编译器设计中的词法分析(分析器)及其示例
什么是词法分析?
词法分析是编译器设计中的第一个阶段。词法分析器接收以句子形式编写的修改后的源代码。换句话说,它帮助您将字符序列转换为标记(token)序列。词法分析器将这种语法分解为一系列标记。它会移除源代码中任何多余的空格或注释。
在编译器设计中执行词法分析的程序称为词法分析器或词法器。词法器包含分词器或扫描器。如果词法分析器检测到标记无效,它会生成一个错误。词法分析器在编译器设计中的作用是从源代码读取字符流,检查合法标记,并在语法分析器请求时将数据传递给它。
示例
How Pleasant Is The Weather?
看这个词法分析示例;在这里,我们可以轻松识别出“How Pleasant”、“The”、“Weather”、“Is”这五个单词。这对我们来说很自然,因为我们可以识别分隔符、空格和标点符号。
HowPl easantIs Th ewe ather?
现在,看看这个例子,我们也能够读出。但是,这需要一些时间,因为分隔符被放在了不寻常的位置。它不是立即就能明白的东西。
基本术语
什么是词元(lexeme)?
词元(lexeme)是源代码程序中根据标记的匹配模式包含的一系列字符。它只不过是标记的一个实例。
什么是标记(token)?
编译器设计中的标记是源代码程序中代表信息单元的字符序列。
什么是模式(Pattern)?
模式是标记使用的描述。对于用作标记的关键字,模式是字符序列。
词法分析器架构:标记如何被识别
词法分析的主要任务是读取代码中的输入字符并生成标记。
词法分析器扫描程序的整个源代码。它一次识别一个标记。扫描器通常实现为仅在解析器请求时生成标记。以下是编译器设计中标记识别的工作方式:
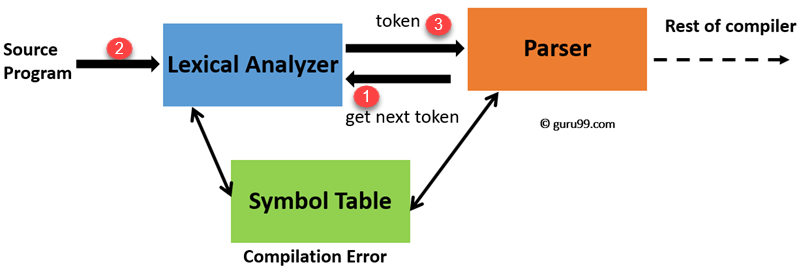
- “获取下一个标记”是从解析器发送到词法分析器的命令。
- 收到此命令后,词法分析器会扫描输入,直到找到下一个标记。
- 它将标记返回给解析器。
词法分析器在创建标记时会跳过空格和注释。如果存在任何错误,词法分析器将该错误与源文件和行号相关联。
词法分析器的作用
词法分析器执行以下任务
- 帮助在符号表中标识标记
- 从源程序中移除空格和注释
- 将错误消息与源程序相关联
- 如果源代码中发现宏,则帮助扩展宏
- 从源程序读取输入字符
词法分析、标记、非标记示例
考虑输入到词法分析器的以下代码
#include <stdio.h>
int maximum(int x, int y) {
// This will compare 2 numbers
if (x > y)
return x;
else {
return y;
}
}
创建的标记示例
| 词元 | 标记 |
|---|---|
| int | 关键字 |
| maximum | 标识符 |
| ( | 运算符 |
| int | 关键字 |
| x | 标识符 |
| , | 运算符 |
| int | 关键字 |
| Y | 标识符 |
| ) | 运算符 |
| { | 运算符 |
| If | 关键字 |
非标记示例
| 类型 | 示例 |
|---|---|
| 注释 | // 这个会比较 2 个数字 |
| 预处理器指令 | #include <stdio.h> |
| 预处理器指令 | #define NUMS 8,9 |
| 宏 | NUMS |
| 空白符 | /n /b /t |
词法错误
无法扫描为任何有效标记的字符序列是词法错误。关于词法错误的要点:
- 词法错误并不常见,但应由扫描器处理。
- 标识符、运算符、关键字拼写错误被视为词法错误。
- 通常,词法错误是由出现非法字符引起的,通常在标记的开头。
词法分析器中的错误恢复
以下是一些最常见的错误恢复技术:
- 从剩余输入中移除一个字符
- 在恐慌模式下,会一直忽略连续字符,直到我们遇到一个格式正确的标记。
- 通过在剩余输入中插入缺失的字符
- 用另一个字符替换一个字符
- 交换两个连续的字符
词法分析器与解析器
| 词法分析器 | 解析器 |
|---|---|
| 扫描输入程序 | 执行语法分析 |
| 识别标记 | 创建代码的抽象表示 |
| 将标记插入符号表 | 更新符号表条目 |
| 它会生成词法错误 | 它生成源代码的解析树 |
为什么要区分词法分析器和解析器?
- 设计的简洁性:通过消除不必要的标记,简化了词法分析和语法分析的过程
- 提高编译器效率:帮助您提高编译器效率
- 专业化:可以应用专业技术来改进词法分析过程
- 可移植性:只有扫描器需要与外部世界进行通信
- 更高的可移植性:输入设备特定的特殊性仅限于词法器
词法分析的优点
- 词法分析器方法被编译器等程序使用,这些程序可以利用程序员代码的解析数据来创建编译的二进制可执行代码。
- 它被网络浏览器用于格式化和显示网页,借助从JavaScript、HTML、CSS解析的数据。
- 一个独立的词法分析器可以帮助您为该任务构建一个专业且可能更高效的处理器。
词法分析的缺点
- 您需要花费大量时间阅读源代码程序,并将其划分为标记形式。
- 与 PEG 或 EBNF 规则相比,某些正则表达式相当难以理解。
- 开发和调试词法器及其标记描述需要付出更多努力。
- 生成词法器表和构建标记需要额外的运行时开销。
摘要
- 词法分析是编译器设计中的第一个阶段。
- 词元和标记是根据标记的匹配模式包含在源程序中的字符序列。
- 词法分析器用于扫描程序的整个源代码。
- 词法分析器帮助在符号表中标识标记。
- 无法扫描为任何有效标记的字符序列是词法错误。
- 从剩余输入中移除一个字符是一种有用的错误恢复方法。
- 词法分析器扫描输入程序,而解析器执行语法分析。
- 通过消除不必要的标记,简化了词法分析和语法分析的过程。
- 词法分析器被网络浏览器用于格式化和显示网页,借助从 JavaScript、HTML、CSS 解析的数据。
- 使用词法分析器的最大缺点是,生成词法器表和构建标记需要额外的运行时开销。