强化学习:是什么,算法,类型与示例
什么是强化学习?
强化学习被定义为一种机器学习方法,它关注软件代理如何在环境中采取行动。强化学习是深度学习方法的一部分,可以帮助您最大化累积奖励的某个部分。
这种神经网络学习方法可以帮助您学习如何在许多步骤中实现复杂的目标或最大化特定的维度。
深度强化学习方法的重要组成部分
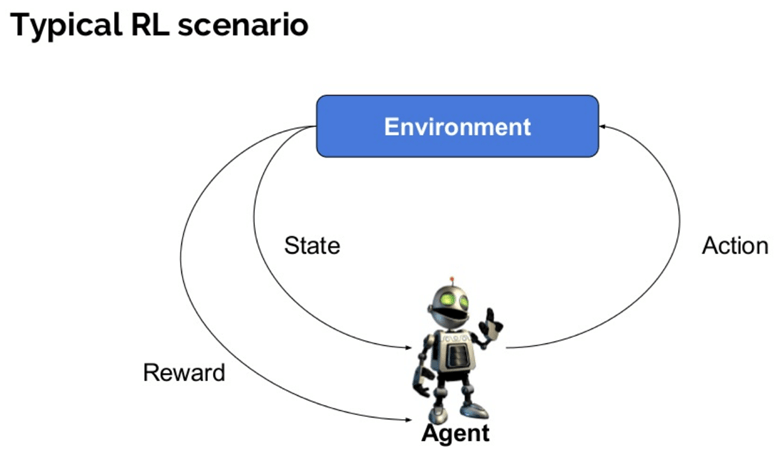
以下是强化学习中使用的一些重要术语
- 代理(Agent):一个假定的实体,它在环境中执行动作以获得奖励。
- 环境(Environment):代理需要面对的场景。
- 奖励(Reward):当代理执行特定动作或任务时,给予代理的即时回报。
- 状态(State):状态是指由环境返回的当前情况。
- 策略(Policy):代理根据当前状态决定下一个动作的策略。
- 价值(Value):与短期奖励相比,预期的长期折扣回报。
- 价值函数(Value Function):它指定了状态的价值,即总奖励。代理应该预期从该状态开始。
- 环境模型(Model of the environment):模仿环境的行为。它有助于您做出推断,并确定环境将如何表现。
- 基于模型的方法(Model based methods):一种使用基于模型的方法来解决强化学习问题的方法。
- Q 值或动作值(Q value or action value):Q 值与价值非常相似。两者之间的唯一区别在于它需要一个额外的参数,即当前动作。
强化学习如何工作?
让我们看一些简单的例子来说明强化学习机制。
考虑教你的猫新的把戏
- 由于猫不理解英语或其他人类语言,我们无法直接告诉它该怎么做。相反,我们采用不同的策略。
- 我们模拟一种情况,猫会尝试用不同的方式做出反应。如果猫的反应是我们想要的,我们会给它鱼。
- 现在,当猫再次遇到相同的情况时,它会更积极地执行类似的动作,以期望获得更多奖励(食物)。
- 这就是猫从“做什么”中通过积极体验中获得的学习。
- 同时,猫也学会了在面对负面经历时该做什么,不该做什么。
强化学习示例
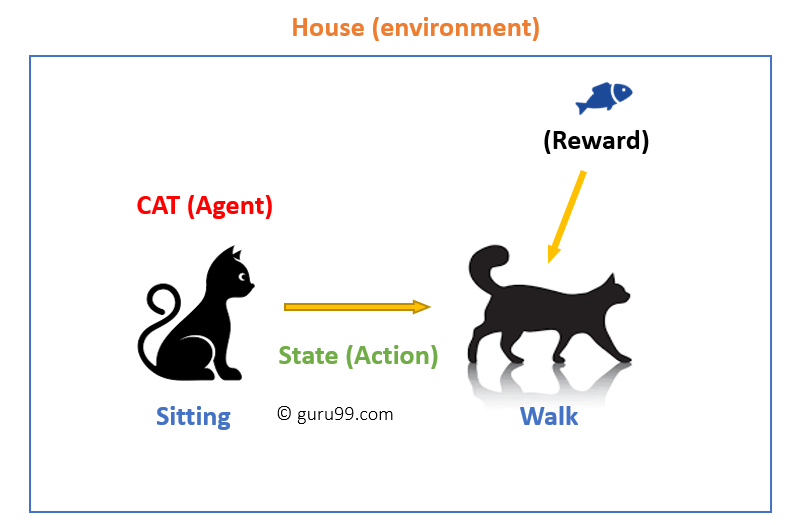
在这种情况下,
- 你的猫是一个暴露于环境的代理。在这种情况下,环境是你的房子。状态的一个例子可能是你的猫坐着,然后你使用一个特定的词让猫走动。
- 我们的代理通过执行动作从一个“状态”转换到另一个“状态”来做出反应。
- 例如,你的猫从坐着变成行走。
- 代理的反应是一个动作,策略是根据状态选择动作以期望更好结果的方法。
- 在转换之后,它们可能会得到奖励或惩罚。
强化学习算法
有三种方法可以实现强化学习算法。
基于价值(Value-Based)
在基于价值的强化学习方法中,您应该尝试最大化价值函数 V(s)。在此方法中,代理期望在策略 π 下,当前状态的长期回报。
基于策略(Policy-based)
在基于策略的强化学习方法中,您尝试提出一个策略,使得在每个状态下执行的动作都能帮助您在未来获得最大奖励。
基于策略的方法有两种:
- 确定性:对于任何状态,策略 π 都会产生相同的动作。
- 随机性:每个动作都有一定的概率,由以下方程确定。随机策略
n{a\s) = P\A, = a\S, =S]
基于模型(Model-Based)
在此强化学习方法中,您需要为每个环境创建一个虚拟模型。代理学习在该特定环境中执行。
强化学习的特点
以下是强化学习的重要特点
- 没有监督者,只有实数或奖励信号
- 顺序决策制定
- 时间在强化问题中起着至关重要的作用
- 反馈总是延迟的,而不是即时的
- 代理的动作决定了它接收到的后续数据
强化学习的类型
有两种强化学习方法:
积极(Positive)
它被定义为由于特定行为而发生的事件。它会增加行为的强度和频率,并对代理的动作产生积极影响。
这种强化有助于您最大化绩效并维持更长时间的改变。但是,过度的强化可能导致状态的过度优化,从而影响结果。
消极(Negative)
消极强化被定义为由于应停止或避免的负面条件而发生的行为加强。它有助于您定义最低绩效标准。然而,此方法的缺点是它只提供了足够达到最低行为的标准。
强化学习模型
强化学习中有两个重要的学习模型
- 马尔可夫决策过程(Markov Decision Process)
- Q 学习(Q learning)
马尔可夫决策过程(Markov Decision Process)
以下参数用于获取解决方案
- 动作集- A
- 状态集 -S
- 奖励- R
- 策略- π
- 价值- V
强化学习中用于映射解决方案的数学方法被认为是马尔可夫决策过程或 (MDP)。
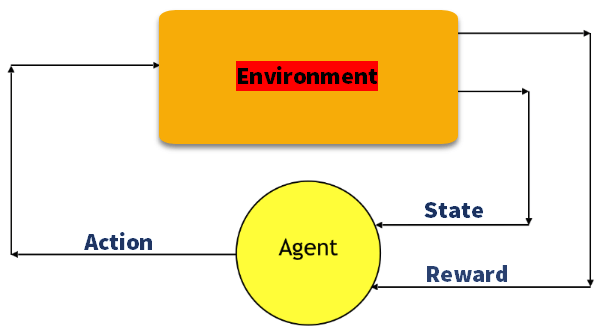
Q-Learning
Q 学习是一种基于价值的方法,用于提供信息以告知代理应该采取哪个动作。
让我们通过以下示例来理解这种方法
- 一栋建筑有五个房间,由门连接。
- 每个房间编号从 0 到 4
- 建筑外部是一个大的外部区域(5)
- 门 1 和 4 从房间 5 通向建筑物
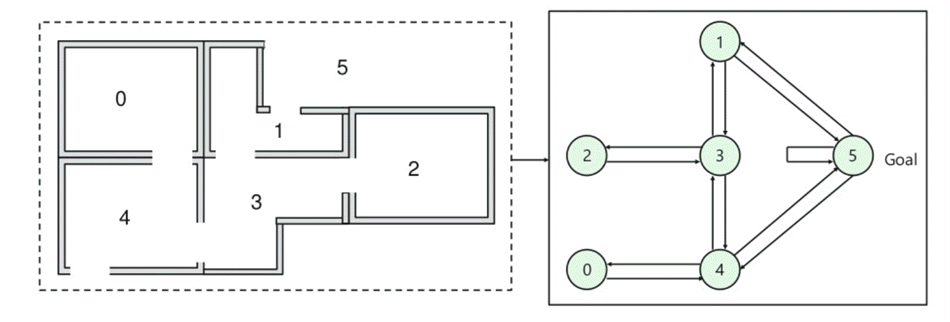
接下来,您需要为每个门关联一个奖励值
- 直接通往目标的门奖励为 100
- 未直接连接到目标房间的门奖励为零
- 由于门是双向的,每个房间都有两个箭头
- 上图中的每个箭头都有一个即时奖励值
解释
在此图像中,您可以看到房间代表一个状态
代理从一个房间移动到另一个房间代表一个动作
在下面给出的图像中,状态被描述为一个节点,而箭头显示了动作。
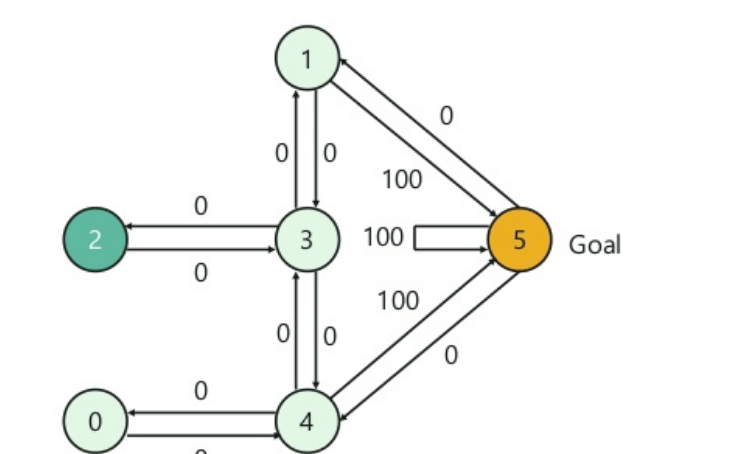
例如,代理从房间 2 遍历到 5
- 初始状态 = 状态 2
- 状态 2-> 状态 3
- 状态 3 -> 状态 (2,1,4)
- 状态 4-> 状态 (0,5,3)
- 状态 1-> 状态 (5,3)
- 状态 0-> 状态 4
强化学习与监督学习
| 参数 | 强化学习 | 监督学习 |
|---|---|---|
| 决策风格 | 强化学习帮助您顺序做出决策。 | 在此方法中,根据开始时给定的输入做出决策。 |
| 工作原理 | 与环境交互。 | 基于示例或给定的样本数据。 |
| 决策依赖性 | 在 RL 方法中,学习决策是相关的。因此,您应该为所有相关的决策打上标签。 | 监督学习中,决策是相互独立的,因此为每个决策都提供了标签。 |
| 最适合 | 在人工智能领域提供支持并更好地工作,在这些领域人类互动普遍存在。 | 它主要与交互式软件系统或应用程序配合使用。 |
| 示例 | 国际象棋游戏 | 物体识别 |
强化学习的应用
以下是强化学习的应用
- 用于工业自动化的机器人技术。
- 商业战略规划
- 机器学习和数据处理
- 它有助于创建培训系统,根据学生的要求提供定制化的指导和材料。
- 飞机控制和机器人运动控制
为什么使用强化学习?
以下是使用强化学习的主要原因
- 它帮助您找出哪种情况需要采取行动
- 帮助您发现哪个动作在更长的时间内会产生最高的奖励。
- 强化学习还为学习代理提供了一个奖励函数。
- 它还允许它找出获得丰厚奖励的最佳方法。
何时不使用强化学习?
您不能将强化学习模型应用于所有情况。以下是一些您不应使用强化学习模型的情况。
- 当您有足够的数据来使用监督学习方法解决问题时
- 您需要记住,强化学习是计算密集型且耗时的。特别是当动作空间很大时。
强化学习的挑战
以下是您在进行强化学习时将面临的主要挑战
- 特征/奖励设计应该非常涉及
- 参数可能会影响学习速度。
- 现实环境可能具有部分可观察性。
- 过度的强化可能导致状态过载,从而降低结果。
- 现实环境可能不是静止的。
摘要
- 强化学习是一种机器学习方法
- 帮助您发现哪个动作在更长的时间内会产生最高的奖励。
- 强化学习的三种方法是:1)基于价值 2)基于策略和基于模型的学习。
- 代理、状态、奖励、环境、价值函数、环境模型、基于模型的方法等是 RL 学习方法中使用的一些重要术语
- 强化学习的例子是您的猫是暴露于环境的代理。
- 此方法最大的特点是没有监督者,只有实数或奖励信号
- 强化学习有两种类型:1)积极 2)消极
- 两种广泛使用的学习模型是:1)马尔可夫决策过程 2)Q 学习
- 强化学习方法通过与环境交互来工作,而监督学习方法则基于给定的样本数据或示例。
- 强化学习方法的应用包括:机器人技术用于工业自动化和商业战略规划
- 当您有足够的数据来解决问题时,不应使用此方法
- 此方法最大的挑战是参数可能会影响学习速度