使用 NLTK 进行词性标注和 NLP 中的语块分析 [示例]
词性标注
词性标注 (POS Tagging) 是一个将文本中的词语标记为特定词性的过程,依据是其定义和上下文。它负责读取语言文本,并为每个单词分配一个特定的标记(词性)。也称为语法标注。
让我们通过一个 NLTK 词性标注的例子来学习
输入: Everything to permit us.
输出: [(‘Everything’, NN),(‘to’, TO), (‘permit’, VB), (‘us’, PRP)]
词性标注示例涉及的步骤
- 分词 (word_tokenize)
- 将上面的步骤应用于 pos_tag,即 nltk.pos_tag(tokenize_text)
NLTK POS 标签示例如下
| 缩写 | 含义 |
|---|---|
| CC | 并列连词 |
| CD | 基数词 |
| DT | 限定词 |
| EX | 存在性词 "there" |
| FW | 外来词 |
| IN | 介词/从属连词 |
| JJ | 此 NLTK POS 标签是形容词(large) |
| JJR | 形容词,比较级(larger) |
| JJS | 形容词,最高级(largest) |
| LS | 列表标记 |
| MD | 情态动词(could, will) |
| NN | 名词,单数(cat, tree) |
| NNS | 名词,复数(desks) |
| NNP | 专有名词,单数(sarah) |
| NNPS | 专有名词,复数(indians or americans) |
| PDT | 前限定词(all, both, half) |
| POS | 所有格结尾(parent's) |
| PRP | 人称代词(hers, herself, him, himself) |
| PRP$ | 物主代词(her, his, mine, my, our) |
| RB | 副词(occasionally, swiftly) |
| RBR | 副词,比较级(greater) |
| RBS | 副词,最高级(biggest) |
| RP | 词缀(about) |
| TO | 不定式标记(to) |
| UH | 感叹词(goodbye) |
| VB | 动词(ask) |
| VBG | 动词 -ing形式(judging) |
| VBD | 动词,过去式(pleaded) |
| VBN | 动词,过去分词(reunified) |
| VBP | 动词,现在时,非第三人称单数(wrap) |
| VBZ | 动词,现在时,第三人称单数(bases) |
| WDT | wh-限定词(that, what) |
| WP | wh-代词(who) |
| WRB | wh-副词(how) |
上面的 NLTK POS 标签列表包含了所有 NLTK POS 标签。NLTK POS Tagger 用于为句子中的每个词分配语法信息。POS NLTK 所有包的安装、导入和下载都已完成。
NLP中的分块(Chunking)是什么?
分块 (Chunking) 在 NLP 中是一个将小信息块分组为大单元的过程。分块的主要用途是创建“名词短语”组。它通过结合 POS 标注和正则表达式来为句子添加结构。由此产生的词组被称为“块”。也称为浅层解析。
在浅层解析中,词根和叶子之间最多只有一个级别,而深层解析包含多个级别。浅层解析也称为轻量级解析或分块。
分块规则
没有预定义的规则,但您可以根据需要进行组合。
例如,您需要标记句子中的名词、动词(过去式)、形容词和并列连词。您可以使用以下规则:
chunk:{<NN.?>*<VBD.?>*<JJ.?>*<CC>?}
下表显示了各种符号的含义
| 符号名称 | 描述 |
|---|---|
| . | 除换行符外的任何字符 |
| * | 匹配 0 次或多次 |
| ? | 匹配 0 次或 1 次 |
现在让我们编写代码来更好地理解规则
from nltk import pos_tag
from nltk import RegexpParser
text ="learn php from guru99 and make study easy".split()
print("After Split:",text)
tokens_tag = pos_tag(text)
print("After Token:",tokens_tag)
patterns= """mychunk:{<NN.?>*<VBD.?>*<JJ.?>*<CC>?}"""
chunker = RegexpParser(patterns)
print("After Regex:",chunker)
output = chunker.parse(tokens_tag)
print("After Chunking",output)
输出
After Split: ['learn', 'php', 'from', 'guru99', 'and', 'make', 'study', 'easy']
After Token: [('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('guru99', 'NN'), ('and', 'CC'), ('make', 'VB'), ('study', 'NN'), ('easy', 'JJ')]
After Regex: chunk.RegexpParser with 1 stages:
RegexpChunkParser with 1 rules:
<ChunkRule: '<NN.?>*<VBD.?>*<JJ.?>*<CC>?'>
After Chunking (S
(mychunk learn/JJ)
(mychunk php/NN)
from/IN
(mychunk guru99/NN and/CC)
make/VB
(mychunk study/NN easy/JJ))
上述词性标注 Python 示例的结论: “make” 是一个动词,未包含在规则中,因此未被标记为 mychunk
分块的用例
分块用于实体检测。实体是句子中机器获取意图值的部分。
Example: Temperature of New York. Here Temperature is the intention and New York is an entity.
换句话说,分块用于选择标记的子集。请遵循以下代码来了解分块如何用于选择标记。在此示例中,您将看到与名词短语块对应的图。我们将编写代码并绘制图以便更好地理解。
演示用例的代码
import nltk
text = "learn php from guru99"
tokens = nltk.word_tokenize(text)
print(tokens)
tag = nltk.pos_tag(tokens)
print(tag)
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp =nltk.RegexpParser(grammar)
result = cp.parse(tag)
print(result)
result.draw() # It will draw the pattern graphically which can be seen in Noun Phrase chunking
输出
['learn', 'php', 'from', 'guru99'] -- These are the tokens
[('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('guru99', 'NN')] -- These are the pos_tag
(S (NP learn/JJ php/NN) from/IN (NP guru99/NN)) -- Noun Phrase Chunking
图表
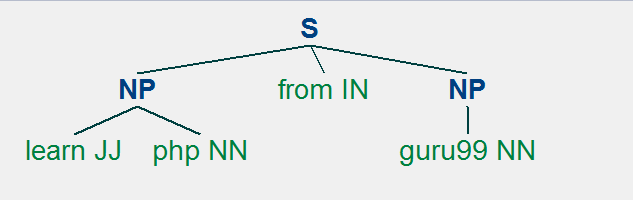
从图中可以看出,“learn”和“guru99”是两个不同的标记,但被归类为名词短语,而标记“from”不属于名词短语。
分块用于将不同的标记归类到同一个块中。结果将取决于所选的语法。进一步的分块 NLTK 用于标记模式和探索文本语料库。
词性标签计数
我们在上一节讨论了各种pos_tag。在本教程中,您将学习如何计数这些标签。标签计数对于文本分类以及为自然语言操作准备特征至关重要。我将与您讨论 guru99 在准备代码时遵循的方法以及对输出的讨论。希望这会有所帮助。
如何计数标签
在这里,我们首先编写工作代码,然后编写不同的步骤来解释代码。
from collections import Counter import nltk text = "Guru99 is one of the best sites to learn WEB, SAP, Ethical Hacking and much more online." lower_case = text.lower() tokens = nltk.word_tokenize(lower_case) tags = nltk.pos_tag(tokens) counts = Counter( tag for word, tag in tags) print(counts)
输出
Counter({‘NN’: 5, ‘,’: 2, ‘TO’: 1, ‘CC’: 1, ‘VBZ’: 1, ‘NNS’: 1, ‘CD’: 1, ‘.’: 1, ‘DT’: 1, ‘JJS’: 1, ‘JJ’: 1, ‘JJR’: 1, ‘IN’: 1, ‘VB’: 1, ‘RB’: 1})
代码详述
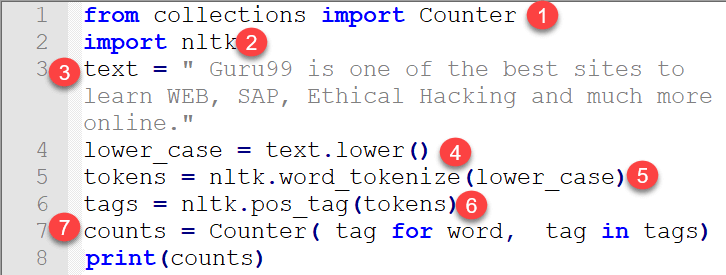
- 要计数标签,您可以使用 collections 模块中的 Counter 包。Counter 是一个字典子类,它基于键值操作原理工作。它是一个无序集合,其中元素存储为字典键,计数是它们的值。
- 导入 nltk,其中包含标记文本的模块。
- 编写您想计算其 pos_tag 的文本。
- 有些单词是大写,有些是小写,所以在应用分词之前将所有单词转换为小写是合适的。
- 通过 nltk 的 word_tokenize 处理单词。
- 计算每个标记的 pos_tag
Output = [('guru99', 'NN'), ('is', 'VBZ'), ('one', 'CD'), ('of', 'IN'), ('the', 'DT'), ('best', 'JJS'), ('site', 'NN'), ('to', 'TO'), ('learn', 'VB'), ('web', 'NN'), (',', ','), ('sap', 'NN'), (',', ','), ('ethical', 'JJ'), ('hacking', 'NN'), ('and', 'CC'), ('much', 'RB'), ('more', 'JJR'), ('online', 'JJ')] - 现在轮到字典计数器发挥作用了。我们在第 1 行代码中导入了它。单词是键,标签是值,计数器将计算文本中存在的每个标签的总数。
频率分布
频率分布是指实验结果发生次数的多少。它用于查找文档中每个单词的出现频率。它使用FreqDistclass,并由nltk.probabilty模块定义。
频率分布通常是通过计算重复运行实验的样本来创建的。每次计数增加一。例如:
freq_dist = FreqDist()
for the token in the document
freq_dist.inc(token.type())
对于任何单词,我们可以检查它在特定文档中出现了多少次。例如:
- count 方法: freq_dist.count(‘and’)此表达式返回“and”出现的次数。这称为 count 方法。
- frequency 方法: freq_dist.freq(‘and’)此表达式返回给定样本的频率。
我们将编写一个小型程序并详细解释其工作原理。我们将编写一些文本并计算文本中每个单词的频率分布。
import nltk a = "Guru99 is the site where you can find the best tutorials for Software Testing Tutorial, SAP Course for Beginners. Java Tutorial for Beginners and much more. Please visit the site guru99.com and much more." words = nltk.tokenize.word_tokenize(a) fd = nltk.FreqDist(words) fd.plot()
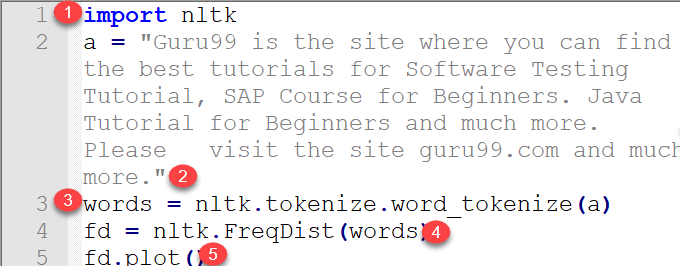
代码解释
- 导入 nltk 模块。
- 编写需要查找单词分布的文本。
- 分词文本中的每个单词,它作为输入提供给 nltk 的 FreqDist 模块。
- 将每个单词以列表形式应用于 nlk.FreqDist
- 使用 plot() 在图中绘制单词
请可视化图形以更好地理解所写的文本
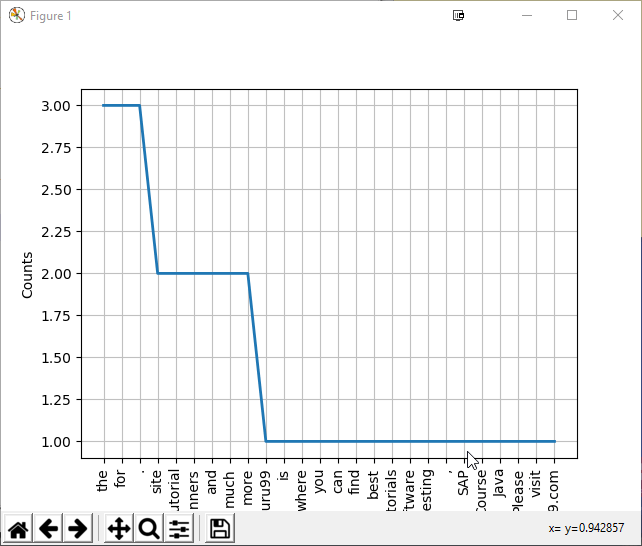
注意:您需要安装 matplotlib 才能查看上面的图
观察上面的图。它对应于计算文本中每个单词的出现次数。它有助于文本研究以及实现基于文本的情感分析。简而言之,可以得出结论,nltk 有一个用于计数文本中每个单词出现次数的模块,这有助于准备自然语言统计特征。它在查找文本中的关键字方面起着重要作用。您还可以使用 extract、PyPDF2 等库从 pdf 中提取文本,并将文本馈送到 nlk.FreqDist。
关键术语是“分词”。分词后,它会检查给定段落或文本文档中的每个单词,以确定其出现的次数。您不需要 NLTK 工具包来实现此目的。您也可以使用自己的 Python 编程技巧来实现。NLTK 工具包仅为各种操作提供现成的代码。
计数每个单词可能没什么用。相反,人们应该关注共现词和二元语法,它们处理成对的许多单词。这些对可以识别有用的关键字,从而更好地进行自然语言特征提取,并可以输入到机器中。有关详细信息,请参见下文。
搭配:二元语法和三元语法
什么是共现词?
共现词是文档中经常一起出现的单词对。它是通过这些一起出现的对数与文档的总词数来计算的。
考虑电磁频谱,其中包含诸如紫外线、红外线之类的词。
词“ultraviolet”和“rays”不能单独使用,因此可以视为共现词。另一个例子是 CT 扫描。我们不说 CT 和 Scan 分别说,因此它们也被视为共现词。
我们可以说,查找共现词需要计算单词的频率以及它们与其他单词的上下文中的出现。这些特定的单词集合需要进行过滤以保留有用的内容术语。然后,可以将每个词语根据某些关联度量进行评分,以确定每个 n-gram 是共现词的相对可能性。
共现词可分为两类:
- 二元语法:两个词的组合
- 三元语法:三个词的组合
二元语法和三元语法为特征提取阶段提供了更有意义和更有用的特征。它们在基于文本的情感分析中尤其有用。
二元语法示例代码
import nltk text = "Guru99 is a totally new kind of learning experience." Tokens = nltk.word_tokenize(text) output = list(nltk.bigrams(Tokens)) print(output)
输出
[('Guru99', 'is'), ('is', 'totally'), ('totally', 'new'), ('new', 'kind'), ('kind', 'of'), ('of', 'learning'), ('learning', 'experience'), ('experience', '.')]
三元语法示例代码
有时,为了进行统计分析和频率计数,查看句子中的三个词对变得很重要。这在形成 NLP(自然语言处理特征)和基于文本的情感预测方面再次发挥着至关重要的作用。
计算三元语法的代码与此相同。
import nltk text = “Guru99 is a totally new kind of learning experience.” Tokens = nltk.word_tokenize(text) output = list(nltk.trigrams(Tokens)) print(output)
输出
[('Guru99', 'is', 'totally'), ('is', 'totally', 'new'), ('totally', 'new', 'kind'), ('new', 'kind', 'of'), ('kind', 'of', 'learning'), ('of', 'learning', 'experience'), ('learning', 'experience', '.')]
标注句子
更广泛地说,句子标注是指根据句子上下文添加动词、名词等标签。词性标签的识别是一个复杂的过程。因此,词性的通用标注在手动上是不可能的,因为某些单词根据句子结构可能有不同的(模糊的)含义。在标注之前将文本转换为列表形式是一个重要的步骤,因为列表中的每个单词都会被循环并计算特定标签。请参阅下面的代码以更好地理解
import nltk text = "Hello Guru99, You have to build a very good site, and I love visiting your site." sentence = nltk.sent_tokenize(text) for sent in sentence: print(nltk.pos_tag(nltk.word_tokenize(sent)))
输出
[(‘Hello’, ‘NNP’), (‘Guru99’, ‘NNP’), (‘,’, ‘,’), (‘You’, ‘PRP’), (‘have’, ‘VBP’), (‘build’, ‘VBN’), (‘a’, ‘DT’), (‘very’, ‘RB’), (‘good’, ‘JJ’), (‘site’, ‘NN’), (‘and’, ‘CC’), (‘I’, ‘PRP’), (‘love’, ‘VBP’), (‘visiting’, ‘VBG’), (‘your’, ‘PRP$’), (‘site’, ‘NN’), (‘.’, ‘.’)]
代码解释
- 导入 nltk(包含句子分词和单词分词等子模块的自然语言工具包)的代码
- 要打印其标签的文本。
- 句子分词
- 实现了 for 循环,其中从句子中分词,并打印每个单词的标签作为输出。
语料库中有两种 POS 标注器
- 基于规则
- 随机 POS 标注器
1. 基于规则的 POS 标注器:对于含义模糊的词语,则基于规则的方法根据上下文信息进行应用。这是通过检查或分析前一个或后一个单词的含义来完成的。信息来自单词的周围环境或单词本身。因此,单词通过特定语言的语法规则进行标记,例如大写和标点符号。例如,Brill 的标注器。
2. 随机 POS 标注器:此方法下应用频率或概率等不同方法。如果一个词在训练集中主要用某个特定标签标记,那么在测试句子中它就会被赋予该特定标签。单词标签不仅取决于其自身的标签,还取决于前一个标签。此方法并不总是准确的。另一种方法是计算特定标签在句子中出现的概率。因此,通过检查单词与特定标签的最高概率来计算最终标签。
使用隐马尔可夫模型进行词性标注
可以使用 HMM 对标注问题进行建模。它将输入标记视为可观察序列,而将标签视为隐藏状态,目标是确定隐藏状态序列。例如x = x1,x2,…………,xn,其中 x 是标记序列,而y = y1,y2,y3,y4………yn是隐藏序列。
隐马尔可夫模型 (HMM) 如何工作?
HMM 使用联合分布 P(x, y),其中 x 是输入序列/标记序列,y 是标签序列。
x 的标签序列将是 argmaxy1….ynp(x1,x2,….xn,y1,y2,y3,…..)。我们已经对文本中的标签进行了分类,但这些标签的统计数据至关重要。因此,下一部分是计数这些标签以进行统计研究。
摘要
- NLTK 中的 POS 标注是一个基于定义和上下文将文本中的词语标记为特定词性的过程。
- 一些 NLTK POS 标注示例包括:CC、CD、EX、JJ、MD、NNP、PDT、PRP$、TO 等。
- POS 标注器用于为句子中的每个词分配语法信息。使用 NLTK 进行词性标注的所有包的安装、导入和下载均已完成。
- NLP 中的分块是一个将小信息块分组为大单元的过程。
- 没有预定义的规则,但您可以根据需要进行组合。
- 分块用于实体检测。实体是句子中机器获取意图值的部分。
- 分块用于将不同的标记归类到同一个块中。