Teradata 教程:什么是 Teradata SQL?数据库架构
什么是 Teradata?
Teradata 是一款用于开发大型数据仓库应用程序的开源数据库管理系统。该工具利用并行处理的概念,同时支持多种数据仓库操作。Teradata 是一个大规模开放处理系统,支持 Unix/Linux/Windows 服务器平台。
Teradata 软件由美国 IT 公司 Teradata Corporation 开发。它是一家分析数据平台、应用程序和其他相关服务的供应商。该公司开发产品以整合来自各种源的数据,并使数据可供分析。
Teradata 历史
Teradata 曾是 NCR 公司的一个部门。它于 1979 年注册成立,但于 2007 年 10 月脱离 NCR。Michael Koehler 成为 Teradata 的第一任 CEO。
Teradata 公司里程碑
- 1979 年 – Teradata 成立
- 1984 年 – 首个数据库计算机 DBC/1012 发布
- 1986 年 – 《财富》杂志将 Teradata 评为“年度最佳产品”
- 1999 年 – 使用 Teradata 构建的最大数据库,容量为 130 TB
- 2002 年 – Teradata V2R5 版本发布,支持压缩和分区主键
- 2006 年 – Teradata 主数据管理解决方案推出
- 2008 年 – Teradata 13.0 发布,支持主动数据仓库
- 2011 年 – 收购 Teradata Aster,进军高级分析领域
- 2012 年 – 推出 Teradata 14.0
- 2014 年 – 推出 Teradata 15.0
- 2015 年 – Teradata 收购应用程序营销平台 Appoxee
- 2016 年 – Teradata 与大数据携手
- 2017 年 – Teradata 收购圣地亚哥的 StackIQ
为什么选择 Teradata?
- Teradata 提供全套服务,专注于数据仓库。
- 该系统建立在开放架构之上。因此,一旦有更快的设备可用,就可以将其集成到现有架构中。
- Teradata 支持 50 PB 以上的数据。
- 使用服务工作站对大型 Teradata 多节点系统进行单一操作视图
- 与各种商业智能工具兼容,用于提取数据。
- 它可以作为 DBA 管理数据库的单一控制点。
- 高性能、多样化查询、数据库内分析和复杂的 Workload 管理
- Teradata 允许您在多个部署选项上获取相同的数据
在此 Teradata 教程中,接下来我们将学习 Teradata 的功能。
Teradata SQL 的功能
Teradata 提供以下强大功能:
- 线性可伸缩性:通过添加节点来提高系统性能,在处理大量数据时提供线性可伸缩性。
- 无限并行:Teradata 基于 MPP(大规模并行处理架构)。因此,它从一开始就是为并行而设计的。它可以将大型任务分解为小型任务并在并行中运行。
- 成熟的优化器:Teradata 优化器可以处理查询中的多达 64 个 JOIN。
- 低 TCO:Teradata 拥有较低的总拥有成本。易于设置、维护和管理。
- 加载和卸载实用程序:Teradata 提供加载和卸载实用程序,用于将数据移动到 Teradata 系统中/从中。
- 连接性:此 MPP 系统可以连接到通道连接系统(如大型机)或网络连接系统。
- SQL:Teradata 支持SQL与存储在表中的数据进行交互。它提供了自己的扩展。
- 强大的实用程序:Teradata 提供强大的实用程序,用于将数据导入/导出到 Teradata 系统,例如 FastExport、FastLoad、MultiLoad 和 TPT。
- 自动分发:Teradata 可以自动将数据分发到磁盘,无需手动干预。
在此 Teradata SQL 教程中,接下来我们将学习 Teradata 体系结构。
Teradata 体系结构
Teradata 体系结构是一种大规模并行处理体系结构。
Teradata 的三个重要组成部分是:
- 解析引擎
- BYNET
- 访问模块处理器 (AMP)
Teradata 存储架构数据库架构图
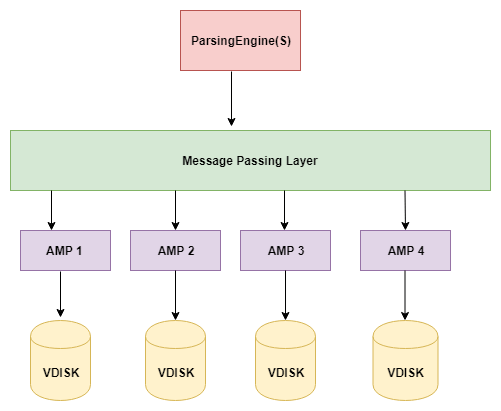
Teradata 存储架构
解析引擎
解析引擎解析查询并准备执行计划。它管理用户的会话。它优化并向用户发送请求。
因此,当客户端执行插入记录的查询时,解析引擎会将记录发送到消息传递层。消息传递层或 BYNET 是一个软硬件组件。它提供网络功能。它还检索记录并将行发送到目标 AMP。
AMP
AMP 代表访问模块处理器。它将记录存储在这些磁盘上。AMP 执行以下活动:
- 管理数据库的一部分
- 管理每个表的一部分
- 执行与生成结果集相关的所有任务,例如排序、聚合和联接。
- 执行锁定和空间管理
Teradata 检索架构
当客户端运行检索记录的查询时,解析引擎会向 BYNET 发送请求。然后 BYNET 将检索请求发送到适当的 AMP。
AMP 并行搜索它们的磁盘,识别所需的记录,并将它们发送到 BYNET。BYNET 将记录发送到解析引擎,解析引擎再将其发送到客户端。
在此 Teradata 数据库教程中,接下来我们将学习 Teradata SQL 命令。
Teradata SQL 命令的类型
Teradata 数据库支持以下基本 SQL 命令:
- 数据定义语言 (DDL) 命令
- 数据控制语言 (DCL) 命令
- 数据操作语言 (DML) 命令
数据定义语言命令
| 命令 | 描述 |
|---|---|
| CREATE | 创建新数据库、表、用户等。 |
| DROP | 删除新数据库、表、用户等。 |
| ALTER | 更改表、列、触发器等。 |
| 修改 | 更改数据库或用户定义 |
| 重命名 | 更改表、视图、宏等的名称。 |
数据控制语言命令
| 命令 | 描述 |
|---|---|
| GRANT/REVOKE | 用于控制用户对对象的权限。 |
| GRANT LOGON/REVOKE LOGON | 用于控制对主机或主机组的登录权限。 |
| GIVE | 用于将数据库对象赋予另一个数据库对象。 |
Teradata 数据库 SQL 数据操作语言命令
| 命令 | 描述 |
|---|---|
| DELETE | 从表中删除行 |
| ECHO | 用于将字符串或命令回显到客户端。 |
| CHECKPOINT | 在日志中定义一个恢复点,以后可用于还原表内容。 |
| SELECT | 用于以表格形式返回特定的行数据。 |
| UPDATE | 修改表中一个或多个行的数据。 |
Teradata 数据库的应用
以下是流行的 Teradata 应用程序:
- 客户数据管理:帮助维护与客户的长期关系。
- 主数据管理:帮助开发可使用、同步和存储主数据vi的环境。
- 财务与绩效管理:帮助组织提高财务报告的速度和质量。它降低了财务基础设施成本,并主动管理企业绩效。
- 供应链管理:改进供应链运营,有助于提高客户服务,缩短周期时间,降低库存。
- 需求链管理:有助于提高客户服务水平和销售额。它还有助于公司准确预测其商品的需求。
在此 Teradata 入门教程中,接下来我们将了解 Teradata 与其他RDBMS的区别。
Teradata 与其他 RDBMS 的区别
| 参数 | TERA DATA | RDBMS |
|---|---|---|
| 体系结构 | 遵循共享无架构。 | 共享一切,并允许资源争用。 |
| 进程 | MIPS [百万指令/秒] | KIPS [千条指令/秒] |
| 索引 | 更好的分发和检索 | 仅提供 FASI 检索 |
| 并行性 | 支持无条件并行。 | 并行性是有条件的且不可预测的。 |
| 批量加载 | Teradata 支持批量加载。 | 仅支持有限的批量加载。 |
| 可扩展性 | 线性可伸缩性,斜率为一 | 可伸缩性呈递减趋势 |
| 数据库缓冲区 | 所有 UoP(并行单元)使用的单个数据库缓冲区。所有 UoP 访问的单个数据存储。 | 查询控制器将函数发送到拥有数据的 UoP。 |
| 存储 | 它存储 TERA BYTES(数十亿行)。 | GIGA BYTES(数百万行)。 |
MPP 与 SMP
| MPP | SMP |
|---|---|
| MPP – 大规模并行处理。它是一种计算机系统,连接到许多独立的算术单元或完整的微处理器,它们并行运行。 | 对称多处理。在 SMP 处理系统中,CPU 共享相同的内存,因此在一个系统中运行的代码可能会影响另一个系统使用的内存。 |
| 数据库可以通过添加新的 CPU 来扩展。 | SMP 数据库通常使用一个 CPU 来执行数据库搜索。 |
| 在 MPP 环境中,性能得到提升,因为无需在物理计算机之间共享资源。 | 并行作业的工作负载分布在系统中的各个处理器上。 |
| 大规模并行处理系统的性能是线性的。但是,它会随着节点数量的增加而增加。 | SMP 数据库可以在多台服务器上运行。但是,它们将共享另一个资源。 |
摘要
- Teradata 含义:Teradata 是一款开源数据库管理系统,用于开发大型数据仓库应用程序。
- Teradata 曾是 NCR 公司的一个部门。它于 1979 年成立,但于 2007 年 10 月脱离 NCR。
- Teradata 提供全套服务,专注于数据仓库。
- Teradata 在处理大量数据时提供线性可伸缩性,通过添加节点来提高系统性能。
- Teradata 的三个重要组成部分是:1) 解析引擎 2) MPP 3) 访问模块处理器 (AMP)
- Teradata 提供完整的产品系列,以满足任何组织的数仓和 ETL 需求。
- Teradata 应用程序主要用于供应链管理、主数据管理、需求链管理等。