语法分析:编译器自顶向下与自底向上解析类型
什么是语法分析?
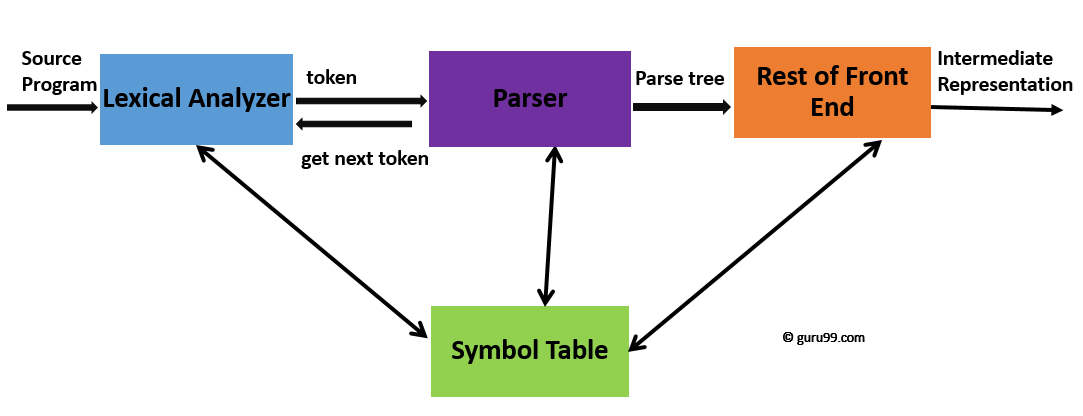
语法分析是编译器设计过程的第二个阶段,在这个阶段,将检查给定的输入字符串是否符合形式语法的规则和结构。它分析语法结构,并检查给定的输入是否符合编程语言的正确语法。
在编译器设计过程中,语法分析发生在词法分析阶段之后。它也称为解析树或语法树。解析树是借助语言的预定义语法构建的。语法分析器还检查给定的程序是否满足上下文无关文法所隐含的规则。如果满足,解析器将创建该源程序的解析树。否则,它将显示错误消息。
为什么需要语法分析器?
- 检查代码在语法上是否有效
- 语法分析器有助于您将规则应用于代码
- 帮助您确保每个开括号都有相应的闭括号
- 每个声明都有一个类型,并且该类型必须存在
重要的语法分析器术语
语法分析过程中使用的重要术语
- 句子:句子是某个字母表上的一组字符。
- 词素:词素是语言的最低语法单元(例如,total、start)。
- 标记:标记只是词素的一个类别。
- 关键字和保留字:它是标识符,用作语句语法的固定部分。它是您不能用作变量名或标识符的保留字。
- 噪声词:噪声词是可选的,可以插入语句中以增强句子可读性。
- 注释:它是文档非常重要的部分。它通常显示为 /* */ 或 // 空格(空格)
- 分隔符:它是标记语法单元开始或结束的语法元素。例如,语句或表达式,“begin”…”end” 或 {}。
- 字符集:ASCII、Unicode
- 标识符:它对长度有限制,这有助于降低句子可读性。
- 运算符符号:+ 和 - 执行两个基本的算术运算。
- 语言的语法元素
为什么我们需要解析?
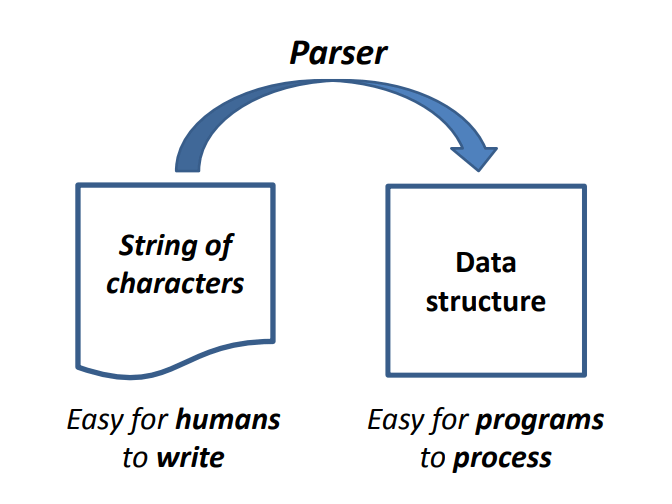
解析器还检查输入字符串是否格式正确,如果不正确,则拒绝它。
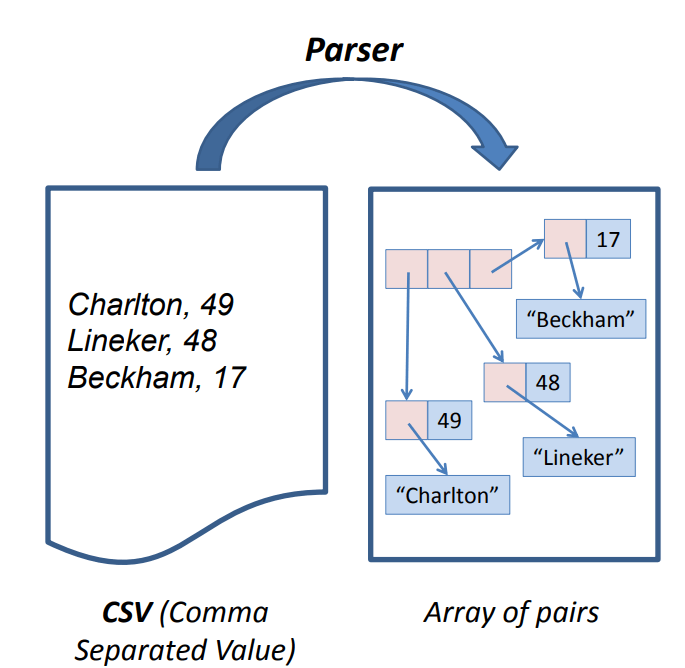
以下是解析器在编译器设计中执行的重要任务
- 帮助您检测所有类型的语法错误
- 查找错误发生的位置
- 对错误的清晰准确的描述。
- 从错误中恢复以继续查找代码中的其他错误。
- 不应影响“正确”程序的编译。
- 解析器必须通过报告语法错误来拒绝无效文本
解析技术
解析技术分为两类
- 自顶向下解析,
- 自底向上解析
自顶向下解析
在自顶向下解析中,解析树的构建从根开始,然后向叶子移动。
自顶向下解析有两种类型:
- 预测性解析
预测性解析可以预测应该使用哪个产生式来替换特定的输入字符串。预测性解析器使用前瞻点,该点指向下一个输入符号。回溯不是此解析技术的问题。它被称为 LL(1) 解析器。
- 递归下降解析
此解析技术通过递归解析输入来构建解析树。它包含多个小程序,每个小程序对应文法中的一个非终结符。
自底向上解析
在编译器设计的自底向上解析中,解析树的构建从叶子开始,然后处理到根。它也称为移进-归约解析。编译器设计中的这种类型的解析是使用一些软件工具创建的。
错误恢复方法
系统软件中解析时发生的常见错误
- 词法错误:拼写错误的标识符名称
- 语法错误:括号不匹配或缺少分号
- 语义错误:值分配不兼容
- 逻辑错误:无限循环和不可达代码
解析器应能够检测并报告程序中发现的任何错误。因此,当解析器出现错误时。它应该能够处理它并继续解析剩余的输入。程序在各种编译过程阶段可能会出现以下类型的错误。解析器中有五种常见的错误恢复方法可以实现。
语句模式恢复
- 当解析器遇到错误时,它有助于采取纠正措施。这允许解析剩余的输入和状态。
- 例如,添加缺失的分号属于语句模式恢复方法。但是,解析设计者在进行这些更改时需要小心,因为一个错误的更正可能导致无限循环。
恐慌模式恢复
- 当解析器遇到错误时,此模式会忽略该语句的其余部分,并且不从错误输入处理到分隔符(如分号)。这是一种简单的错误恢复方法。
- 在此类恢复方法中,解析器逐个拒绝输入符号,直到找到一组指定的同步令牌。同步令牌通常使用分隔符,如“;”或“}”。
短语级恢复
- 编译器通过插入或删除令牌来纠正程序。这允许它从中断处继续解析。它对剩余的输入执行更正。它可以将剩余输入的某个前缀替换为某个字符串,这有助于解析器继续处理。
错误产生式
- 错误产生式恢复会扩展语言的文法,该文法会生成错误构造。然后,解析器对该构造执行错误诊断。
全局纠错
- 编译器在处理不正确的输入字符串时应尽量减少更改次数。给定不正确的输入字符串 a 和文法 c,算法将搜索与字符串 b 相关的解析树。例如,在 a 转换为 b 时所需的令牌插入、删除和修改应尽可能少。
文法
文法是一组描述语言的结构规则。文法为任何句子分配结构。此术语还指这些规则的研究,该文件包括形态学、音韵学和句法。它能够描述许多编程语言的语法。
文法形式规则
- 非终结符应出现在至少一个产生式的左侧
- 目标符号绝不应显示在任何产生式的 ::= 右侧
- 如果 LHS 出现在 RHS 中,则该规则是递归的
符号约定
符号的约定可能通过将元素括在方括号中来指示。它是元素实例的任意序列,可以通过将元素括在花括号中后跟星号{*” 来指示。{ … }*。
它是替代项的选择,可以在单个规则中使用该符号。如有必要,可以使用括号 ([ , ] ) 将其括起来。
有两种约定:终结符和非终结符
1.终结符
- 字母表中的小写字母,如 a、b、c、
- 运算符符号,如 +、-、* 等。
- 标点符号,如括号、井号、逗号
- 0、1、...、9 数字
- 粗体字符串,如 id 或 if,任何代表单个终结符的字符
2.非终结符
- 大写字母,如 A、B、C
- 小写斜体名称:expression 或 some
上下文无关文法
CFG 是一个左递归文法,它至少有一个产生式。上下文无关文法中的规则主要是递归的。语法分析器检查特定程序是否满足上下文无关文法的所有规则。如果满足这些规则,语法分析器可以为该程序创建解析树。
expression -> expression -+ term expression -> expression – term expression-> term term -> term * factor term -> expression/ factor term -> factor factor factor -> ( expression ) factor -> id
文法推导
文法推导是将开始符号转换为字符串的文法规则序列。推导证明该字符串属于文法的语言。
最左推导
当输入的可 sentential form 从左到右扫描并替换时,称为最左推导。通过最左推导得出的可 sentential form 称为左-sentential form。
最右推导
最右推导使用产生式规则,从右到左扫描并替换输入。这称为最右推导。通过最右推导得出的可 sentential form 称为右-sentential form。
语法与词法分析器
| 语法分析器 | 词法分析器 |
|---|---|
| 语法分析器主要处理语言的递归结构。 | 词法分析器简化了语法分析器的任务。 |
| 语法分析器作用于源程序中的标记,以识别编程语言中有意义的结构。 | 词法分析器识别源程序中的标记。 |
| 它接收来自词法分析器的令牌形式的输入。 | 它负责由...提供的令牌的有效性
语法分析器 |
使用语法分析器的缺点
- 它从不确定令牌是否有效。
- 不帮助您确定是否对令牌类型执行了有效操作。
- 您无法确定令牌在使用前是否已声明并初始化。
摘要
- 语法分析是编译器设计过程的第二个阶段,发生在词法分析之后。
- 语法分析器有助于您将规则应用于代码
- 句子、词素、标记、关键字和保留字、噪声词、注释、分隔符、字符集、标识符是一些用于编译器构造中的语法分析的重要术语。
- 解析器检查输入字符串是否格式正确,如果不正确,则拒绝它。
- 解析技术分为两类:自顶向下解析、自底向上解析。
- 词法、语法、语义和逻辑是解析过程中发生的一些常见错误。
- 文法是一组描述语言的结构规则。
- 符号的约定可能通过将元素括在方括号中来指示。
- CFG 是一个左递归文法,它至少有一个产生式。
- 文法推导是将开始符号转换为字符串的文法规则序列。
- 语法分析器主要处理语言的递归结构,而词法分析器则简化了DBMS中语法分析器的任务。
- 语法分析器方法的缺点是它从不确定令牌是否有效。