编译器阶段及示例:编译过程和步骤
编译器设计有哪些阶段?
编译器在各个阶段运行,每个阶段都将源程序从一种表示形式转换为另一种表示形式。每个阶段都接收前一个阶段的输入,并将其输出馈送到编译器的下一阶段。
编译器有 6 个阶段。每个阶段都帮助将高级语言转换为机器代码。编译器的阶段包括:
- 词法分析
- 语法分析
- 语义分析
- 中间代码生成器
- 代码优化器
- 代码生成器
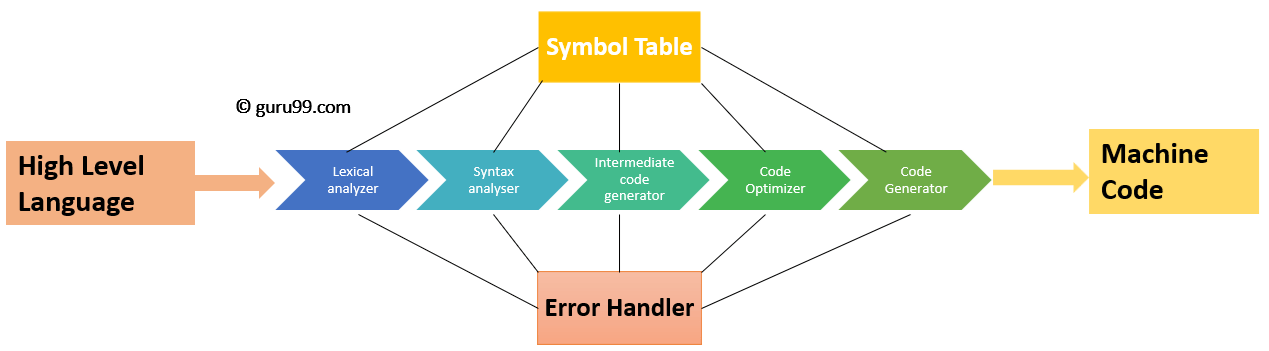
所有这些阶段通过将源代码分解为词法单元、创建解析树以及通过不同阶段优化源代码来转换源代码。
阶段 1:词法分析
词法分析是编译器扫描源代码的第一个阶段。此过程可以逐个字符地从左到右进行,并将这些字符分组为词法单元。
在这里,通过识别词法单元,将源程序的字符流分组为有意义的序列。它将相应的词法单元录入符号表,并将该词法单元传递给下一阶段。
此阶段的主要功能是:
- 识别源代码中的词法单元
- 将词法单元分类到常量、保留字等类别中,并将它们输入到不同的表中。它会忽略源程序中的注释。
- 识别不是语言一部分的词法单元
示例:
x = y + 10
词法单元
| X | 标识符 |
| = | 赋值运算符 |
| Y | 标识符 |
| + | 加法运算符 |
| 10 | 数字 |
阶段 2:语法分析
语法分析就是发现代码的结构。它确定文本是否遵循预期的格式。此阶段的主要目的是确保程序员编写的源代码是正确的。
语法分析基于特定编程语言的规则,通过词法单元构建解析树。它还确定源语言的结构以及语言的语法或文法。
以下是此阶段执行的任务列表:
- 从词法分析器获取词法单元
- 检查表达式是否在语法上正确
- 报告所有语法错误
- 构建一个称为解析树的分层结构
示例
任何标识符/数字都是一个表达式
如果 x 是标识符,y+10 是表达式,那么 x= y+10 是一个语句。
考虑以下示例的解析树
(a+b)*c
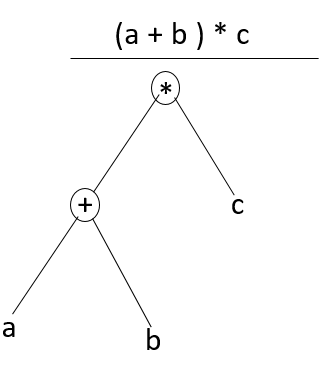
在解析树中
- 内部节点:记录,带有一个运算符字段和两个子节点字段
- 叶子:记录,带 2 个或更多字段;一个用于词法单元,另一个用于词法单元的信息
- 确保程序的组成部分有意义地组合在一起
- 收集类型信息并检查类型兼容性
- 检查操作数是否被源语言允许
阶段 3:语义分析
语义分析检查代码的语义一致性。它使用前一阶段的语法树和符号表来验证给定的源代码在语义上是否一致。它还检查代码是否传达了恰当的含义。
语义分析器会检查类型不匹配、不兼容的操作数、参数不正确的函数调用、未声明的变量等。
语义分析阶段的功能包括:
- 帮助您存储收集到的类型信息并将其保存在符号表或语法树中
- 允许您执行类型检查
- 在类型不匹配的情况下,当没有能够满足所需操作的确切类型转换规则时,会显示语义错误。
- 收集类型信息并检查类型兼容性
- 检查源语言是否允许操作数
示例
float x = 20.2; float y = x*30;
在上述代码中,语义分析器将在乘法之前将整数 30 类型转换为浮点数 30.0。
阶段 4:中间代码生成
一旦语义分析阶段完成,编译器就会为目标机器生成中间代码。它表示某种抽象机的程序。
中间代码位于高级语言和机器级语言之间。此中间代码的生成方式应使其易于转换为目标机器代码。
中间代码生成的功能
- 应从源程序的语义表示生成
- 保存翻译过程中计算的值
- 帮助您将中间代码转换为目标语言
- 允许您维护源语言的优先级顺序
- 它保存了指令的正确操作数数量
示例
例如,
total = count + rate * 5
通过地址码方法进行的中间代码是:
t1 := int_to_float(5) t2 := rate * t1 t3 := count + t2 total := t3
阶段 5:代码优化
下一个阶段是代码优化或中间代码。此阶段删除不必要的代码行并安排语句序列,以在不浪费资源的情况下加快程序执行速度。此阶段的主要目标是改进中间代码,以生成运行速度更快、占用空间更小的代码。
此阶段的主要功能是:
- 它有助于您在执行速度和编译速度之间取得平衡
- 提高目标程序的运行时间
- 生成精简的代码,但仍为中间表示
- 删除不可达代码并消除未使用变量
- 删除循环中未更改的语句
示例
考虑以下代码:
a = intofloat(10) b = c * a d = e + b f = d
可以成为
b =c * 10.0 f = e+b
阶段 6:代码生成
代码生成是编译器的最后一个阶段。它接收代码优化阶段的输入,并生成页面代码或对象代码作为结果。此阶段的目的是分配存储并生成可重定位的机器代码。
它还为变量分配内存位置。中间代码中的指令被转换为机器指令。此阶段将优化或中间代码转换为目标语言。
目标语言是机器代码。因此,所有内存位置和寄存器也在此阶段进行选择和分配。此阶段生成的代码用于获取输入并生成预期的输出。
示例
a = b + 60.0
可能会被翻译成寄存器。
MOVF a, R1 MULF #60.0, R2 ADDF R1, R2
符号表管理
符号表包含每个标识符的记录,其中包含标识符属性的字段。此组件使编译器更容易搜索标识符记录并快速检索。符号表还有助于作用域管理。符号表和错误处理程序与所有阶段进行交互,并相应地更新符号表。
错误处理例程
在编译器设计过程中,错误可能出现在以下所有阶段:
- 词法分析器:拼写错误的词法单元
- 语法分析器:缺少括号
- 中间代码生成器:运算符的操作数不匹配
- 代码优化器:当语句不可达时
- 代码生成器:当内存已满或未分配适当的寄存器时
- 符号表:多重声明标识符的错误
最常见的错误是扫描中的无效字符序列、类型中的无效词法单元序列、作用域错误以及语义分析中的解析错误。
在任何上述阶段都可能遇到错误。找到错误后,该阶段需要处理错误以继续编译过程。这些错误需要报告给错误处理程序,由错误处理程序执行编译过程。通常,错误会以消息的形式报告。
摘要
- 编译器在各个阶段运行,每个阶段都将源程序从一种表示形式转换为另一种表示形式
- 编译器设计的六个阶段是:1) 词法分析 2) 语法分析 3) 语义分析 4) 中间代码生成器 5) 代码优化器 6) 代码生成器
- 词法分析是编译器扫描源代码的第一个阶段
- 语法分析就是发现文本的结构
- 语义分析检查代码的语义一致性
- 一旦语义分析阶段完成,编译器就会为目标机器生成中间代码
- 代码优化阶段删除不必要的代码行并安排语句序列
- 代码生成阶段接收代码优化阶段的输入,并生成页面代码或对象代码作为结果
- 符号表包含每个标识符的记录,其中包含标识符属性的字段
- 错误处理例程在多个阶段处理错误并报告错误