如何在Selenium中处理Web表格
什么是Selenium中的Web表格?
Selenium 中的 **Web 表格**是一种 WebElement,用于以表格形式表示数据或信息。显示的数据或信息可以是静态的,也可以是动态的。Web 表格及其元素可以使用 Selenium 中的 WebElement 函数和定位器进行访问。Web 表格的一个典型示例是在电子商务平台上显示的产品规格。
读取 HTML Web 表格
有时我们需要访问 HTML 表格中的元素(通常是文本)。然而,Web 设计师很少为表格中的某个单元格提供 id 或 name 属性。因此,我们不能使用“By.id()”、“By.name()”或“By.cssSelector()”等常用方法。在这种情况下,最可靠的选择是使用“By.xpath()”方法访问它们。
如何在Selenium中处理Web表格
请考虑以下用于在 Selenium 中处理 Web 表格的 HTML 代码。
.png)
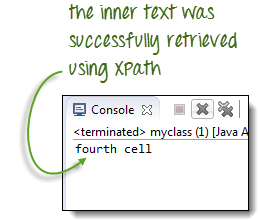
我们将使用XPath来获取包含文本“第四个单元格”的单元格的内部文本。
.png)
步骤 1 – 设置父元素 (table)
WebDriver 中的 XPath 定位器始终以双斜杠“//”开头,然后是父元素。由于我们处理的是 Selenium 中的 Web 表格,因此父元素应始终是 <table> 标签。因此,我们 Selenium XPath 表格定位器的第一部分应以“//table”开头。
![]()
步骤 2 – 添加子元素
紧邻 <table> 下方的元素是 <tbody>,因此我们可以说 <tbody> 是 <table> 的“子元素”。同样,<table> 是 <tbody> 的“父元素”。XPath 中的所有子元素都放在其父元素的右侧,用一个正斜杠“/”分隔,如下图所示。
.png)

步骤 3 – 添加谓词
<tbody> 元素包含两个 <tr> 标签。现在我们可以说这两个 <tr> 标签是 <tbody> 的“子元素”。因此,我们可以说 <tbody> 是这两个 <tr> 元素的父元素。
我们还可以得出另一个结论,即这两个 <tr> 元素是同级元素。**同级元素是指具有相同父元素的子元素**。
要访问我们希望访问的 <td>(带有文本“第四个单元格”),我们必须首先访问**第二个** <tr> 而不是第一个。如果我们简单地写“//table/tbody/tr”,那么我们将访问第一个 <tr> 标签。
那么,我们如何访问第二个 <tr> 呢?答案是使用**谓词**。
**谓词是括在方括号“[ ]”中的数字或 HTML 属性,用于区分子元素与其同级元素**。由于我们需要访问的 <tr> 是第二个,我们将使用“[2]”作为谓词。

如果我们不使用任何谓词,XPath 将访问第一个同级元素。因此,我们可以使用以下任一 XPath 代码访问第一个 <tr>。

步骤 4 – 使用适当的谓词添加后续子元素
我们需要访问的下一个元素是第二个 <td>。应用我们从步骤 2 和 3 中学到的原理,我们将最终确定我们的 XPath 代码,使其如下所示。
![]()
现在我们有了正确的 XPath 定位器,我们可以访问我们想要的单元格并使用以下代码获取其内部文本。它假设您已将上面的 HTML 代码保存为 C 盘中的“newhtml.html”。
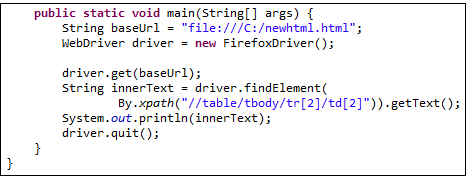
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/write-xpath-table.html";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(
By.xpath("//table/tbody/tr[2]/td[2]")).getText();
System.out.println(innerText);
driver.quit();
}
}
访问嵌套表格
上面讨论的相同原理也适用于嵌套表格。**嵌套表格是位于另一个表格内的表格**。示例如下所示。

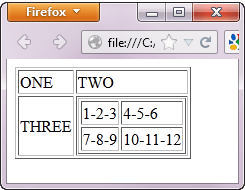
要使用上一节中的“//父/子”和谓词概念访问带有文本“4-5-6”的单元格,我们应该能够得到以下 XPath 代码。

以下 WebDriver 代码应该能够检索我们正在访问的单元格的内部文本。
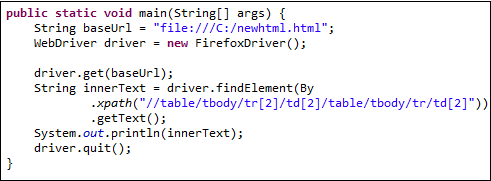
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/accessing-nested-table.html";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(
By.xpath("//table/tbody/tr[2]/td[2]/table/tbody/tr/td[2]")).getText();
System.out.println(innerText);
driver.quit();
}
下面的输出证实内部表格已成功访问。

使用属性作为谓词
如果元素在 HTML 代码中写得很深,以至于要用于谓词的数字很难确定,我们可以使用该元素唯一的属性来代替。
在下面的示例中,“New York to Chicago”单元格位于 Mercury Tours 主页的 HTML 代码深处。
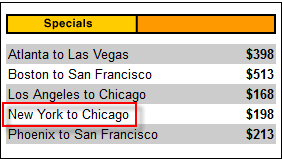

在这种情况下,我们可以使用表格的唯一属性(width=”270″)作为谓词。**属性通过在其前面加上 @ 符号来用作谓词**。在上面的示例中,“New York to Chicago”单元格位于第四个 <tr> 的第一个 <td> 中,因此我们的 XPath 应该如下所示。
![]()
请记住,当我们在 Java 中放置 XPath 代码时,我们应该为“270”两侧的双引号使用转义字符反斜杠“\”,这样 By.xpath() 的字符串参数就不会过早终止。

我们现在可以使用以下代码访问该单元格。
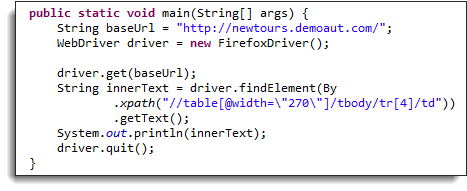
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/newtours/";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(By
.xpath("//table[@width=\"270\"]/tbody/tr[4]/td"))
.getText();
System.out.println(innerText);
driver.quit();
}
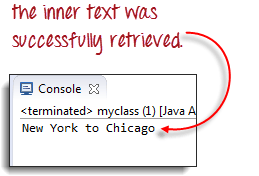
快捷方式:使用“检查元素”访问 Selenium 中的表格
如果元素的数字或属性极难或无法获取,生成 XPath 代码最快的方法是使用“检查元素”。
请考虑以下来自 Mercury Tours 主页的示例。

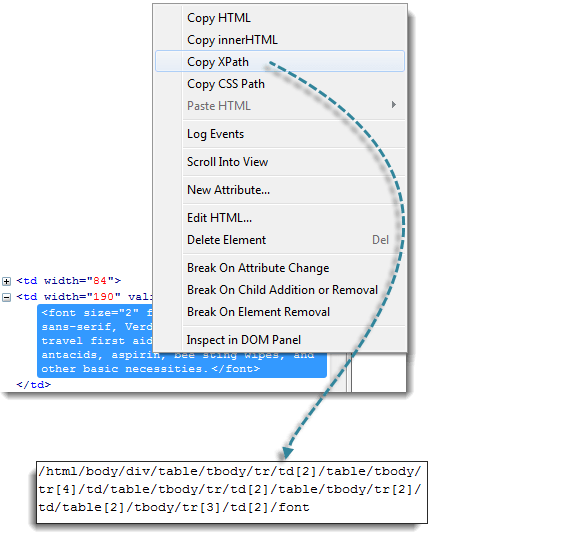
步骤 1
使用 Firebug 获取 XPath 代码。
步骤 2
查找第一个“table”父元素并删除其左侧的所有内容。
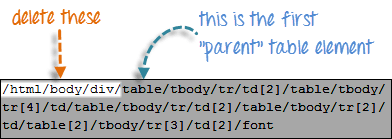
步骤 3
在代码的剩余部分前加上双斜杠“//”,然后将其复制到您的 WebDriver 代码中。
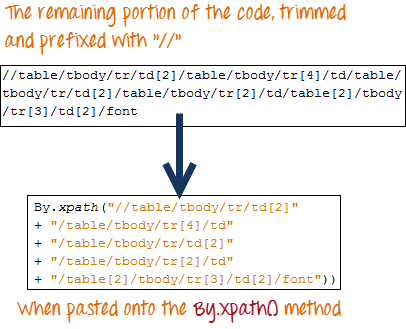
以下 WebDriver 代码将能够成功检索我们正在访问的元素的内部文本。
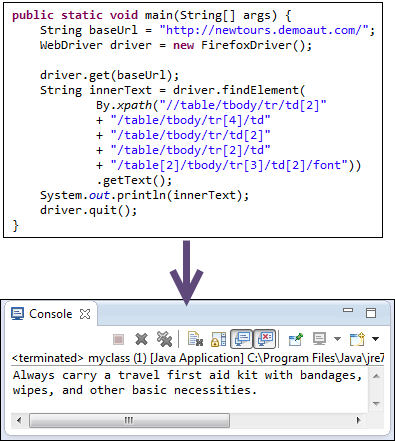
public static void main(String[] args) {
String baseUrl = "https://demo.guru99.com/test/newtours/";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(By
.xpath("//table/tbody/tr/td[2]"
+ "//table/tbody/tr[4]/td/"
+ "table/tbody/tr/td[2]/"
+ "table/tbody/tr[2]/td[1]/"
+ "table[2]/tbody/tr[3]/td[2]/font"))
.getText();
System.out.println(innerText);
driver.quit();
}
摘要
- By.xpath() 通常用于访问 Selenium 中 WebTable 的元素。
- 如果元素在 HTML 代码中写得很深,以至于要用于谓词的数字很难确定,我们可以使用该元素唯一的属性来代替 Selenium 获取表格元素。
- 属性通过在其前面加上 @ 符号来用作谓词。
- 使用“检查元素”访问 Selenium 中的 WebTable