Selenium 核心扩展 (User-Extensions.js)
为了理解扩展,我们首先来理解 Selenium IDE 的三大支柱
- 操作:您正在 UI 屏幕上执行什么操作
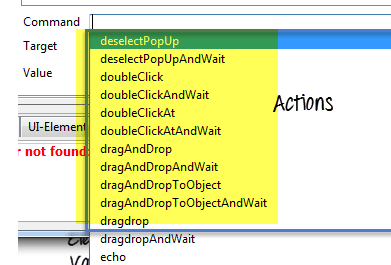
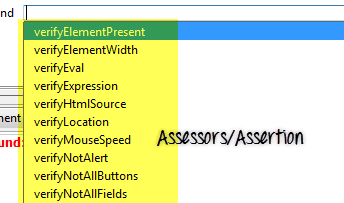
- 评估器/断言:您对从 UI 获取的数据进行什么验证
- 定位策略:我们如何在 UI 中找到元素。
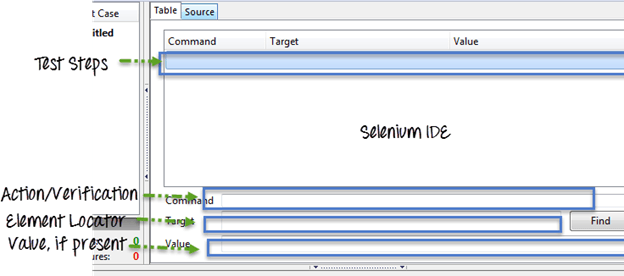
现在,Selenium IDE 拥有一个非常成熟的库,其中包含大量操作、断言/评估器和定位策略。
但有时我们需要为项目需求添加更多功能。在这种情况下,我们可以通过添加自定义扩展来扩展此库。这些自定义扩展称为“用户扩展”。
例如,我们需要一个操作,它可以在将文本填充到网页元素之前将其转换为大写。您在默认操作库中找不到此操作。在这种情况下,您可以创建自己的“用户扩展”。在本教程中,我们将学习如何创建用户扩展以将文本转换为大写
创建 Selenium 用户扩展的要求
要为 Selenium IDE 创建用户扩展,我们需要了解 JavaScript 的基本概念和 Java 脚本原型对象概念。

要创建您的用户扩展,您需要创建 JavaScript 方法并将它们添加到 Selenium 对象原型和 PageBot 对象原型。
Selenium IDE 如何识别用户扩展?
将用户扩展添加到 Selenium IDE 后,当我们启动 Selenium IDE 时,JavaScript 原型中的所有这些扩展都会加载,并且 Selenium IDE 会根据它们的名称识别它们。
如何创建用户扩展
步骤 1) 操作 – 所有操作都以“do”开头,即如果操作用于大写文本,则其名称将为 doTextUpperCase。当我们向 Selenium IDE 添加此操作方法时,Selenium IDE 会自行为此操作创建一个等待方法。因此,在这种情况下,当我们创建 doTextUpperCase 操作时,Selenium IDE 将创建一个相应的等待函数,即 TextUpperCaseAndWait。它可以接受两个参数
示例:大写文本操作
Selenium.prototype.doTextUpperCase = function(locator, text) {
// Here findElement is itself capable to handle all type of locator(xpath,css,name,id,className), We just need to pass the locator text
var element = this.page().findElement(locator);
// Create the text to type
text = text.toUpperCase();
// Replace the element text with the new text
this.page().replaceText(element, text);
};
步骤 2) 评估器/断言 - 所有在 Selenium 对象原型中注册的评估器都将带有前缀
“get”或“is”,例如 getValueFromCompoundTable,isValueFromCompoundTable。它可以接受两个参数,一个用于目标,另一个用于测试用例中的值字段。

对于每个评估器,将有相应的验证函数,前缀为“verify”、“assert”,以及前缀为“waitFor”的等待函数
示例:用于大写文本评估器
Selenium.prototype.assertTextUpperCase = function(locator, text) {
// All locator-strategies are automatically handled by "findElement"
var element = this.page().findElement(locator);
// Create the text to verify
text = text.toUpperCase();
// Get the actual element value
var actualValue = element.value;
// Make sure the actual value matches the expected
Assert.matches(expectedValue, actualValue);
};
Selenium.prototype.isTextEqual = function(locator, text) {
return this.getText(locator).value===text;
};
Selenium.prototype.getTextValue = function(locator, text) {
return this.getText(locator).value;
};
步骤 3) 定位策略 - 如果我们希望创建自己的函数来定位元素,那么
我们需要使用前缀为“locateElementBy”的函数来扩展 PageBot 原型。
它将接受两个参数,第一个是定位器字符串,第二个是文档
需要搜索的位置。
示例:用于大写文本定位器
// The "inDocument" is a document you are searching.
PageBot.prototype.locateElementByUpperCase = function(text, inDocument) {
// Create the text to search for
var expectedValue = text.toUpperCase();
// Loop through all elements, looking for ones that have
// a value === our expected value
var allElements = inDocument.getElementsByTagName("*");
// This star '*' is a kind of regular expression it will go through every element (in HTML DOM every element surely have a tag name like<body>,<a>,<h1>,<table>,<tr>,<td> etc. ). Here our motive is to find an element which matched with the Upper Case text we have passed so we will search it with all elements and when we get match we will have the correct web element.
for (var i = 0; i < allElements.length; i++) {
var testElement = allElements[i];
if (testElement.innerHTML && testElement.innerHTML === expectedValue) {
return testElement;
}
}
return null;
};
如何使用新创建的核心扩展?
- 转到 Selenium IDE
单击选项 -> 选项...
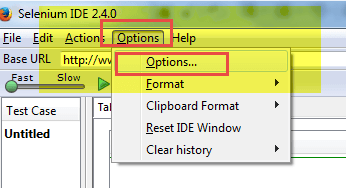
- 在“常规”部分选择新创建的 Selenium 核心扩展的位置

- 单击确定并重新启动 Selenium IDE
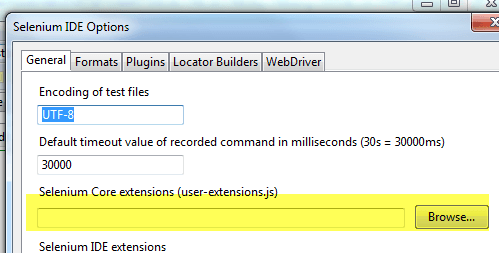

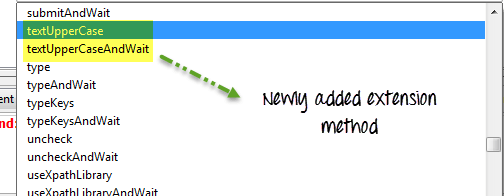
- 您将在命令列表中找到该扩展
以下是 Selenium IDE 中使用的流行扩展/插件列表
| 名称 | 目的 |
|---|---|
| 收藏夹 | 将测试套件标记为收藏夹并一键执行 |
| Flex Pilot X | 用于基于 Flex 的自动化 |
| FlexMonkium | 用于 Selenium IDE 中基于 Adobe Flex 的录制和回放测试 |
| 文件日志记录 | 用于将日志保存到文件 |
| 流控制 | 控制测试执行流程 |
| 突出显示元素 | 突出显示网页控件 |
| 隐式等待 | 等待元素达到一定时间限制 |
| 失败时截图 | 失败时截图 |
| 测试结果 | 一键保存测试套件的测试用例结果 |
您可以从 SeleniumHQ 官方网站的下载部分获取所有这些以及更多内容
http://docs.seleniumhq.org/download/
摘要
- Selenium IDE 分为三部分:操作、评估器/断言、定位策略。
- 当 Selenium IDE 无法满足当前需求时,会创建用户扩展。
- 要创建用户扩展,需要将 JavaScript 添加到 Selenium 的对象原型中。
- 创建扩展后,需要将其添加到 Selenium IDE 并重新启动 IDE。