如何在 Selenium 中查找损坏的链接
什么是无效链接?
无效链接是无法访问的链接或 URL。它们可能因为服务器错误而失效或无法正常运行。
有效的 URL 状态码始终为 2xx。不同的 HTTP 状态码有不同的用途。对于无效请求,HTTP 状态码为 4xx 和 5xx。
4xx 类状态码主要用于客户端错误,5xx 类状态码主要用于服务器响应错误。
我们很可能无法确认该链接是否有效,除非我们点击并确认。
为什么要检查无效链接?
您应该始终确保网站上没有无效链接,因为用户不应该进入错误页面。
如果规则未正确更新,或者请求的资源在服务器上不存在,就会发生错误。
手动检查链接是一项繁琐的任务,因为每个网页可能包含大量链接,并且所有页面都必须重复手动过程。
使用 Selenium 的自动化脚本可以自动化此过程,这是一个更合适的解决方案。
如何在 Selenium 中检查无效链接和图像
为了检查无效链接,您需要执行以下步骤。
- 根据 <a> 标签收集网页中的所有链接。
- 发送 HTTP 请求获取链接并读取 HTTP 响应代码。
- 根据 HTTP 响应代码判断链接是否有效或无效。
- 对捕获到的所有链接重复此操作。
查找网页上无效链接的代码
以下是测试我们用例的 WebDriver 代码
package automationPractice;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Iterator;
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class BrokenLinks {
private static WebDriver driver = null;
public static void main(String[] args) {
// TODO Auto-generated method stub
String homePage = "http://www.zlti.com";
String url = "";
HttpURLConnection huc = null;
int respCode = 200;
driver = new ChromeDriver();
driver.manage().window().maximize();
driver.get(homePage);
List<WebElement> links = driver.findElements(By.tagName("a"));
Iterator<WebElement> it = links.iterator();
while(it.hasNext()){
url = it.next().getAttribute("href");
System.out.println(url);
if(url == null || url.isEmpty()){
System.out.println("URL is either not configured for anchor tag or it is empty");
continue;
}
if(!url.startsWith(homePage)){
System.out.println("URL belongs to another domain, skipping it.");
continue;
}
try {
huc = (HttpURLConnection)(new URL(url).openConnection());
huc.setRequestMethod("HEAD");
huc.connect();
respCode = huc.getResponseCode();
if(respCode >= 400){
System.out.println(url+" is a broken link");
}
else{
System.out.println(url+" is a valid link");
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
driver.quit();
}
}
解释无效链接代码
步骤 1:导入包
除了默认包之外,还导入以下包
import java.net.HttpURLConnection;
使用此包中的方法,我们可以发送 HTTP 请求并从响应中捕获 HTTP 响应代码。
步骤 2:收集网页中的所有链接
识别网页中的所有链接并将其存储在列表中。
List<WebElement> links = driver.findElements(By.tagName("a"));
获取迭代器以遍历列表。
Iterator<WebElement> it = links.iterator();
步骤 3:识别和验证 URL
在此部分,我们将检查 URL 是否属于第三方域名,或者 URL 是否为空/空。
获取锚点标签的 href 并将其存储在 url 变量中。
url = it.next().getAttribute("href");
检查 URL 是否为空或空白,如果条件满足则跳过剩余步骤。
if(url == null || url.isEmpty()){
System.out.println("URL is either not configured for anchor tag or it is empty");
continue;
}
检查 URL 属于主域名还是第三方。如果属于第三方域名,则跳过剩余步骤。
if(!url.startsWith(homePage)){
System.out.println("URL belongs to another domain, skipping it.");
continue;
}
步骤 4:发送 HTTP 请求
HttpURLConnection 类有发送 HTTP 请求和捕获 HTTP 响应代码的方法。因此,openConnection() 方法 (URLConnection) 的输出被类型转换为 HttpURLConnection。
huc = (HttpURLConnection)(new URL(url).openConnection());
我们可以将请求类型设置为“HEAD”而不是“GET”。这样只返回头部,不返回文档正文。
huc.setRequestMethod("HEAD");
调用 connect() 方法后,将建立与 URL 的实际连接并发送请求。
huc.connect();
步骤 5:验证链接
使用 getResponseCode() 方法,我们可以获取请求的响应代码
respCode = huc.getResponseCode();
根据响应代码,我们将尝试检查链接状态。
if(respCode >= 400){
System.out.println(url+" is a broken link");
}
else{
System.out.println(url+" is a valid link");
}
因此,我们可以从网页中获取所有链接并打印链接是有效还是无效。
希望本教程能帮助您使用 selenium 检查无效链接。
如何获取网页上的所有链接
在 Web 测试 中,一个常见的程序是测试页面中是否存在的所有链接是否有效。这可以通过结合使用 Java for-each 循环、findElements() 和 By.tagName(“a”) 方法方便地完成。
findElements() 方法返回一个带有标签 a 的 Web 元素列表。使用 for-each 循环访问每个元素。
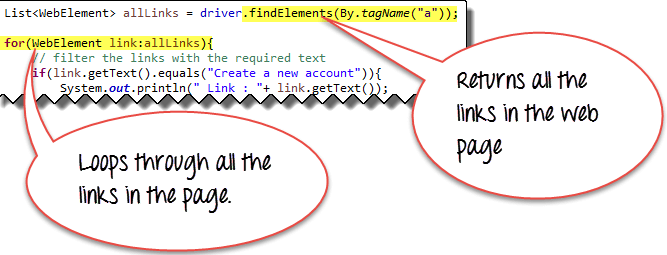
下面的 WebDriver 代码检查 Mercury Tours 主页上的每个链接,以确定哪些链接是有效的,哪些仍在建设中。
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.*;
public class P1 {
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/newtours/";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
String underConsTitle = "Under Construction: Mercury Tours";
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
driver.get(baseUrl);
List<WebElement> linkElements = driver.findElements(By.tagName("a"));
String[] linkTexts = new String[linkElements.size()];
int i = 0;
//extract the link texts of each link element
for (WebElement e : linkElements) {
linkTexts[i] = e.getText();
i++;
}
//test each link
for (String t : linkTexts) {
driver.findElement(By.linkText(t)).click();
if (driver.getTitle().equals(underConsTitle)) {
System.out.println("\"" + t + "\""
+ " is under construction.");
} else {
System.out.println("\"" + t + "\""
+ " is working.");
}
driver.navigate().back();
}
driver.quit();
}
}
输出应与下面所示的类似。
- 访问图像链接使用 By.cssSelector() 和 By.xpath() 方法完成。
.png)
故障排除
在一个孤立的案例中,代码访问的第一个链接可能是“主页”链接。在这种情况下,driver.navigate.back() 操作将显示一个空白页面,因为第一个操作是打开浏览器。驱动程序将无法在空白浏览器中找到所有其他链接。因此 IDE 将抛出异常,其余代码将不会执行。这可以通过使用 If 循环轻松处理。