MongoDB 正则表达式 (Regex) 示例
正则表达式用于模式匹配,基本上是用于在文档中查找字符串。
有时,在检索集合中的文档时,您可能不知道确切的字段值来搜索。因此,可以使用正则表达式来根据模式匹配搜索值来帮助检索数据。
使用 $regex 运算符进行模式匹配
MongoDB 中的 regex 运算符用于在集合中搜索特定字符串。以下示例显示了如何执行此操作。
假设我们有相同的 Employee 集合,其中包含“Employeeid”和“EmployeeName”字段名。我们还假设我们的集合中有以下文档。
| 员工 ID | 员工姓名 |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
在下面的代码中,我们使用了 regex 运算符来指定搜索条件。
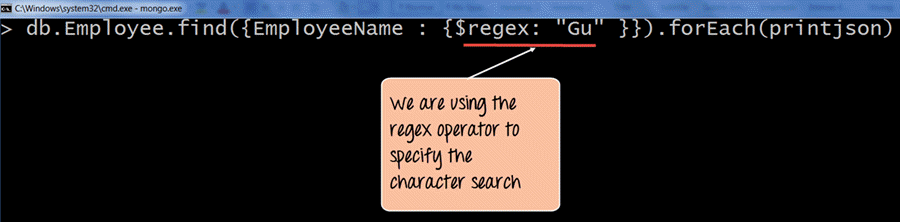
db.Employee.find({EmployeeName : {$regex: "Gu" }}).forEach(printjson)
代码解释
- 在这里,我们想查找所有包含“Gu”字符的员工姓名。因此,我们指定 $regex 运算符来定义“Gu”的搜索条件。
- printjson 用于以更好的方式打印查询返回的每个文档。
如果命令执行成功,将显示以下输出
输出
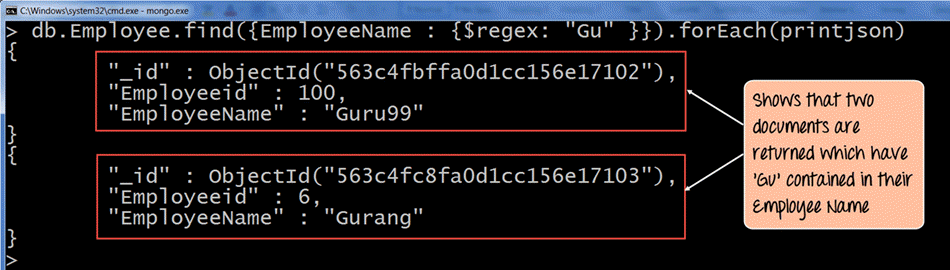
输出清楚地显示了返回了员工姓名包含“Gu”字符的文档。
假设您的集合包含以下文档,此外还有一个文档的员工姓名是“Guru999”。如果您输入的搜索条件是“Guru99”,它也会返回包含“Guru999”的文档。但如果我们不希望这样,只希望返回“Guru99”的文档。那么我们可以通过精确的模式匹配来实现。要进行精确的模式匹配,我们将使用 ^ 和 $ 字符。我们将在字符串的开头添加 ^ 字符,在末尾添加 $ 字符。
| 员工 ID | 员工姓名 |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
| 8 | Guru999 |
以下示例显示了如何做到这一点。

db.Employee.find({EmployeeName : {$regex: "^Guru99$"}}).forEach(printjson)
代码解释
- 在这里的搜索条件中,我们使用了 ^ 和 $ 字符。^ 用于确保字符串以某个字符开头,而 $ 用于确保字符串以某个字符结尾。因此,当代码执行时,它只会提取名称为“Guru99”的字符串。
- printjson 用于以更好的方式打印查询返回的每个文档。
如果命令执行成功,将显示以下输出
输出
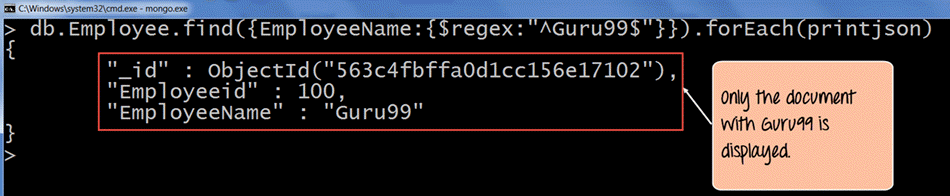
在输出中,可以清楚地看到提取了字符串“Guru99”。
带 $options 的模式匹配
当使用 regex 运算符时,还可以通过使用 **$options** 关键字提供其他选项。例如,假设您想查找员工姓名中包含“Gu”的所有文档,而不管它是区分大小写还是不区分大小写。如果需要这样的结果,那么我们需要使用带有不区分大小写参数的 **$options**。
以下示例显示了如何做到这一点。
假设我们有相同的 Employee 集合,其中包含“Employeeid”和“EmployeeName”字段名。
我们还假设我们的集合中有以下文档。
| 员工 ID | 员工姓名 |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
| 7 | GURU99 |
现在,如果我们运行与上一个主题相同的查询,我们将在结果中看不到“GURU99”的文档。为了确保它出现在结果集中,我们需要添加 $options “I” 参数。

db.Employee.find({EmployeeName:{$regex: "Gu",$options:'i'}}).forEach(printjson)
代码解释
- 带有“I”参数(表示不区分大小写)的 $options 指定我们要进行搜索,无论找到的是大写还是小写的“Gu”字母。
如果命令执行成功,将显示以下输出
输出
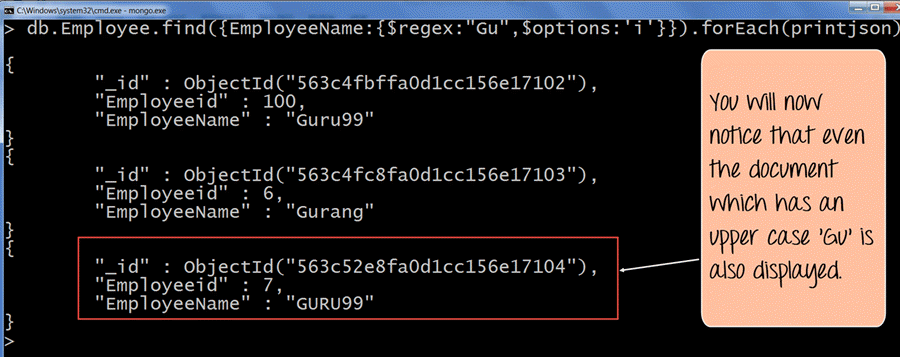
- 输出清楚地表明,即使一个文档中的“Gu”是大写的,该文档仍然会显示在结果集中。
不带 regex 运算符的模式匹配
也可以在不使用 regex 运算符的情况下进行模式匹配。以下示例显示了如何执行此操作。

db.Employee.find({EmployeeName: /Gu/'}).forEach(printjson)
代码解释
- “//”选项基本上是用于在这些分隔符内指定搜索条件的。因此,我们指定 /Gu/ 来再次查找员工姓名中包含“Gu”的文档。
如果命令执行成功,将显示以下输出
输出
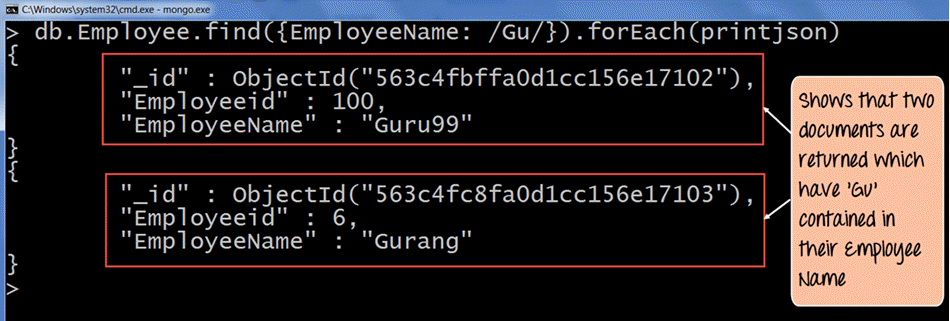
输出清楚地显示了返回了员工姓名包含“Gu”字符的文档。
从集合中获取最后 'n' 个文档
有多种方法可以获取集合中的最后 n 个文档。
让我们通过以下步骤来看一种方法
以下示例显示了如何做到这一点。
假设我们有相同的 Employee 集合,其中包含“Employeeid”和“EmployeeName”字段名。
我们还假设我们的集合中有以下文档
| 员工 ID | 员工姓名 |
|---|---|
| 22 | NewMartin |
| 2 | Mohan |
| 3 | Joe |
| 4 | MohanR |
| 100 | Guru99 |
| 6 | Gurang |
| 7 | GURU99 |
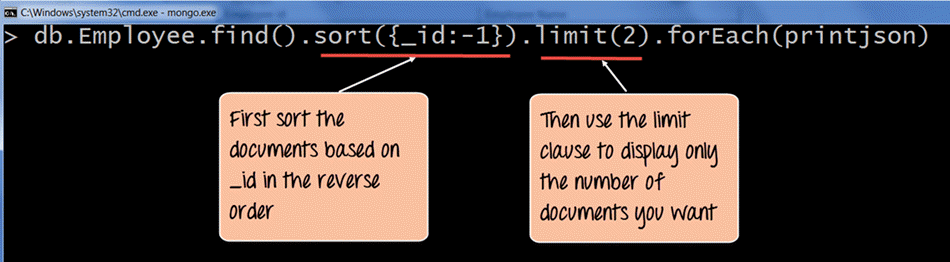
db.Employee.find().sort({_id:-1}).limit(2).forEach(printjson)
代码解释
1) 查询文档时,使用 sort 函数按集合中 _id 字段值的降序对记录进行排序。-1 表示按降序或递减顺序对文档进行排序,以便最后一个文档成为第一个显示的文档。
2) 然后使用 limit 子句来显示您想要的记录数。这里我们将 limit 子句设置为 (2),因此它将获取最后两个文档。
如果命令执行成功,将显示以下输出
输出
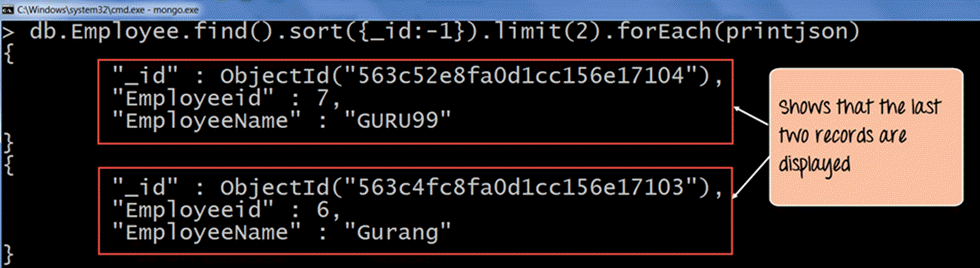
输出清楚地显示了集合中的最后两个文档。因此,我们清楚地表明,要获取集合中最后 'n' 个文档,我们可以先按降序对文档进行排序,然后使用 limit 子句返回所需的 'n' 个文档。
注意:如果搜索的字符串长度大于 38,000 个字符,它将无法显示正确的结果。
摘要
- 可以通过 $regex 运算符实现模式匹配。此运算符可用于在集合中查找特定字符串。
- ^ 和 $ 符号可用于精确文本搜索,^ 用于确保字符串以特定字符开头,而 $ 用于确保字符串以特定字符结尾。
- 可以将 'i' 与 $regex 运算符一起使用,以指定不区分大小写,以便无论字符串是大写还是小写都可以进行搜索。
- 可以使用 // 分隔符进行模式匹配。
- 结合使用 sort 和 limit 函数来返回集合中的最后 n 个文档。sort 函数可用于以降序返回文档,然后可以使用 limit 子句限制返回的文档数量。