Python NLTK 中的词干提取和词形还原(附示例)
Python NLTK 中的词干提取和词形还原是什么?
Python NLTK 中的词干提取和词形还原是自然语言处理中的文本规范化技术。这些技术广泛用于文本预处理。词干提取和词形还原之间的区别在于,词干提取速度更快,因为它在不知道上下文的情况下截断单词,而词形还原速度较慢,因为它在处理单词之前了解单词的上下文。
什么是词干提取?
词干提取是自然语言处理中单词规范化的一种方法。它是一种将句子中的一组单词转换为序列以缩短其查找过程的技术。在此方法中,含义相同但根据上下文或句子有某些变化的单词会被规范化。
换句话说,有一个根词,但有许多相同的单词变体。例如,根词是“eat”,它的变体是“eats、eating、eaten 和像这样”。同样,借助 Python 中的词干提取,我们可以找到任何变体的根词。
例如
He was riding. He was taking the ride.
在上述两个句子中,含义是相同的,即过去进行的骑行活动。人类可以轻松理解这两个含义是相同的。但对于机器来说,这两个句子是不同的。因此,很难将其转换为同一数据行。如果我们不提供相同的数据集,机器就会无法预测。因此,有必要区分每个单词的含义以准备机器学习的数据集。在这里,词干提取用于通过获取其根词来对相同类型的数据进行分类。
让我们用 Python 程序来实现这一点。NLTK 有一个名为“PorterStemmer”的算法。该算法接受分词列表并将其词干化为根词。
理解词干提取的程序
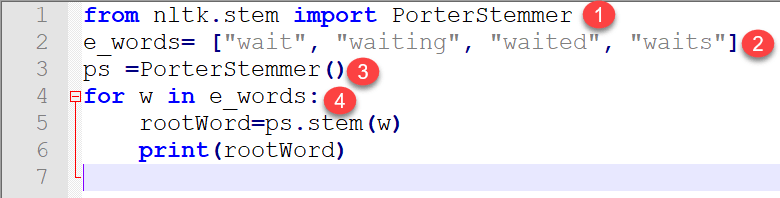
from nltk.stem import PorterStemmer
e_words= ["wait", "waiting", "waited", "waits"]
ps =PorterStemmer()
for w in e_words:
rootWord=ps.stem(w)
print(rootWord)
输出:
wait wait wait wait
代码解释
- NLTk 中有一个 stem 模块可以导入。如果您导入完整的模块,那么程序会变得很重,因为它包含成千上万行代码。因此,在整个 stem 模块中,我们只导入了“PorterStemmer”。
- 我们准备了一个包含相同单词变体数据的虚拟列表。
- 在此创建了一个属于 nltk.stem.porter.PorterStemmer 类的对象。
- 然后,我们使用“for”循环逐个将其传递给 PorterStemmer。最后,我们得到了列表中每个单词的输出根词。
从以上解释可以得出结论,词干提取被认为是一个重要的预处理步骤,因为它消除了数据中的冗余和同一单词中的变体。因此,数据被过滤,这有助于更好的机器训练。
现在我们传入一个完整的句子并检查其作为输出的行为。
程序
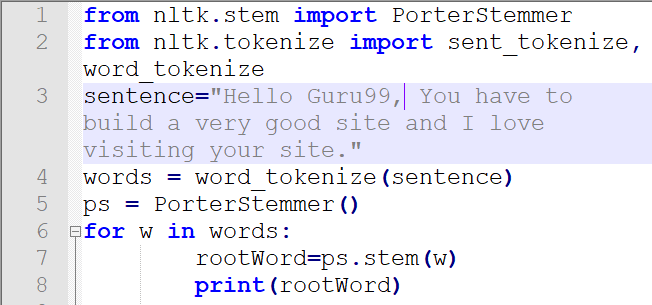
from nltk.stem import PorterStemmer from nltk.tokenize import sent_tokenize, word_tokenize sentence="Hello Guru99, You have to build a very good site and I love visiting your site." words = word_tokenize(sentence) ps = PorterStemmer() for w in words: rootWord=ps.stem(w) print(rootWord)
输出
hello guru99 , you have build a veri good site and I love visit your site
代码解释
- PorterStemer 包从 stem 模块导入
- 导入了用于句子和单词分词的包
- 在此步骤中编写了一个将在下一步进行分词的句子。
- 在此步骤中实现了单词分词、词干提取和词形还原。
- 在此代码行 5 中创建了一个 PorterStemmer 对象。
- 循环运行,并使用代码行 5 中创建的对象对每个单词进行词干提取。
结论
词干提取是一个数据预处理模块。英语语言的单个单词有很多变体。这些变体在机器学习训练和预测中会产生歧义。为了创建成功的模型,使用词干提取过滤这些单词并将其转换为相同类型的序列数据至关重要。此外,这是从一组句子中获取行数据和去除冗余数据(也称为规范化)的重要技术。
什么是词形还原?
NLTK 中的词形还原是根据单词的含义和上下文查找单词词形的算法过程。词形还原通常指单词的形态分析,目的是去除屈折词尾。它有助于返回单词的基本形式或字典形式,即词形。
NLTK 词形还原方法基于 WorldNet 的内置形态函数。文本预处理包括词干提取和词形还原。许多人发现这两个术语令人困惑。有些人认为它们相同,但词干提取与词形还原之间存在差异。由于以下原因,词形还原优于前者。
为什么词形还原优于词干提取?
词干提取算法通过从单词中剪切后缀来工作。广义上,它会剪切单词的开头或结尾。
相反,词形还原是一项更强大的操作,它会考虑单词的形态分析。它返回词形,这是其所有屈折形式的基本形式。创建词典并查找单词的正确形式需要深入的语言学知识。词干提取是一种通用操作,而词形还原是一种智能操作,它会在词典中查找正确形式。因此,词形还原有助于形成更好的机器学习特征。
区分词形还原和词干提取的代码
词干提取代码
import nltk
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
text = "studies studying cries cry"
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print("Stemming for {} is {}".format(w,porter_stemmer.stem(w)))
输出:
Stemming for studies is studi Stemming for studying is studi Stemming for cries is cri Stemming for cry is cri
词形还原代码
import nltk
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
text = "studies studying cries cry"
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print("Lemma for {} is {}".format(w, wordnet_lemmatizer.lemmatize(w)))
输出
Lemma for studies is study Lemma for studying is studying Lemma for cries is cry Lemma for cry is cry
输出讨论
如果您对 studies 和 studying 进行词干提取,输出是相同的(studi),但 NLTK 词形还原器为 studies 和 studying 提供了不同的词形 study 和 studying。因此,当我们需要制作特征集来训练机器时,如果优先使用词形还原会更好。
词形还原器的用例
词形还原器可最小化文本歧义。例如,bicycle 或 bicycles 等单词会转换为基本单词 bicycle。基本上,它会将所有含义相同但表示不同的单词转换为其基本形式。它减少了给定文本中的单词密度,并有助于为训练机器准备准确的特征。数据越干净,您的机器学习模型就越智能、越准确。NLTK 词形还原器还可以节省内存和计算成本。
显示 Wordnet 词形还原和 POS 标记在 Python 中使用的实时示例
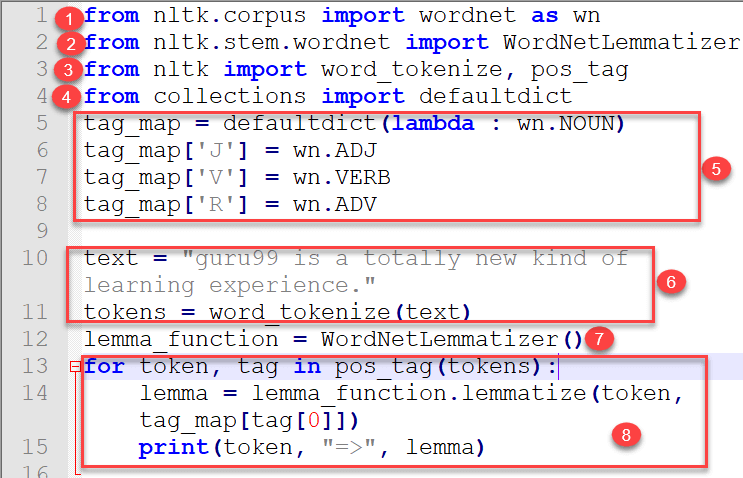
from nltk.corpus import wordnet as wn from nltk.stem.wordnet import WordNetLemmatizer from nltk import word_tokenize, pos_tag from collections import defaultdict tag_map = defaultdict(lambda : wn.NOUN) tag_map['J'] = wn.ADJ tag_map['V'] = wn.VERB tag_map['R'] = wn.ADV text = "guru99 is a totally new kind of learning experience." tokens = word_tokenize(text) lemma_function = WordNetLemmatizer() for token, tag in pos_tag(tokens): lemma = lemma_function.lemmatize(token, tag_map[tag[0]]) print(token, "=>", lemma)
代码解释
- 首先,导入了语料库阅读器 wordnet。
- 从 wordnet 导入了 WordNetLemmatizer。
- 从 nltk 导入了词语分词以及词性标记。
- 从 collections 导入了 Default Dictionary。
- 创建了一个字典,其中 pos_tag(首字母)是键值,其值映射到 wordnet 字典的值。我们只取了首字母,因为稍后将在循环中使用它。
- 编写了文本并进行了分词。
- 在此创建了一个将在循环中使用的 lemma_function 对象。
- 循环运行,lemmatize 将接受两个参数:一个是 token,另一个是 pos_tag 与 wordnet 值的映射。
输出:
guru99 => guru99 is => be totally => totally new => new kind => kind of => of learning => learn experience => experience . => .
Python 词形还原与WordNet 词典密切相关,因此研究该主题非常重要,所以我们将其作为下一个主题。