Python 多线程及示例:了解 Python GIL
什么是线程?
线程是并发编程中的一个执行单元。多线程是一种允许 CPU 同时执行一个进程的多个任务的技术。这些线程可以独立执行,同时共享它们的进程资源。
什么是进程?
进程基本上是正在执行的程序。当您在计算机上启动一个应用程序(如浏览器或文本编辑器)时,操作系统会创建一个进程。
Python 中的多线程是什么?
Python 编程中的多线程是一种众所周知的技术,其中一个进程中的多个线程共享与主线程的数据空间,这使得线程间的信息共享和通信变得容易且高效。线程比进程更轻量。多线程可以独立执行,同时共享它们的进程资源。多线程的目的是同时运行多个任务和函数。
什么是多进程?
多进程允许您同时运行多个不相关的进程。这些进程不共享它们的资源,而是通过 IPC 进行通信。
Python 多线程与多进程
要理解进程和线程,请考虑以下场景:您计算机上的 .exe 文件是一个程序。当您打开它时,操作系统会将其加载到内存中,CPU 会执行它。现在正在运行的程序实例称为进程。
每个进程将具有 2 个基本组件
- 代码
- 数据
现在,一个进程可能包含一个或多个称为线程的子部分。这取决于操作系统架构。您可以将线程视为进程的一个部分,它可以被操作系统单独执行。
换句话说,它是由操作系统独立运行的指令流。单个进程内的线程共享该进程的数据,并旨在协同工作以促进并行性。
为什么要使用多线程?
多线程允许您将应用程序分解为多个子任务,并同时运行这些任务。如果您正确使用多线程,您的应用程序速度、性能和渲染都可以得到改进。
Python 多线程
Python 支持多进程和多线程的结构。在本教程中,您将主要关注使用 Python 实现多线程应用程序。有两个主要模块可用于处理 Python 中的线程:
- thread 模块,以及
- threading 模块
然而,在 Python 中,还有全局解释器锁(GIL)。它不允许带来多少性能提升,甚至可能降低某些多线程应用程序的性能。您将在本教程的后续部分了解所有关于它的信息。
线程和 threading 模块
您将在本教程中学习的两个模块是thread 模块和threading 模块。
但是,thread 模块早已被弃用。从 Python 3 开始,它已被指定为过时,并且仅作为__thread 提供,以提供向后兼容性。
对于您打算部署的应用程序,您应该使用更高级别的threading 模块。thread 模块仅在此处涵盖,以作教育目的。
Thread 模块
使用此模块创建新线程的语法如下:
thread.start_new_thread(function_name, arguments)
好了,现在您已经掌握了开始编码的基本理论。因此,请打开您的 IDLE 或记事本并输入以下内容:
import time
import _thread
def thread_test(name, wait):
i = 0
while i <= 3:
time.sleep(wait)
print("Running %s\n" %name)
i = i + 1
print("%s has finished execution" %name)
if __name__ == "__main__":
_thread.start_new_thread(thread_test, ("First Thread", 1))
_thread.start_new_thread(thread_test, ("Second Thread", 2))
_thread.start_new_thread(thread_test, ("Third Thread", 3))
保存文件,然后按 F5 运行程序。如果一切正常,您应该会看到以下输出:
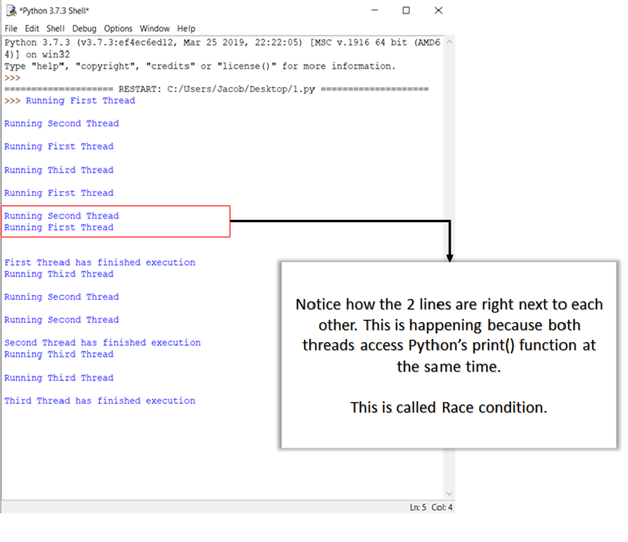
您将在接下来的部分中了解更多关于竞态条件以及如何处理它们的信息。
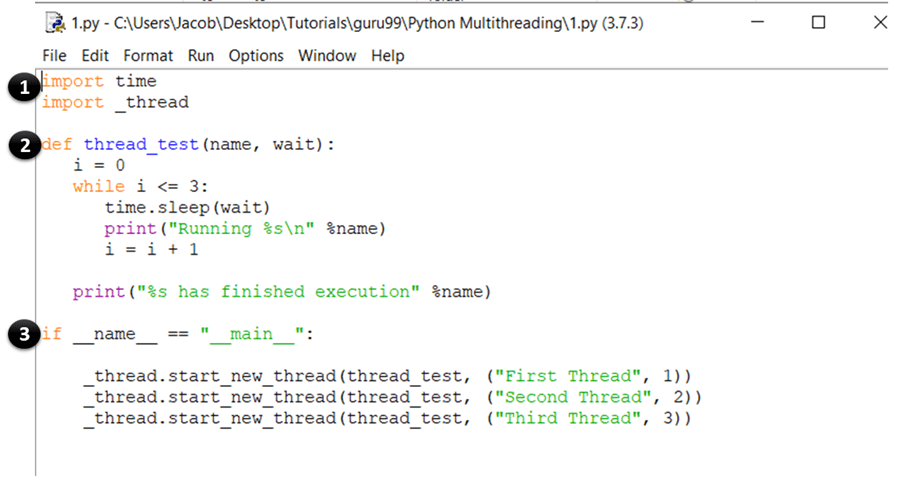
代码解释
- 这些语句导入了 time 和 thread 模块,它们用于处理 Python 线程的执行和延迟。
- 在这里,您定义了一个名为 thread_test 的函数,它将被 start_new_thread 方法调用。该函数运行一个 while 循环四次,并打印调用它的线程的名称。一旦迭代完成,它会打印一条消息,说明线程已完成执行。
- 这是您程序的主要部分。在这里,您只需将 thread_test 函数作为参数调用 start_new_thread 方法。这将为函数创建一个新线程并开始执行它。请注意,您可以将此(thread_test)替换为您想要作为线程运行的任何其他函数。
Threading 模块
这是 Python 中 threading 的高级实现,是管理多线程应用程序的事实标准。与 thread 模块相比,它提供了广泛的功能。
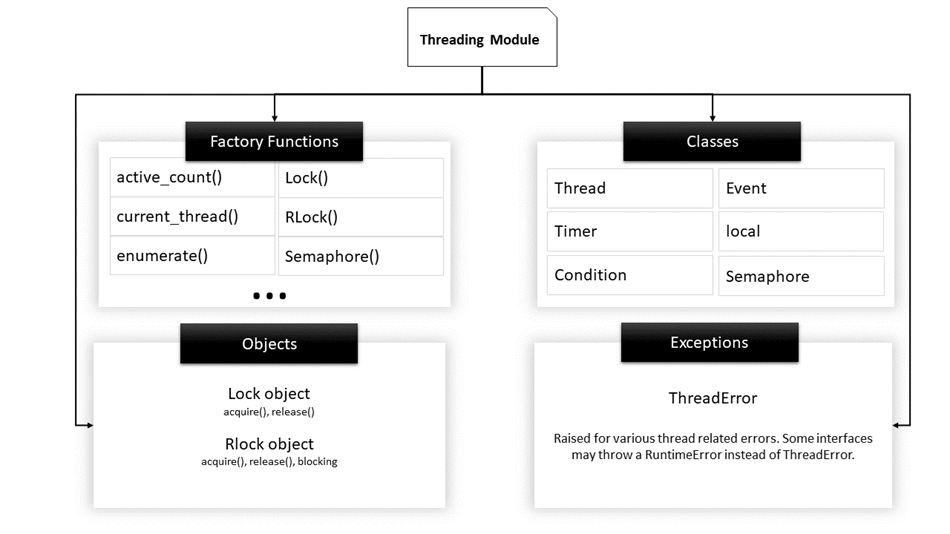
以下是此模块中定义的一些有用函数的列表:
| 函数名 | 描述 |
|---|---|
| activeCount() | 返回仍然活动的Thread对象的计数。 |
| currentThread() | 返回 Thread 类的当前对象。 |
| enumerate() | 列出所有活动的 Thread 对象。 |
| isDaemon() | 如果线程是守护线程,则返回 true。 |
| isAlive() | 如果线程仍然活动,则返回 true。 |
| Thread 类方法 | |
| start() | 启动线程的活动。对于每个线程,只能调用一次 start(),因为如果多次调用,它会引发运行时错误。 |
| run() | 此方法表示线程的活动,并且可以被扩展 Thread 类的类覆盖。 |
| join() | 它会阻塞其他代码的执行,直到调用 join() 方法的线程终止。 |
背景故事:Thread 类
在开始使用 threading 模块编写多线程程序之前,了解 Thread 类至关重要。Thread 类是定义 Python 中线程模板和操作的主要类。
创建多线程 Python 应用程序的最常见方法是声明一个扩展 Thread 类并覆盖其 run() 方法的类。
总而言之,Thread 类表示一个在线程的控制流中运行的代码序列。
因此,在编写多线程应用程序时,您将执行以下操作:
- 定义一个扩展 Thread 类的类
- 覆盖 __init__ 构造函数
- 覆盖 run() 方法
一旦创建了线程对象,就可以使用 start() 方法开始该活动的执行,并使用 join() 方法阻止所有其他代码,直到当前活动完成。
现在,让我们尝试使用 threading 模块来实现您之前的示例。再次启动您的 IDLE 并输入以下内容:
import time
import threading
class threadtester (threading.Thread):
def __init__(self, id, name, i):
threading.Thread.__init__(self)
self.id = id
self.name = name
self.i = i
def run(self):
thread_test(self.name, self.i, 5)
print ("%s has finished execution " %self.name)
def thread_test(name, wait, i):
while i:
time.sleep(wait)
print ("Running %s \n" %name)
i = i - 1
if __name__=="__main__":
thread1 = threadtester(1, "First Thread", 1)
thread2 = threadtester(2, "Second Thread", 2)
thread3 = threadtester(3, "Third Thread", 3)
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
执行上述代码时,这将是输出:
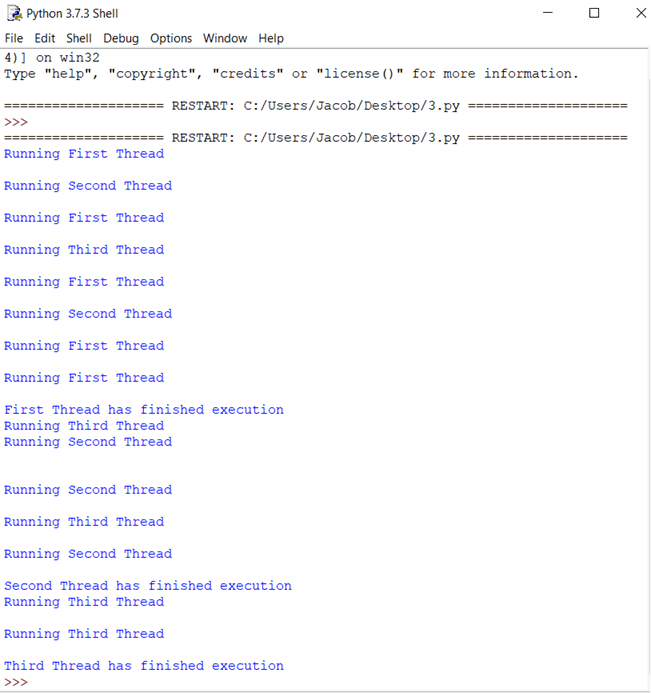
代码解释
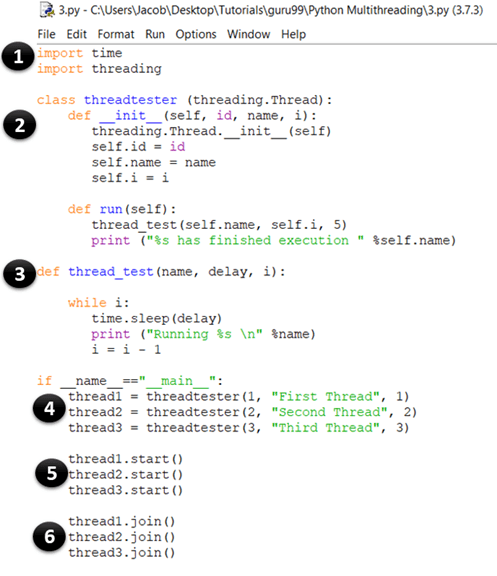
- 这部分与我们之前的示例相同。在这里,您导入 time 和 thread 模块,它们用于处理 Python 线程的执行和延迟。
- 在这里,您正在创建一个名为 threadtester 的类,该类继承或扩展了 threading 模块的 Thread 类。这是创建 Python 线程最常见的方法之一。但是,您应该只覆盖应用程序中的构造函数和 run() 方法。如上面的代码示例所示,__init__ 方法(构造函数)已被覆盖。同样,您也覆盖了 run() 方法。它包含您想在线程中执行的代码。在此示例中,您调用了 thread_test() 函数。
- 这是 thread_test() 方法,它将 i 的值作为参数,在每次迭代时减 1,并循环遍历其余代码,直到 i 变为 0。在每次迭代中,它会打印当前执行线程的名称并休眠 wait 秒(也作为参数)。
- thread1 = threadtester(1, “First Thread”, 1) 在这里,我们创建一个线程并传递我们在 __init__ 中声明的三个参数。第一个参数是线程的 ID,第二个参数是线程的名称,第三个参数是计数器,它决定 while 循环应该运行多少次。
- thread2.start()T 使用 start 方法启动线程的执行。在内部,start() 函数调用您类的 run() 方法。
- thread3.join() join() 方法会阻塞其他代码的执行,并等待被调用它的线程完成。
如您所知,同一进程中的线程可以访问该进程的内存和数据。因此,如果多个线程同时尝试更改或访问数据,可能会出现错误。
在下一节中,您将看到当线程访问数据和关键部分而未检查现有访问事务时可能出现的不同类型的并发问题。
死锁和竞态条件
在学习死锁和竞态条件之前,了解一些与并发编程相关的基本定义会很有帮助。
- 关键部分:这是访问或修改共享变量的代码片段,必须将其作为原子事务执行。
- 上下文切换:这是 CPU 在一个任务切换到另一个任务之前存储线程状态的过程,以便稍后可以从同一点恢复。
死锁
死锁是开发人员在 Python 中编写并发/多线程应用程序时面临的最令人恐惧的问题。理解死锁的最佳方法是使用经典的计算机科学示例问题,称为哲学家进餐问题。
哲学家进餐问题的陈述如下:
五位哲学家围坐在一张圆桌旁,桌上有五盘意大利面(一种意大利面)和五把叉子,如图所示。

在任何给定时间,哲学家必须要么在吃饭,要么在思考。
此外,哲学家必须在他旁边的两把叉子(即左手叉子和右手叉子)才能吃意大利面。当所有五位哲学家同时拿起他们的右手叉子时,就会发生死锁问题。
由于每位哲学家都有一把叉子,他们都会等待其他人放下叉子。结果,他们都无法吃意大利面。
同样,在并发系统中,当不同的线程或进程(哲学家)同时尝试获取共享系统资源(叉子)时,就会发生死锁。结果,没有进程有机会执行,因为它们正在等待另一个进程持有的资源。
竞态条件
竞态条件是程序中发生的非预期状态,当系统同时执行两个或多个操作时发生。例如,考虑这个简单的 for 循环:
i=0; # a global variable
for x in range(100):
print(i)
i+=1;
如果您创建n个线程同时运行此代码,则无法确定程序完成执行时 i(由线程共享)的值。这是因为在实际的多线程环境中,线程可能会重叠,并且线程检索和修改的 i 值可能会在其他线程访问它时发生更改。
这是多线程或分布式 Python 应用程序中可能出现的两类主要问题。在下一节中,您将学习如何通过同步线程来克服这个问题。
同步线程
为了处理竞态条件、死锁和其他基于线程的问题,threading 模块提供了 Lock 对象。其思想是,当一个线程需要访问特定资源时,它会获取该资源的锁。一旦一个线程锁定了某个特定资源,任何其他线程都无法访问它,直到锁被释放。结果,对资源的更改将是原子的,并且会避免竞态条件。
锁是 __thread 模块实现的一个低级同步原语。在任何给定时间,锁都可以处于两种状态之一:locked(已锁定)或unlocked(未锁定)。它支持两种方法:
- acquire():当锁状态为 unlocked(未锁定)时,调用 acquire() 方法会将状态更改为 locked(已锁定)并返回。但是,如果状态为 locked(已锁定),则对 acquire() 的调用将被阻塞,直到其他线程调用 release() 方法。
- release():release() 方法用于将状态设置为 unlocked(未锁定),即释放锁。任何线程都可以调用它,不一定是获取锁的线程。
以下是如何在您的应用程序中使用锁的示例。启动您的 IDLE 并输入以下内容:
import threading
lock = threading.Lock()
def first_function():
for i in range(5):
lock.acquire()
print ('lock acquired')
print ('Executing the first funcion')
lock.release()
def second_function():
for i in range(5):
lock.acquire()
print ('lock acquired')
print ('Executing the second funcion')
lock.release()
if __name__=="__main__":
thread_one = threading.Thread(target=first_function)
thread_two = threading.Thread(target=second_function)
thread_one.start()
thread_two.start()
thread_one.join()
thread_two.join()
现在,按 F5。您应该会看到类似以下的输出:
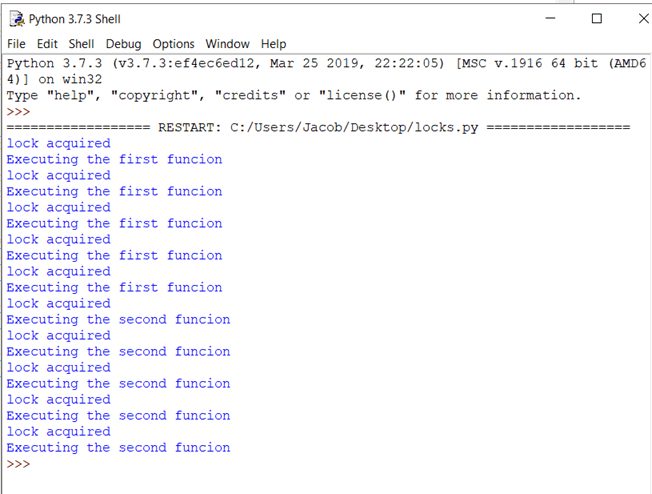
代码解释
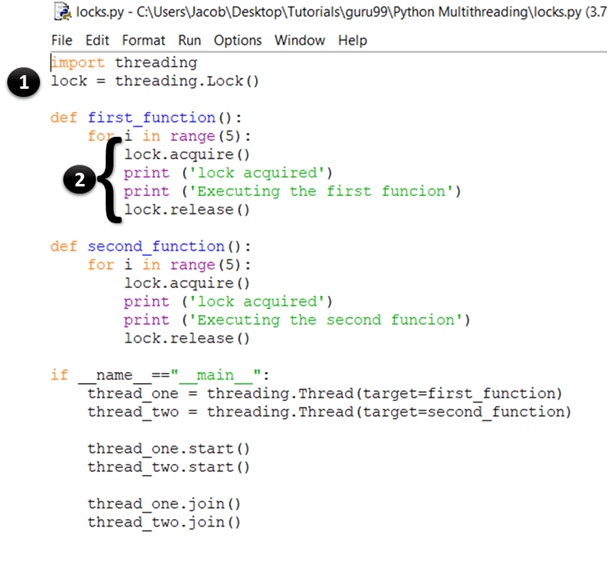
- 在这里,您通过调用 threading.Lock() 工厂函数来创建一个新锁。在内部,Lock() 返回由平台维护的最有效的具体 Lock 类的实例。
- 在第一个语句中,您通过调用 acquire() 方法来获取锁。当授予锁后,您向控制台打印“lock acquired”。一旦您希望线程运行的所有代码完成执行,您就通过调用 release() 方法来释放锁。
理论是好的,但您如何知道锁真的起作用了?如果您查看输出,您会发现每个 print 语句一次只打印一行。回想一下,在之前的示例中,print 输出是杂乱的,因为多个线程同时访问 print() 方法。在这里,print 函数仅在获取锁后调用。因此,输出一次显示一行,逐行显示。
除了锁之外,Python 还支持一些其他机制来处理线程同步,如下所示:
- RLocks
- Semaphores(信号量)
- 条件
- Events(事件),以及
- Barriers(屏障)
全局解释器锁(以及如何处理它)
在深入了解 Python GIL 的细节之前,让我们定义一些有助于理解后续部分的术语:
- CPU 密集型代码:这指的是将由 CPU 直接执行的任何代码片段。
- I/O 密集型代码:这可以是任何通过 OS 访问文件系统的代码。
- CPython:它是 Python 的参考实现,可以描述为用 C 和 Python(编程语言)编写的解释器。
Python 中的 GIL 是什么?
Python 中的全局解释器锁 (GIL) 是一个进程锁或互斥锁,在处理进程时使用。它确保一次只有一个线程可以访问特定资源,并且它还阻止同时使用对象和字节码。这有利于单线程程序的性能提升。Python 中的 GIL 非常简单易于实现。
可以使用锁来确保在给定时间只有一个线程可以访问特定资源。
Python 的一个特性是它在每个解释器进程上都使用全局锁,这意味着每个进程都将 Python 解释器本身视为一个资源。
例如,假设您编写了一个使用两个线程执行 CPU 和 'I/O' 操作的 Python 程序。当您执行此程序时,会发生以下情况:
- Python 解释器创建一个新进程并生成线程。
- 当 thread-1 开始运行时,它将首先获取 GIL 并锁定它。
- 如果 thread-2 现在想要执行,即使另一个处理器是空闲的,它也必须等待 GIL 被释放。
- 现在,假设 thread-1 正在等待 I/O 操作。此时,它将释放 GIL,thread-2 将获取它。
- 完成 I/O 操作后,如果 thread-1 现在想要执行,它将不得不再次等待 thread-2 释放 GIL。
因此,一次只有一个线程可以访问解释器,这意味着在任何给定时间点都只有一个线程在执行 Python 代码。
这在单核处理器中是可以的,因为它会使用时间切片(参见本教程的第一部分)来处理线程。然而,在多核处理器的情况下,在多个线程上执行的 CPU 密集型函数将对程序的效率产生重大影响,因为它实际上不会同时使用所有可用的核心。
为什么需要 GIL?
CPython 的垃圾回收器使用一种称为引用计数的有效内存管理技术。它的工作原理如下:Python 中的每个对象都有一个引用计数,当它被赋给新变量名或添加到容器(如元组、列表等)时,引用计数会增加。同样,当引用超出范围或调用 del 语句时,引用计数会减少。当对象的引用计数达到 0 时,它会被垃圾回收,分配的内存将被释放。
但是问题在于,引用计数变量与其他全局变量一样,容易发生竞态条件。为了解决这个问题,Python 的开发者决定使用全局解释器锁。另一个选择是向每个对象添加一个锁,这会导致死锁并增加 acquire() 和 release() 调用带来的开销。
因此,GIL 是多线程 Python 程序运行繁重 CPU 密集型操作(有效地将其视为单线程)的一个重大限制。如果您想在应用程序中使用多个 CPU 核心,请改用multiprocessing 模块。
摘要
- Python 支持两个用于多线程的模块:
- __thread 模块:它提供了一种低级的线程实现,并且已过时。
- threading 模块:它提供了一种高级的多线程实现,并且是当前的标准。
- 要使用 threading 模块创建线程,您必须执行以下操作:
- 创建一个扩展 Thread 类的类。
- 覆盖其构造函数 (__init__)。
- 覆盖其 run() 方法。
- 创建该类的对象。
- 可以通过调用 start() 方法来执行线程。
- 可以使用 join() 方法来阻止其他线程,直到此线程(在其上调用 join 的线程)完成执行。
- 当多个线程同时访问或修改共享资源时,就会发生竞态条件。
- 可以通过同步线程来避免这种情况。
- Python 支持 6 种同步线程的方法:
- Locks(锁)
- RLocks
- Semaphores(信号量)
- 条件
- Events(事件),以及
- Barriers(屏障)
- 锁只允许已获取锁的特定线程进入关键部分。
- Lock 具有 2 个主要方法:
- acquire():它将锁状态设置为locked。如果在一个已锁定的对象上调用,它将阻塞直到资源可用。
- release():它将锁状态设置为unlocked并返回。如果在一个未锁定的对象上调用,它返回 false。
- 全局解释器锁是一种机制,通过该机制,一次只有一个 CPython 解释器进程可以执行。
- 它用于促进 CPython 的垃圾收集器的引用计数功能。
- 要创建具有重度 CPU 密集型操作的 Python 应用程序,您应该使用 multiprocessing 模块。