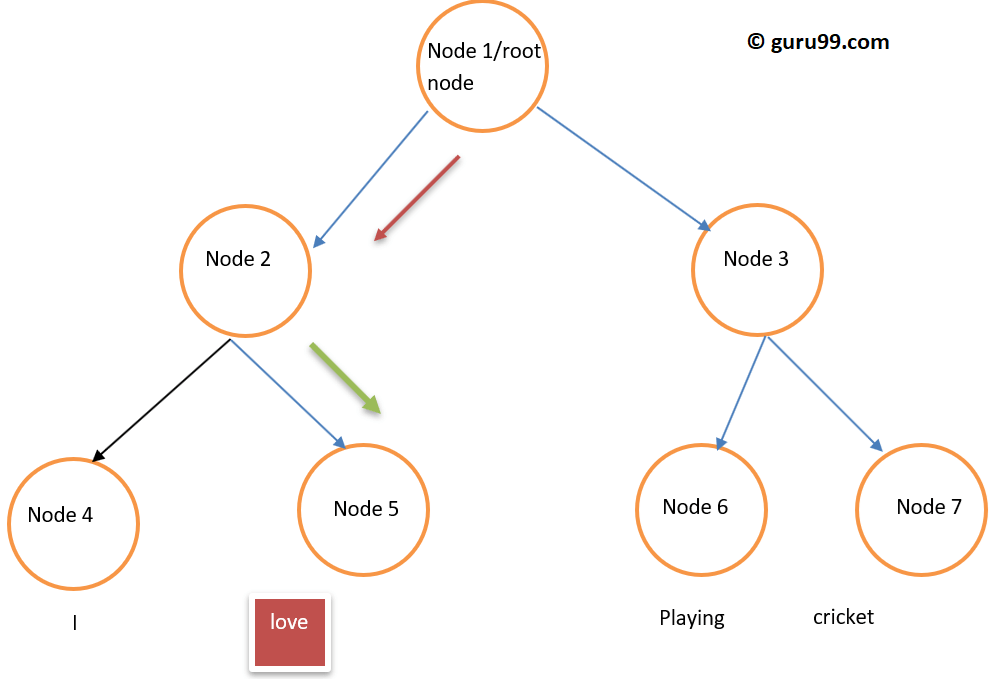
假设我们要计算在给定特定上下文的情况下观察到词语 love 的概率。从根节点到叶子节点的流程将是先移动到节点 2,然后到节点 5。因此,如果我们的词汇表大小为 8,则只需要三次计算。因此,它可以分解为计算一个词语(love)的概率。
除了层次 Softmax 之外,还有哪些其他选项可用?
如果泛泛而言,词嵌入可用的选项有:差异 Softmax、CNN-Softmax、重要性采样、自适应重要性采样、噪声对比估计、负采样、自归一化和低频归一化。
具体到 Word2vec,我们有负采样可用。
负采样是一种对训练数据进行采样的方法。它有点像随机梯度下降,但有一些区别。负采样只关注负训练示例。它基于噪声对比估计,并随机采样词语,而不是上下文。这是一种快速的训练方法,并随机选择上下文。如果预测的词语出现在随机选择的上下文中,则这两个向量会彼此靠近。
可以得出什么结论?
激活函数触发神经元,就像我们的神经元通过外部刺激被触发一样。Softmax 层是输出层函数之一,在词嵌入的情况下触发神经元。在 Word2vec 中,我们有层次 Softmax 和负采样等选项。使用激活函数,可以将线性函数转换为非线性函数,并可以使用它们实现复杂的机器学习算法。
什么是 Gensim?
Gensim 是一个开源的主题建模和自然语言处理工具包,它使用 Python 和 Cython 实现。Gensim 工具包允许用户导入 Word2vec 进行主题建模,以发现文本体中的隐藏结构。Gensim 不仅提供了 Word2vec 的实现,还提供了 Doc2vec 和 FastText 的实现。
本教程全部关于 Word2vec,因此我们将专注于当前主题。
如何使用 Gensim 实现 Word2vec
到目前为止,我们已经讨论了 Word2vec 是什么,它的不同架构,为什么从词袋模型转向 Word2vec,Word2vec 与 NLTK 的关系(附带实时代码)以及激活函数。
下面是使用 Gensim 实现 Word2vec 的分步方法。
步骤 1) 数据收集
实现任何机器学习模型或自然语言处理的第一步是数据收集。
请观察下面 Gensim Word2vec 示例中的数据,以构建一个智能聊天机器人。
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here"," Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", " Can I pay using Mastercard?", " Can I pay using cash only?" ],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don’t worry"]
}
]
这是我们从数据中理解的内容
- 该数据包含三种内容:tag(标签)、pattern(模式)和 responses(响应)。Tag 是意图(讨论的主题)。
- 数据采用 JSON 格式。
- Pattern 是用户将问机器人的问题。
- Responses 是聊天机器人将为相应问题/模式提供的答案。
步骤 2) 数据预处理
处理原始数据非常重要。如果将清理后的数据馈送到机器,模型将响应得更准确,并更有效地学习数据。
此步骤涉及移除停用词、词干提取、移除不必要的词语等。在继续之前,加载数据并将其转换为数据帧很重要。请参见下面的代码。
import json
json_file =’intents.json'
with open('intents.json','r') as f:
data = json.load(f)
代码解释
- 由于数据是 JSON 格式,因此导入 json。
- 文件存储在变量中。
- 文件打开并加载到 data 变量中。
现在数据已导入,是时候将数据转换为数据帧了。请参见下面的代码查看下一步。
import pandas as pd
df = pd.DataFrame(data)
df['patterns'] = df['patterns'].apply(', '.join)
代码解释
1. 使用上面导入的 pandas 将数据转换为数据帧。
2. 它将 pattern 列中的列表转换为字符串。
from nltk.corpus import stopwords
from textblob import Word
stop = stopwords.words('english')
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x.lower() for x in x.split()))
df['patterns't']= df['patterns''].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)
df['patterns']= df['patterns'].str.replace('[^\w\s]','')
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit()))
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x for x in x.split() if not x in stop))
df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
代码解释
1. 使用 nltk 工具包的 stop word 模块导入英文停用词。
2. 使用 for 循环和 lambda 函数将文本中的所有词语转换为小写。 Lambda 函数是一个匿名函数。
3. 检查数据帧中文本的所有行是否存在字符串标点符号,并进行过滤。
4. 使用正则表达式移除数字或点等字符。
5. 从文本中移除数字。
6. 在此阶段移除停用词。
7. 现在过滤词语,并使用词形还原移除相同词语的不同形式。至此,数据预处理完成。
输出
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please don’t worry']",payments
步骤 3) 使用 Word2vec 构建神经网络
现在是时候使用 Gensim Word2vec 模块构建模型了。我们必须从 Gensim 导入 Word2vec。让我们这样做,然后构建模型,在最后阶段我们将在实时数据上进行检查。
from gensim.models import Word2Vec
现在在这个 Gensim Word2vec 教程中,我们可以成功地使用 Word2Vec 构建模型。请参考下一行代码了解如何使用 Word2Vec 创建模型。文本以列表的形式提供给模型,因此我们将使用下面的代码将数据帧中的文本转换为列表。
Bigger_list=[]
for i in df['patterns']
li = list(i.split(""))
Bigger_list.append(li)
Model= Word2Vec(Bigger_list,min_count=1,size=300,workers=4)
代码解释
1. 创建了一个 bigger_list,其中追加了内部列表。这是馈送到 Word2Vec 模型中的格式。
2. 循环执行,并迭代数据帧 patterns 列的每个条目。
3. patterns 列的每个元素都被分割并存储在内部列表 li 中。
4. 内部列表被追加到外部列表中。
5. 此列表被提供给 Word2Vec 模型。让我们了解一些提供的参数。
Min_count:它将忽略所有总频率低于此值的词语。
Size:它表示词语向量的维度。
Workers:这些是训练模型的线程。
还有其他可用选项,其中一些重要选项在下面解释。
Window:句子中当前词语和预测词语之间的最大距离。
Sg:这是一个训练算法,1 表示 skip-gram,0 表示连续词袋模型。我们在上面详细讨论过这些。
Hs:如果为 1,则我们使用层次 Softmax 进行训练;如果为 0,则使用负采样。
Alpha:初始学习率。
让我们在下面显示最终代码。
#list of libraries used by the code
import string
from gensim.models import Word2Vec
import logging
from nltk.corpus import stopwords
from textblob import Word
import json
import pandas as pd
#data in json format
json_file = 'intents.json'
with open('intents.json','r') as f:
data = json.load(f)
#displaying the list of stopwords
stop = stopwords.words('english')
#dataframe
df = pd.DataFrame(data)
df['patterns'] = df['patterns'].apply(', '.join)
# print(df['patterns'])
#print(df['patterns'])
#cleaning the data using the NLP approach
print(df)
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x.lower() for x in x.split()))
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation))
df['patterns']= df['patterns'].str.replace('[^\w\s]','')
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit()))
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x for x in x.split() if not x in stop))
df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
#taking the outer list
bigger_list=[]
for i in df['patterns']:
li = list(i.split(" "))
bigger_list.append(li)
#structure of data to be taken by the model.word2vec
print("Data format for the overall list:",bigger_list)
#custom data is fed to machine for further processing
model = Word2Vec(bigger_list, min_count=1,size=300,workers=4)
#print(model)
步骤 4) 模型保存
模型可以以 bin 和 model 的形式保存。Bin 是二进制格式。请参见下面的行来保存模型。
model.save("word2vec.model")
model.save("model.bin")
上述代码的解释
1. 模型以 .model 文件的形式保存。
2. 模型以 .bin 文件的形式保存。
我们将使用此模型进行实时测试,例如相似词、不相似词和最常见词。
步骤 5) 加载模型并执行实时测试
使用以下代码加载模型。
model = Word2Vec.load('model.bin')
如果您想从中打印词汇表,则使用以下命令完成。
vocab = list(model.wv.vocab)
请看结果。
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
步骤 6) 检查最相似的词语
让我们实际实现一下。
similar_words = model.most_similar('thanks')
print(similar_words)
请看结果。
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
步骤 7) 检查与提供的词语不匹配的词语
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split())
print(dissimlar_words)
我们提供了词语 ‘See you later, thanks for visiting’。这将打印出与这些词语最不相似的词语。让我们运行此代码并查找结果。
上述代码执行后的结果。
Thanks
步骤 8) 查找两个词语之间的相似性
这将以概率形式显示两个词语之间的相似性结果。请参阅下面的代码,了解如何执行此部分。
similarity_two_words = model.similarity('please','see')
print("Please provide the similarity between these two words:")
print(similarity_two_words)
上述代码的结果如下。
0.13706
您可以通过执行以下代码进一步查找相似的词语。
similar = model.similar_by_word('kind')
print(similar)
上述代码的输出。
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]
结论
- 词嵌入是一种词语表示类型,它允许机器学习算法理解具有相似含义的词语。
- 词嵌入用于计算相似词、创建相关词组、作为文本分类特征、进行文档聚类和自然语言处理。
- Word2vec 解释:Word2vec 是一种浅层两层神经网络模型,用于生成更好的词语表示的词语嵌入。
- Word2vec 在向量空间表示中表示词语。词语以向量的形式表示,并且其位置安排方式使得含义相似的词语靠近,含义不相似的词语远离。
- Word2vec 算法使用 2 种架构:连续词袋模型 (CBOW) 和 Skip-gram。
- CBOW 的速度比 Skip-gram 快几倍,并且对于频繁词语提供更好的频率;而 Skip-gram 需要少量训练数据,并且能表示稀有词语或短语。
- NLTK 和 Word2vec 可以结合使用来创建强大的应用程序。
- 神经元的激活函数定义了该神经元在给定输入集的情况下产生的输出。在 Word2vec 中,Softmax 层(归一化指数函数)是激活或触发每个节点的输出层函数。Word2vec 还提供负采样。
- Gensim 是一个用 Python 实现的主题建模工具包。