如何在 Windows/Mac 上下载和安装 NLTK
在Windows中安装NLTK
在本节中,我们将学习如何通过终端(Windows中的命令提示符)设置NLTK。
以下说明假定您尚未安装Python。因此,第一步是安装Python。
在Windows中安装Python
步骤1)转到链接https://pythonlang.cn/downloads/,然后为Windows选择最新版本。
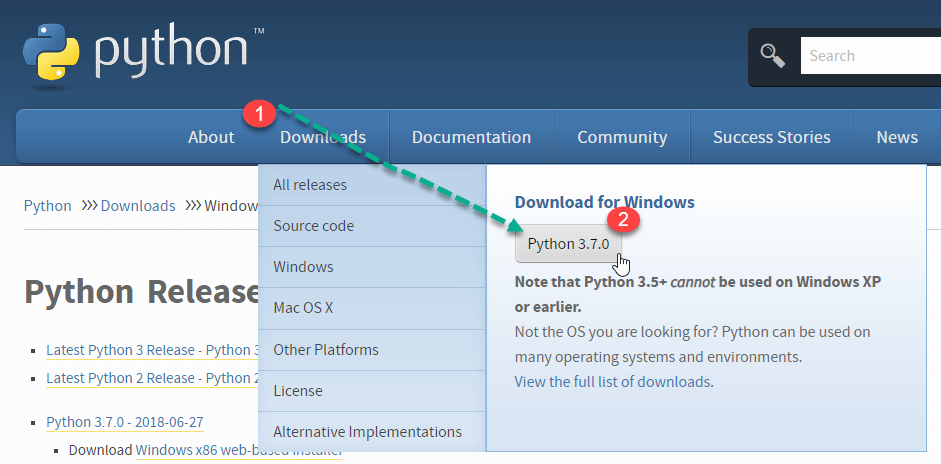
注意:如果您不想下载最新版本,可以访问下载选项卡查看所有发行版。
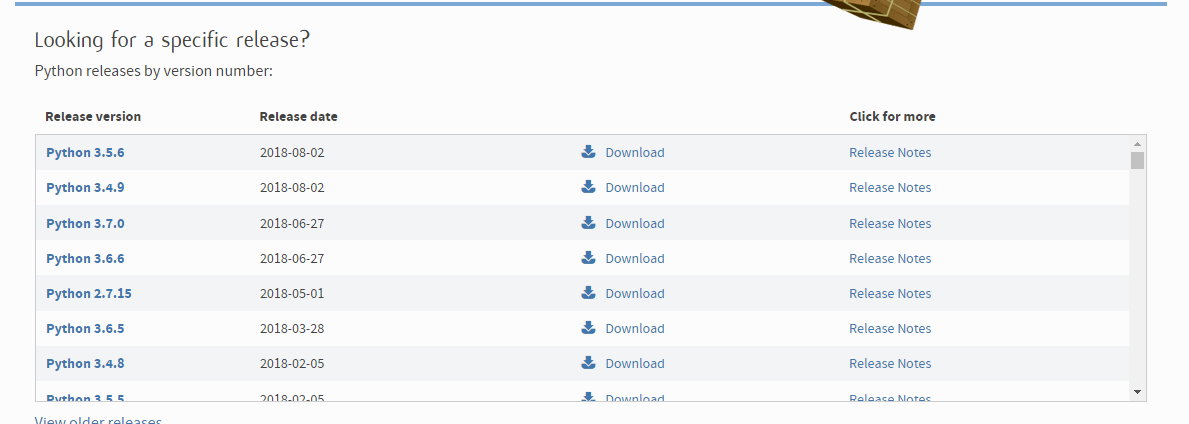
步骤2)点击下载的文件

步骤3)选择自定义安装
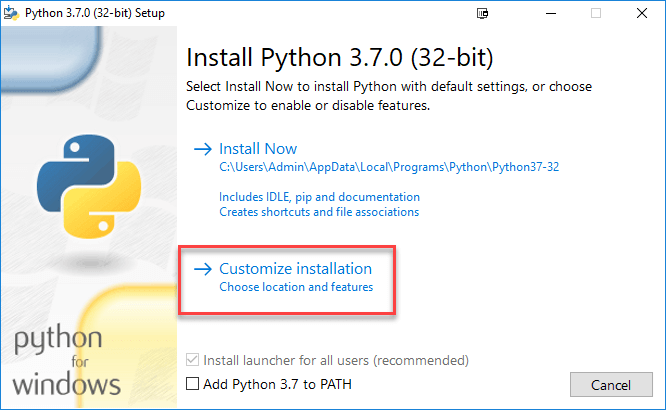
步骤4)点击“下一步”
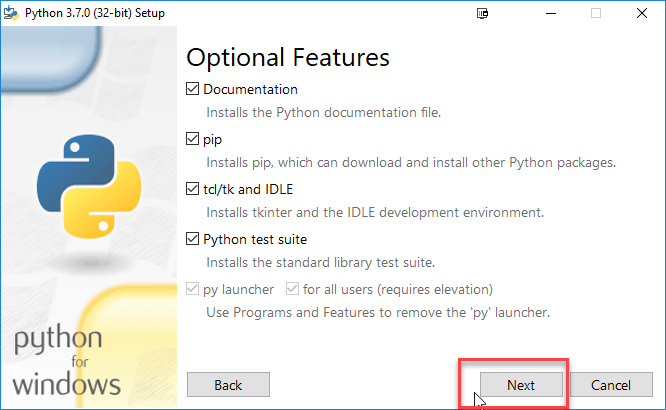
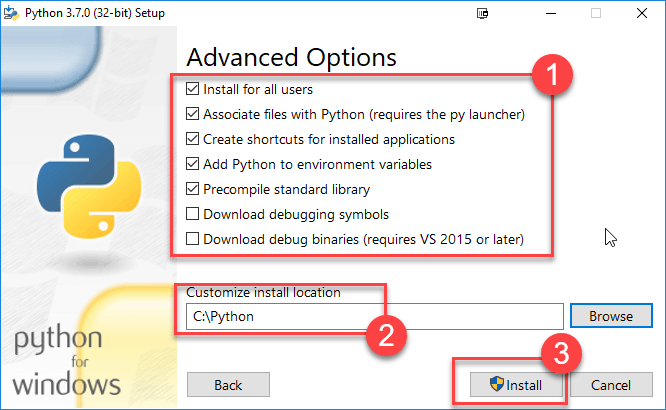
步骤5)在下一个屏幕上
- 选择高级选项
- 指定一个自定义安装位置。在我的例子中,为了方便操作,我选择了C盘上的一个文件夹。
- 单击安装
步骤6)安装完成后,点击“关闭”按钮。
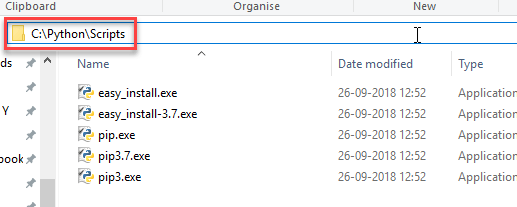
步骤7)复制Scripts文件夹的路径。
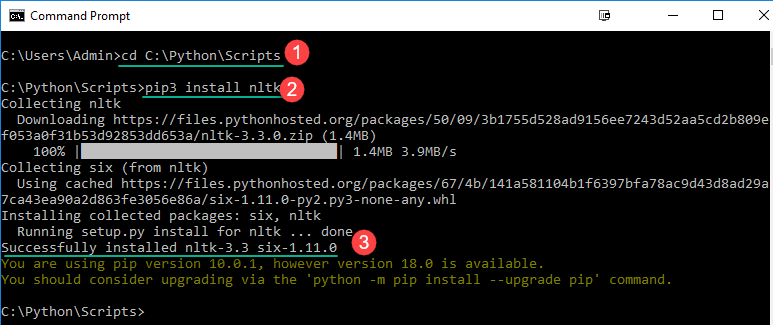
步骤8)在Windows命令提示符中
- 导航到pip文件夹的位置
- 输入命令以安装NLTK
pip3 install nltk
- 安装应该会成功完成
注意:对于Python2,请使用命令pip2 install nltk
步骤9)在Windows开始菜单中,搜索并打开PythonShell
步骤10)您可以通过提供以下命令来验证安装是否准确
import nltk

如果您看到没有错误,则表示安装已完成。
在Mac/Linux中安装NLTK
在Mac/Unix中安装NLTK需要Python包管理器pip来安装nltk。如果未安装pip,请按照以下说明完成此过程。
步骤1)键入以下命令更新包索引
sudo apt update
步骤2)为Python 3安装pip
sudo apt install python3-pip
您也可以使用easy_install安装pip。
sudo apt-get install python-setuptools python-dev build-essential
现在已安装easy_install。运行以下命令安装pip
sudo easy_install pip
步骤3)使用以下命令安装NLTK
sudo pip install -U nltk sudo pip3 install -U nltk
通过Anaconda安装NLTK
步骤1)请通过访问https://anaconda.net.cn/products/individual来安装Anaconda(也可用于安装不同的包),并选择您需要为Anaconda安装的Python版本。
注意:有关安装Anaconda的详细步骤,请参考本教程安装Anaconda
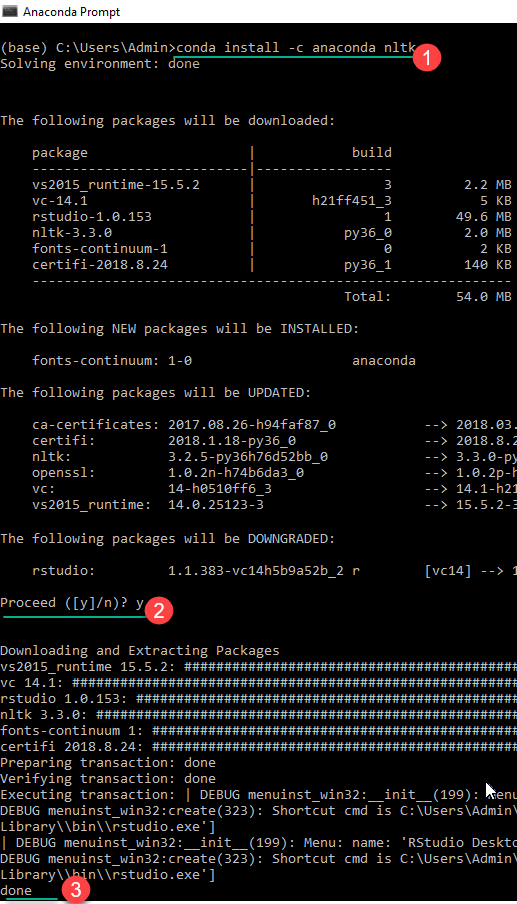
步骤2)在Anaconda提示符中,
- 输入命令
conda install -c anaconda nltk
- 审查包升级、降级、安装信息并输入“yes”。
- NLTK已下载并安装。
NLTK数据集
NLTK模块有许多可用的数据集,您需要下载才能使用。更专业地说,这被称为语料库。例如:stopwords、gutenberg、framenet_v15、large_grammars等。
如何下载NLTK的所有软件包
步骤1)在Windows或Linux中运行Python解释器
步骤 2)
- 输入命令
import nltk nltk.download ()
- 将打开NLTK下载窗口。点击“下载”按钮下载数据集。此过程将花费一些时间,具体取决于您的互联网连接。
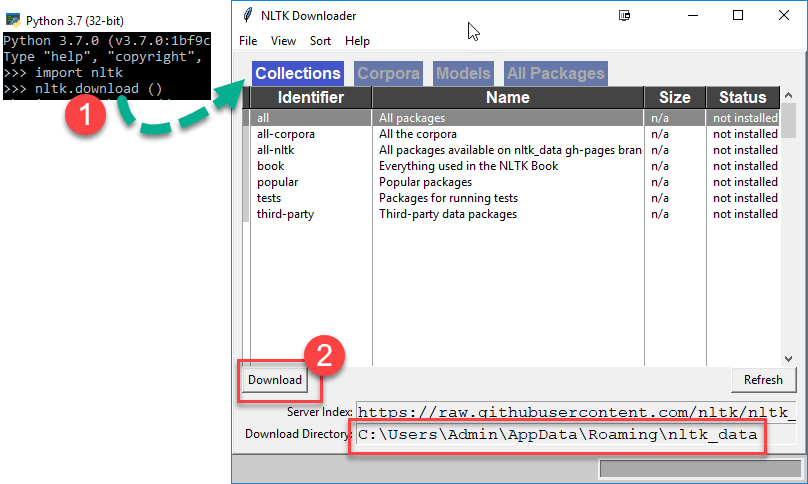
注意:您可以点击“文件”>“更改下载目录”来更改下载位置。
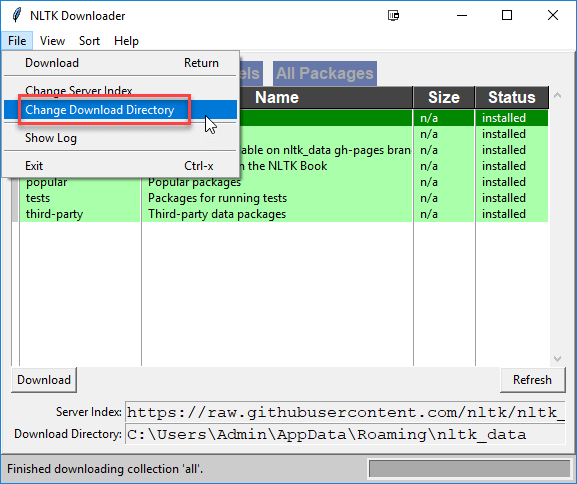
步骤3)要测试已安装的数据,请使用以下代码
>>> from nltk.corpus import brown >>>brown.words()
[‘The’, ‘Fulton’, ‘County’, ‘Grand’, ‘Jury’, ‘said’, …]

运行NLP脚本
我们将讨论如何在本地PC上执行NLP脚本。市场上有许多用于自然语言处理的库。因此,选择哪个库取决于是否满足您的要求。以下是NLP库的列表。
如何运行NLTK脚本
步骤1)在您喜欢的代码编辑器中,复制代码并将文件保存为“NLTKsample.py“
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)
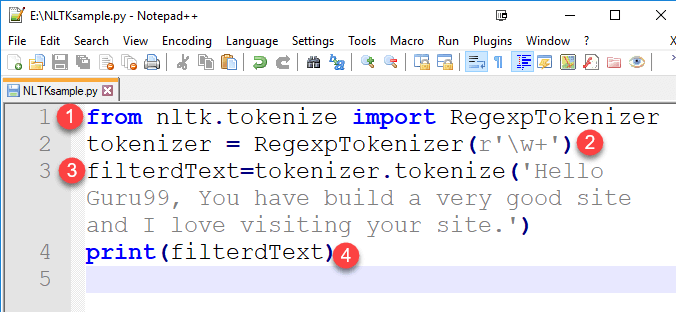
代码解释
- 在此程序中,目标是从给定文本中删除所有标点符号。我们导入了“RegexpTokenizer”,它是NLTK的一个模块。它可以删除您想要的任何表达式、符号、字符、数字或任何内容。
- 您只需将正则表达式传递给“RegexpTokenizer”模块。
- 之后,我们使用“tokenize”模块对单词进行分词。输出存储在“filterdText”变量中。
- 并使用“print()”打印它们。
步骤2)在命令提示符中
- 导航到您保存文件的位置
- 运行命令 Python NLTKsample.py
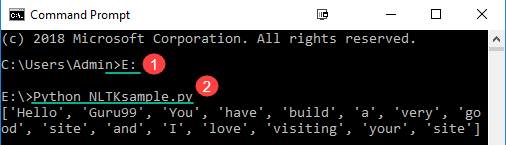
这将显示输出为:
[‘Hello’, ‘Guru99’, ‘You’, ‘have’, ‘build’, ‘a’, ‘very’, ‘good’, ‘site’, ‘and’, ‘I’, ‘love’, ‘visiting’, ‘your’, ‘site’]